
TL;DR:
In our recent work with Professor Michael Graziano (arXiv, thread), we show that adding an auxiliary self-modeling objective to supervised learning tasks yields simpler, more regularized, and more parameter-efficient models.
Across three classification tasks and two modalities, self-modeling consistently reduced complexity (lower RLCT, narrower weight distribution). This restructuring effect may help explain the putative benefits of self-models in both ML and biological systems.
Agents who self-model may be reparameterized to better predict themselves, predict others, and be predicted by others. Accordingly, we believe that further exploring the potential effects of self-modeling on cooperation emerges as a promising neglected approach to alignment. This approach may also exhibit a ‘negative alignment tax‘ to the degree that it may end up enhancing alignment and rendering systems more globally effective.
Introduction
In this post, we discuss some of the core findings and implications of our recent paper, Unexpected Benefits of Self-Modeling in Neural Systems.
This work represents further progress in our exploration of neglected approaches to alignment—in this case, implementing a promising hypothesis from the neuroscience of attention and cooperation in an ML context and observing its effects on model behavior.
The specific model we operationalize here is Attention Schema Theory (AST), a mechanistic account of consciousness which posits that, akin to how brains utilize a schema of the body, they also maintain an internal model of their own attention processes. Critically, this self-model is hypothesized to subsequently help enable metacognition and social cognition, which motivates us to pursue it as an alignment research direction.
We are very interested in better understanding the relationship between alignment, consciousness, and prosociality, and we see AST as a concrete method for exploring these intersections further. It is worth noting at the outset that we are also concerned about AI moral patienthood and are attempting to balance the potential prosociality benefits of embedding consciousness-like processes into ML training against the potential s- and x-risks of building AI systems that are plausibly conscious. Overall, we still believe that we need more AI consciousness research and that this investigation is one such example of this broader direction.
Before meaningfully pursuing or publicizing this research agenda, we spent a lot of time discussing this concern with others, and we concluded that proactively studying consciousness in smaller models is preferable on balance to allowing it to emerge unpredictably in larger systems, where it will likely pose greater x-risks and raise more complex moral patienthood concerns.
Accordingly, we ask in this experiment: what happens if we implement AST-inspired self-modeling for neural networks by incentivizing them to model their own internal states during the training process?
Implementing self-modeling across diverse classification tasks
We designed classification experiments with an auxiliary self-modeling objective across three simple datasets:
1. MNIST, the classic handwritten digit recognition task.
2. CIFAR-10, a more complex object classification task.
3. IMDB, a natural language sentiment analysis task.
For each task, we compared baseline neural networks to variants that included the auxiliary self-modeling task, which we operationalized as predicting their own internal activations. This approach allowed us to explore how self-modeling affected networks across different architectures and modalities. We also tracked how the relative importance of the self-modeling task changed overall performance and model complexity.
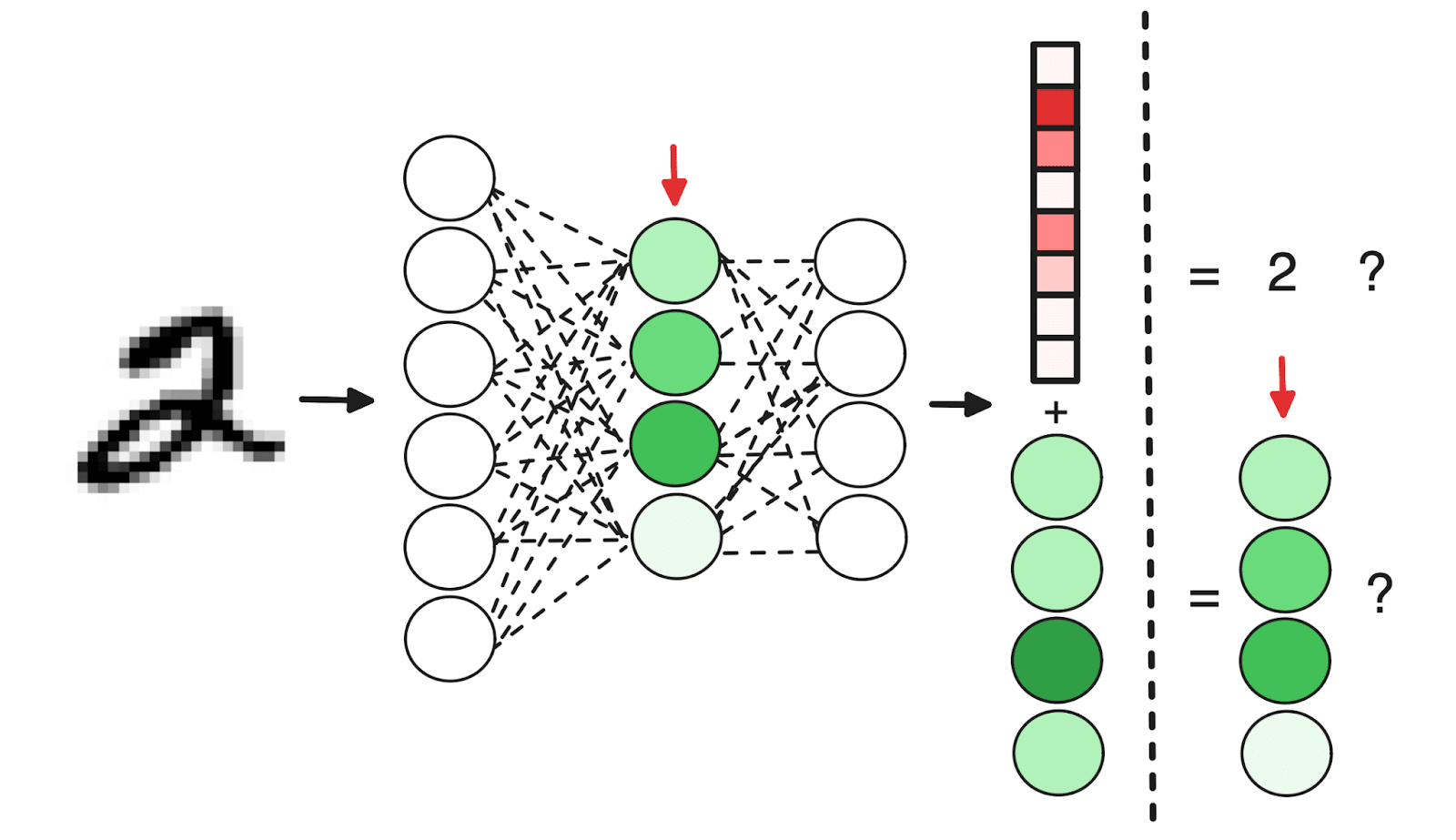
How we measured network complexity
We hypothesized that by predicting internal activations, the network could learn to make those activations easier to predict and therefore potentially less complex. Accordingly, we measured network complexity (with and without self-modeling) using the following methods:
- The magnitude of the distribution of weights in the final layer, which gives us insight into how the network is using its parameters.
- A narrower distribution suggests more weights are close to zero, indicating a sparser, potentially simpler network. Inducing smaller weight magnitudes is a typical regularization technique used to make ML systems better at generalizing.
- We reasoned that if self-modeling results in this same outcome, we can conclude that it is providing a similar simplification benefit.
- The Real Log Canonical Threshold (RLCT) or Local Learning Coefficient.
- This is a well-founded measure derived from algebraic geometry which finds its relevance to deep learning through Singular Learning Theory.
- It provides a measure of the learned model’s degeneracy, affording a more nuanced view of model complexity.
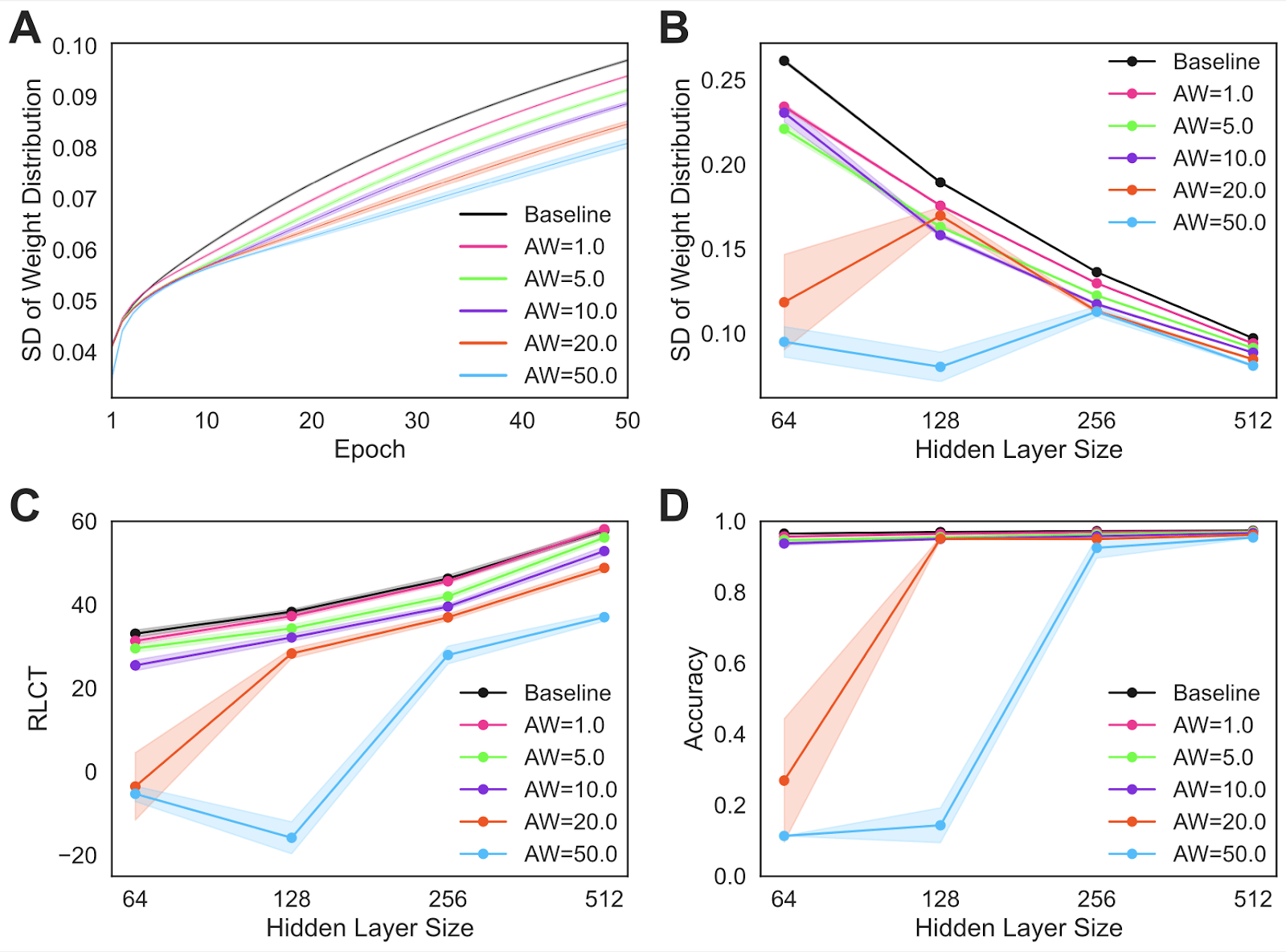
Key result
Across three different classification tasks, we consistently found that adding a self-modeling mechanism to neural networks significantly reduced their complexity (see paper for additional details). This reduction in complexity was observed through both of the two measures described above, which suggests that the auxiliary self-modeling task is fundamentally simplifying the networks.
Importantly, we find that the reduction in complexity scales with the weight placed on the auxiliary self-modeling task without significantly affecting task performance.
Relevance of self-modeling to alignment
We propose that networks that learn to self-model become not only better at predicting their own states but also become more amenable to being modeled by other agents (including human overseers and other AI agents), which could significantly enhance cooperation and coordination.
Additionally, the observed reduction in network complexity can also be viewed as a form of self-regularization.[1] For alignment, this implies that encouraging AI systems to model themselves might naturally lead to more robust and generalizable models, potentially reducing unintended behaviors or spurious effects. Intuitively, simpler models may also become more interpretable.
Adding an auxiliary self-modeling objective to models has low interpretability requirements, does not seem to negatively impact model capabilities, and is highly scalable in theory. If the desirable properties of self-modeling that we uncovered in this experiment scale to more complex models, this method could prove to be a promising piece of the hodge-podge alignment puzzle.
Challenges, considerations, and next steps
In our exploration of self-modeling in neural systems, we’ve encountered several challenges and potential weaknesses that warrant careful consideration.
- Although we believe that self-modeling primarily addresses alignment issues, we’re acutely aware of the possibility that it could inadvertently boost an AI system’s capabilities in ways that might pose risks (e.g., heightened self-awareness leading the system to more competently manipulate users).
- We are attempting to implement AST here, which is a mechanistic theory of consciousness. If this self-modeling implementation has the potential to cause a sufficiently complex model to have some level of consciousness, there are critical moral patienthood concerns here that would need to be addressed. If consciousness leads to both heightened prosociality and moral patienthood, a more rigorous framework for weighing these costs and benefits would be required.
- Given that our experiments employ small networks on simple classification tasks, the extent to which this method scales to larger models, more complex contexts, and more agentic set-ups (eg, multiagent RL) is not yet clear.
These early experiments in self-modeling neural networks have revealed a promising avenue for developing more cooperative and predictable models. This dual benefit of improved internal structure and increased external predictability could be a significant step towards creating AI systems that are naturally more cooperative.
We are excited to continue pushing this neglected approach forward and are highly open to feedback and ideas from the wider community about what additional related directions would be most promising to pursue in this space.
Appendix: Interpreting Experimental Outcomes
After releasing our paper, we received a positive response from the community, along with several insightful questions and ideas. We thought it would be valuable to address some of these points here.
Does the Network Simply Learn the Identity Function?
One common question is whether the self-modeling task, which involves predicting a layer’s own activations, would cause the network to merely learn the identity function. Intuitively, this might seem like an optimal outcome for minimizing the self-modeling loss.
Our findings show that this is not the case. While the linear layer does tend towards the identity transformation, it typically converges to a function that is strictly non-identity, balancing both the primary task and the self-modeling objective. This behavior is supported by our observations where the difference between the weight matrix 𝑊 and the identity matrix 𝐼, denoted as 𝑊−𝐼, does not approach zero over training.
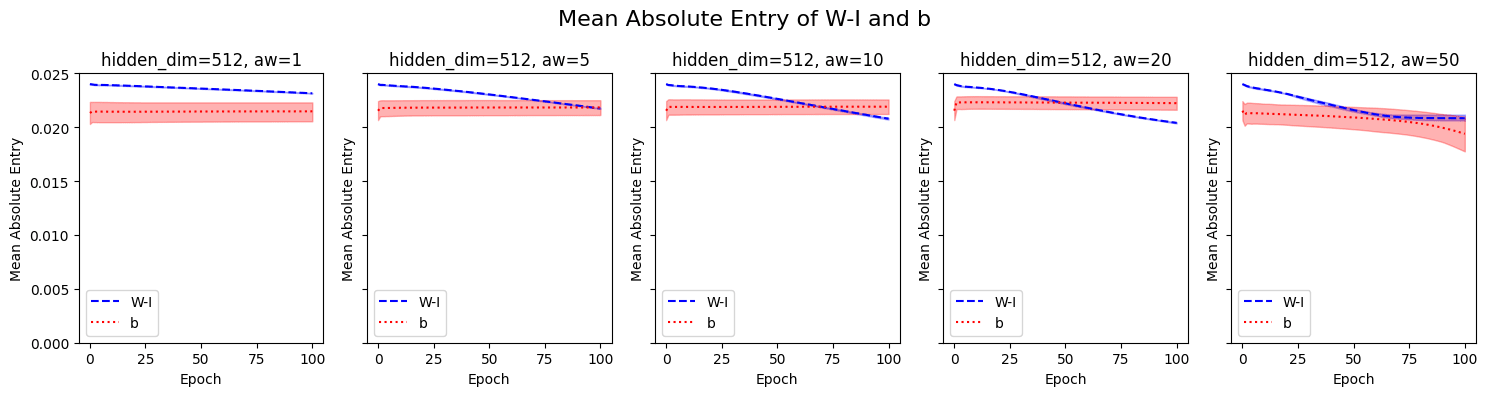
We observed similar effects when applying self-modeling to earlier layers, where the benefits persisted, further supporting the unique regularization introduced by self-modeling.
These results imply that self-modeling encourages the network to adjust its internal representations in a way that balances self-prediction with task performance, leading to reduced complexity without resorting to a trivial solution.
How Does Self-Modeling Differ from Traditional Regularization?
Another point of discussion centered around the nature of self-modeling as a regularizer. While techniques like weight decay are well-understood forms of regularization that encourage simpler models, self-modeling introduces a different kind of constraint.
Self-modeling appears to be qualitatively different from traditional regularization methods like weight decay. To better understand this, we can derive the gradients for the self-modeling loss and compare them to those of weight decay.
Consider a linear layer with weights and input activations. The self-modeling loss using Mean Squared Error (MSE) is given by:
Assuming zero bias () for simplicity, the gradient with respect to is:
Let represent the deviation from the identity matrix. Substituting, we get:
This gradient depends on both and the covariance of the activations , introducing a data-dependent adjustment.
In contrast, the weight decay (or regularization) loss is:
The gradient with respect to is:
This gradient scales the weights directly, independent of the data.
Unlike weight decay, the self-modeling gradient is influenced by the input data through . This means that the regularization effect of self-modeling adapts based on the structure and distribution of the input data.
- ^
See appendix for more details.
Source link
#Selfprediction #acts #emergent #regularizer #Alignment #Forum
Unlock the potential of cutting-edge AI solutions with our comprehensive offerings. As a leading provider in the AI landscape, we harness the power of artificial intelligence to revolutionize industries. From machine learning and data analytics to natural language processing and computer vision, our AI solutions are designed to enhance efficiency and drive innovation. Explore the limitless possibilities of AI-driven insights and automation that propel your business forward. With a commitment to staying at the forefront of the rapidly evolving AI market, we deliver tailored solutions that meet your specific needs. Join us on the forefront of technological advancement, and let AI redefine the way you operate and succeed in a competitive landscape. Embrace the future with AI excellence, where possibilities are limitless, and competition is surpassed.








