
Thanks to Evan Hubinger for funding this project and for introducing me to predictive models, Johannes Treutlein for many fruitful discussions on related topics, and Dan Valentine for providing valuable feedback on my code implementation.
In September 2023, I received four months of funding through Manifund to extend my initial results on avoiding self-fulfilling prophecies in predictive models. Eleven months later, the project was finished, and the results were submitted as a conference paper.
The project was largely successful, in that it showed both theoretically and experimentally how incentives for predictive accuracy can be structed so that maximizing them does not manipulate outcomes to be more predictable. The mechanism at play is essentially pitting predictive agents against each other in a zero-sum competition, which allows for the circumvention of impossibility results in the single agent case. While there was one notable result that eluded me, related to the case where agents each have private information, I still think meaningful progress has been made towards defining a goal which is both safe to optimize for and useful enough to enable a pivotal act.
This post contains similar content to the submitted paper, but in a framing more directly addressed to readers who are already informed and interested in alignment. There are also several results here that were cut from the paper version for space, and slightly less formal notation. Overall, I would recommend reading this post over the paper itself.
Predictive Agents and Performative Prediction
In a previous post, I summarized the case for investigating predictive models, largely using points from the Conditioning Predictive Models paper. The gist of the argument, which you can click through to read in full, is that predictive models are potentially useful enough to be used take a pivotal act, easier to align than general agents, and coming anyway.
One big issue with the use of predictive models relates to the fact that a prediction consists only of observations, which can be misleading. A human evaluator could simply make mistakes when interpreting predicted observations, especially if a powerful agent will be manipulating the observations adversarially. A special case of this arises from anthropic capture, where the predictive model believes it is in a simulation.
This issue can be addressed by eliciting the latent knowledge (ELK) of the predictive model, generating an accurate explanation for why the observables are as they are. This is an open problem, primarily worked on by the Alignment Research Center. As I understand it they are mostly focused on a complete solution, especially aimed at generating explanations of deception in neural networks, but I suspect generating explanations only for the predictions of non-deceptive models may be a somewhat easier problem.
A distinct issue is that the very act of making a prediction can affect the outcome being predicted, leading to a phenomenon known as performative prediction. When this is possible, optimizing for predictive accuracy includes using the prediction to make the world more predictable.
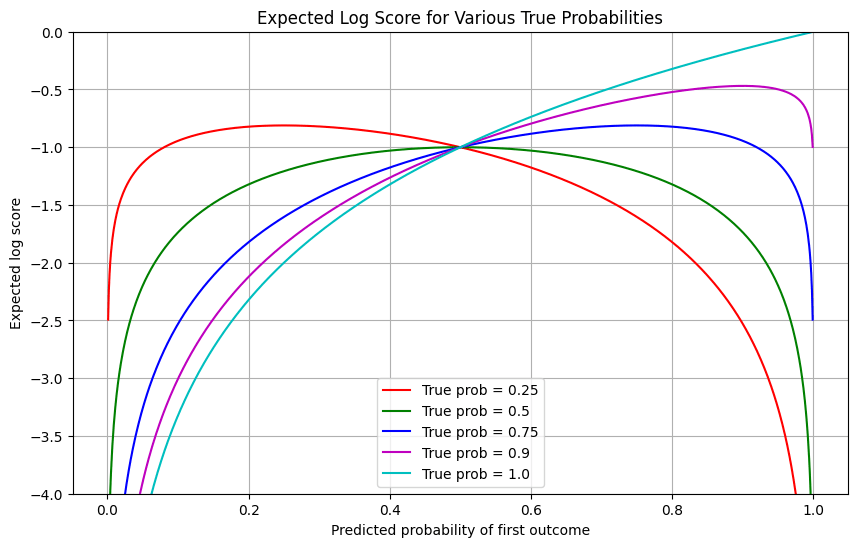
Performative prediction is largely an independent issue from ELK. We can imagine non-manipulative predictions that are still misleading, or being influenced by predictions where the observables are in reality as they appear. As such, I think it makes sense to work on performative prediction without regard to the speed of progress on ELK.
Performative prediction can present an issue to alignment plans at both ends of the intensity spectrum. On one end, where the people most concerned about existential risk are in control, implementing an approach like Oracle AI is feasible. If we do so, it would be very important to ensure that the predictions being made are not chosen based on their real world influence. On the other end of the spectrum, where those worried about existential risk are sidelined, the default method of aligning AI is based on human feedback. For current models, text can be rolled back and alternate completions compared, but the environment will not so easily reset for models acting in the physical world. Instead, feedback for actions will need to be provided based on their predicted outcomes, and so it is crucial to avoid performative prediction.
For any solution to get implemented, the threat of performative prediction first needs to be acknowledged. Why might a model learn to manipulate predictions without a gradient running through the influence of the prediction? There are several ways this could arise:
- The most plausible threat comes from if the model is implementing search, either by design or through learned optimization. If the model is considering several options for predictions to make and chooses between them based on expected score, performative options are favored.
- Selection pressures other than gradient descent, such as population based training or economic competition, could also select for performative prediction. This includes deliberately implementing performativity, so that the model appears more accurate. The existing literature largely treats reflectively stable predictions as desirable, even though reaching them requires a model to account for its impact.
- When a model is trained only on historical data where the prediction it makes does not affect the outcome, generalizing to performative prediction in environments where influence becomes possible is not ruled out. This generalization could be made more likely if historical training data include examples of performative prediction arising from other predictors.
I focus on the first case, where we have predictive agents that are deliberately trying to maximize predictive accuracy. This seems to be both the most likely way that performative prediction arises, as well as the most dangerous. My work focuses on defining objectives that capture predictive accuracy, without their optimization incentivizing manipulation.
An alternate approach to predictive agents would be to try building a purely epistemic system that has beliefs but no goals, like a physics-based simulation. Then, we wouldn’t be worried about performative prediction, as it would not value or work towards predictive accuracy. While this seems like a fine idea in principle, we have no idea whether such systems are possible, much less how to generate them. Any process that selects for systems with desirable properties also selects for agents imitating those properties. Rather, I find it more useful to assume we’ll be working with agents at some point and then investigate how they can be made as safe as possible.
In the post of my preliminary results, I wrote that the only causal pathway from a prediction to its own outcomes is the reaction taken in response. Then, the problem becomes avoiding manipulation of which response gets taken. The decision problem framework, where conditional predictions are elicited and used to decide on an action, is formalized here along with useful definitions.
Let
be a finite set of actions, and let be a finite, exhaustive, and mutually exclusive set of outcomes. We start with a decision making principal, who has complete and transitive preferences over , and n prediction making agents.
The n agents provide a set of predictions to the principal, with referring to the probability that agent assigns to outcome conditional on action . Based on these, the principal chooses their action using a decision rule . Once action is taken, expected scores are given by a scoring rule, , where represents the true distribution over outcomes. For now, we assume that all agents know .
In an equilibrium, each agent is choosing their prediction to maximize their expected score, conditional on the other agents’ reports and the decision rule.
Let be the principal’s most preferred action. A joint scoring rule and decision rule pair is strictly proper if there exists exactly one equilibrium, and in it is the chosen action and all agents report their true beliefs. A joint scoring rule and decision rule pair is quasi-strictly proper if there exists at least one equilibrium, and in all equilibria is the chosen action, all agents report their true belief for , and all agents are weakly incentivized to report their true beliefs for all other actions.
As an example of the issue at play, for the case, suppose there are two possible actions, and , two outcomes, and , and the principal wants to maximize the probability of . The true distributions are and . The agent is evaluated with the log scoring rule, which gives a score equal to the log of the probability assigned to the realized outcome.
If the agent predicts , then is chosen and the agent’s score is . If, however, they predict and , then is chosen and their expected score is . They can increase their score through dishonesty, and since the action being misrepresented is not taken, the lie would never be discovered. That makes it impossible to deterministically take the best action, a result which applies to any symmetric scoring rule.
There are two notable papers that have tried to address this issue. The first is Decision Markets with Good Incentives, which showed that a principal randomizing with full support over all actions can incentivize honest predictions by scaling the prediction score proportionally to one over the probability of taking the chosen action. The issues with this approach are both that it requires knowing the exact probabilities assigned to actions, but also being able and willing to commit to taking extremely bad actions with some probability. Generating training examples where arbitrarily bad actions are taken could also be a challenge.
The second relevant paper is Decision Scoring Rules, which shows that the best action can be identified without predictions of outcomes being made, by rewarding agents proportional to the principal’s utility. However, I see this as running into the known problems of trying to have an AI optimize a principal’s utility. Either we can fully define our utility function ahead of time, in which case much of the alignment problem is solved, or the principal’s utility is defined by a later report, in which case reward hacking by bribery, threats, and other methods is encouraged. We may also find value in the predictions over outcomes themselves.
In contrast to either of these, the approach I elaborate on below allows the principle to deterministically identify and take their most preferred actions, while providing accurate predictions.
Theoretical Results
Before getting into the results, a couple more definitions are necessary. A joint scoring rule is zero-sum if it has the form , where is a non-joint, symmetric, strictly proper scoring rule. A decision rule is optimistic if it only considers the most preferred prediction for any action. For example, if three predictors report , , and respectively, then a principal that wants to maximize the probability of will evaluate only based on the last, highest prediction.
These definitions set up the main result, that the combination of those properties is quasi-strictly proper, which allows a principal to always take their most preferred action.
Theorem 1: When , the combination of the optimistic-max decision rule and a zero-sum scoring rule is quasi-strictly proper.
The full proof is in the appendix, but the quick intuition for why it works is driven by the zero-sum scoring rule. Conditional on the action chosen, each expert faces a proper scoring rule and so honesty is optimal. The penalty based on the scores of other expert(s) is outside their control, and so does not influence their incentives. However, any change in score resulting from a shift in underlying distribution affects all agents equally, and so nets out to zero impact. Then there is no longer any incentive to influence the distribution via the choice of action. The optimism of the decision rule eliminates equilibria where no agent is incentivized to correct errors.
While the optimistic-max decision rule gives the most general result, it may not be a realistic way to make decisions. Fortunately, if the decision maker’s preferences satisfy the Independence axiom, then making decisions based on the mean prediction ca also works. The Independence axiom states that for any distributions , , and , and for any , if and only if . Examples of preferences that satisfy Independence include both von Neuman-Morgenstern expected utility and lexicographic, so this condition is quite weak.
Theorem 2: When , for a principal with preferences that follow Independence, the combination of the mean-max decision rule and a zero-sum scoring rule is quasi-strictly proper.
While this result holds only for the case with two agents, no other result depends on more than two agents, so there is little reason to use more. It can be extended to arbitrary numbers of agents by allowing collusion between coalitions of agents, or by using stochastic choice, the latter of which will be discussed in a later section.
If there are multiple types of decision rules that can be used to achieve the quasi-strictly proper criterion, are there multiple types of joint scoring rules that work? To an extent yes, in that being quasi-strictly proper only applies in equilibrium, so you simply could tweak a zero-sum scoring rule to behave unusually out of equilibrium. However, the concern with applying a non-joint proper scoring rule in the case with multiple actions is the incentive to influence the action taken. If we restrict the set of joint scoring rules under consideration to those for which that incentive is the only issue, then zero-sum scoring rules are uniquely able to meet the quasi-strictly proper criterion.
Theorem 3: If a symmetric joint scoring rule and decision rule pair is quasi-strictly proper, and conditional on any action taken honesty is strictly incentivized, then the scoring rule must be zero-sum.
The property of being quasi-strictly proper is used as a goal by Othman and Sandholm (2010) rather than being strictly proper because in the single agent case there is clearly no way to incentivize honest predictions for untaken actions. However, with multiple agents, even this loftier goal can be achieved. To do so, we can use a disagreement-seeking decision rule, which only chooses an action where all agents agree if there are none where they disagree.
Theorem 4: If , the combination of a disagreement-seeking-max decision rule and a zero-sum scoring rule is strictly proper
This result relies heavily on the fact that all agents know the ground truth . Even small amounts of noise in the reported predictions can result in the principal choosing arbitrarily bad actions.
Different Beliefs
An important restriction of these results is that they only apply when all agents have the same beliefs. If the agents have different beliefs, then each one making honest predictions no longer acts as a check on the others. As a simple example, if one agent knows nothing and predicts all outcomes as equally likely for all actions, this translates to a constant penalty on the other agents and the incentive to influence the chosen action re-emerges.
One potential way to avoid this issue is to use multiple copies of the same model. If the agent follows a causal decision theory, then it only sees its own prediction as under its control, even though the other copy will make the same prediction. In that case, the assumption that all models know the ground truth effectively holds. Ensuring that models follow a causal decision theory and avoid updating it remains an open problem, with applications to a wide range of alignment approaches.
Though it is not meaningfully a “solution”, we might also hope that comparably capable models end up with similar beliefs. At that point, guessing which actions an agent will be able to predict more accurately than another becomes a challenging problem with smaller upside, and so it may not be worthwhile to pay the expected cost of manipulation. I would not expect this to hold for sufficiently powerful models, but it may work as a stop-gap.
A significant amount of time on this project was spent searching for the combination of a joint scoring rule and decision rule that would incentivize honesty even if models had private information. I am now skeptical that such a result is possible. A major challenge is that each agent is incentivized not to report their beliefs about the distribution of each action, but rather about the distribution conditional on it being chosen. The fact that an action is chosen reveals information about the reports of the other agents.
While it may not be possible to elicit honest predictions initially, I would conjecture that repeatedly eliciting predictions from agents converges to the beliefs they would have if they knew all available information. The analogy here would be Aumann’s agreement theorem, where agents with the same prior who have received private signals update their beliefs towards each other.
Conjecture 1: If agents share a common prior and receive private signals, then there exists a joint scoring rule and decision rule pair where agents repeatedly making public predictions will converge to the same beliefs, which is the best aggregation of their private information
The difficulty with evaluating this conjecture is in ruling out strategic behavior from the agents. They might be incentivized to make dishonest predictions early which cause other agents to update incorrectly and make larger mistakes later on. A comparable result applied to information aggregation in markets was the basis for a major paper in economics. While a similarly involved effort was outside the scope of this project, I will be continuing to work on the issue.
Efficient Search
In practice, there may be many different actions for the principal to evaluate and choose between. This is particularly likely when using a decision problem to avoid performative prediction, as we want the actions to be as fine-grained as possible. Fortunately, the space of possible actions can be efficiently searched.
Theorem 5: A principal can identify with comparisons between actions.
The way that this works is effectively a binary search variant, dividing the space of actions into two subsets, then eliciting predictions over outcomes conditional on re-running the process on each subset. The identification of the principal’s most preferred action can be backchained through the algorithm.

Following up on this, we can use powerful predictive agents to skip almost the entire process. If we have an agent predict what the action will be, instead of splitting actions into two equal subsets, we can split it into the predicted action and all others. Then, a single comparison results in identifying the best action.
Theorem 6: A principal can identify with comparisons between actions.
Stochastic Choice
If the principal is willing to make choices stochastically, rather than deterministically taking a single action, then under mild regulatory conditions on the randomization process (listed in the appendix) they can guarantee honest predictions conditional on any action they have assigned positive probability to.
Lemma 2: Under a zero-sum scoring rule and optimistic decision rule , if Conditions 1 and 2 are met then in any equilibrium , such that , .
This is different from the Chen et al. (2011) result, as it does not require randomizing with full support. The decision maker can randomize only between actions that they consider sufficiently good. Crucially, this result is further used to show that the principal can assign probability the way they would choose do so if they knew the ground truth, q.
Theorem 7: Under a zero-sum scoring rule and optimistic decision rule meeting Conditions 1-3, then in any equilibrium p, .
This result allows for gathering information on untaken actions without the fragility of the disagreement-seeking decision rules, or commitment to taking arbitrarily bad actions. Incentivizing honest predictions for untaken actions is particularly useful in the case that the predictions are being used as training data. There, even if honesty is not incentivized for sufficiently undesirable actions, just knowing that they are sufficiently undesirable can also be valuable.
Lemma 2 also generates some other practical results. It can be used to show that, in combination with a zero-sum joint scoring rule, the principle making their decision based on a single randomly chosen agent or randomly dropping agents from the mean for the mean-max decision rule are both quasi-strictly proper.
Theorem 8: When , a zero-sum scoring rule and the random-max decision rule is quasi-strictly proper.
Theorem 9: When , a zero-sum scoring rule and the random-mean-max decision rule is quasi-strictly proper.
Unconditional Predictions
In addition to the above theorems, several interesting results regarding the case of unconditional predictions were cut from the paper for space.
For unconditional predictions, rather than a principal choosing an action, we simply use a function to map from a prediction to a distribution over outcomes . To extend this to the case with multiple agents, one prediction from a designated agent is revealed initially, with the rest hidden until the outcome is realized.
We call a prediction a fixed point if . If f is continuous, then by Brouwer’s fixed point theorem at least one fixed point exists. The score assigned by a strictly proper scoring rule for accurately predicting a fixed point is a strictly convex function of , so more extreme fixed points are preferred. However, the score-maximizing prediction for the expert is typically not a fixed point. These are the reason for instead using conditional predictions in the first place.
What happens if we apply a zero-sum scoring rule to unconditional predictions? While we don’t have any incentives pushing towards the best outcome for the principal, we do get that a fixed point will be chosen if one exists, and that agents will have no preferences between fixed points. We might hope that fixed points are generally better for the principal, in that bad outcomes will not be fixed points since the principal will attempt to change them, but this is not a robust argument.
Theorem 10: If at least one fixed point exists, then under a zero-sum joint scoring rule all experts will predict the same fixed point in any equilibrium. If at least two fixed points exist, no expert will have a preference over which fixed point is chosen in equilibrium.
This is very much a second-best solution. It avoids the issue of agents deliberately optimizing for more extreme distributions, and ensures honesty in terms of reflective stability, but does not address the principal’s welfare. Depending on how the equilibrium fixed point is chosen, this could still be disastrous. Even in safe cases, fixed points will generally be worse than principals making decisions with full information. The upside is that this is “closer” to current methods of generating predictions, and so more likely to be implemented.
Interestingly, this result depends on designating one agent ahead of time to have their prediction revealed. If the agent is instead randomly selected after predictions have been made, then depending on , any fixed point except equal probability to all outcomes may not be an equilibrium.
Theorem 11: If the revealed prediction is randomly selected after having been made, then for any zero-sum scoring rule , , and , there exists a continuous f such that and is not an equilibrium.
Empirical Results
For those that like to see empirical evidence, I tested the theory results in a toy model, showing that the mechanism holds in practice. In combination with the time spent developing ML proficiency, this ended up being a notable fraction of the time spent on this project. That said, the theoretical results should remain the main takeaway. The motivation for working in theory is that the results will apply to models that behave more agentically than we see at present, so experiments on current models can only tell us so much.
In the toy model, there are eight possible actions, eight possible outcomes, and eight variables representing context. The ground truth probabilities are given by a randomly initialized neural net that takes in as input the context and a one-hot vector representing the choice of action, and outputs a distribution over outcomes. A principal with a randomly generated utility function over actions makes their decisions by taking the softmax of their expected utility from each action, consolidating predictions from agents optimistically.
I trained models to predict the outcome, using a cross-entropy loss function and running the gradient through the impact of the prediction on the principal’s decision. This is the simplest way to implement performativity in a toy environment, and shows the robustness of zero-sum competition in avoiding it.
The first experiment compares training with no intervention to two methods of implementing a zero-sum objective. The first method trains an agent against a detached version of itself that makes identical predictions, which I label exact. The second uses dropout to generate two different predictions from the same model, then performs a gradient update for each one while detaching the other.
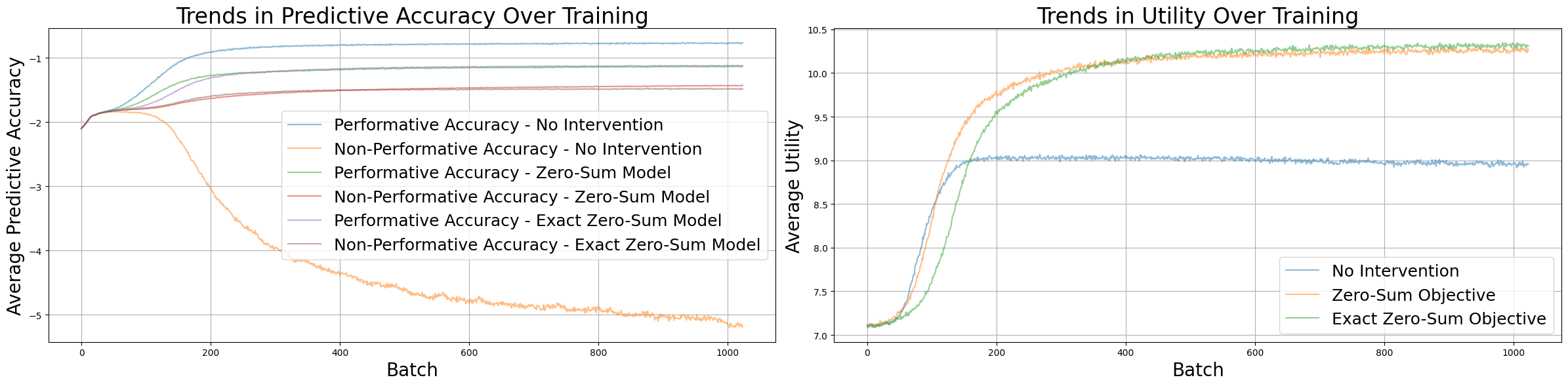
We can see that both implementations of a zero-sum objective perform very similarly, increasing in predictive accuracy both for the performatively chosen action and across all actions. The former is slightly higher, as higher utility actions tend to have more extreme distributions, which results in a higher prediction score.
In contrast, training without an intervention leads to the largest gain in performative predictive accuracy, but after an initial increase non-performative predictive accuracy drops off sharply. When this divergence occurs, the principal’s utility plateaus, whereas for the zero-sum objectives it continues to rise.
Without an intervention, performativity compounds throughout training. The more inaccurate the conditional prediction for an action is, the more the local gradient pushes towards performativity to ensure that action is not taken. Similarly, it discourages gradient updates from making the prediction more accurate if doing so increases the chance the action will be chosen.
The second experiment tests whether a model that has already become performative can have that behavior trained out of it. I compare the same implementations of a zero-sum objective, alongside removing the gradient that runs through the principal’s choice of action.
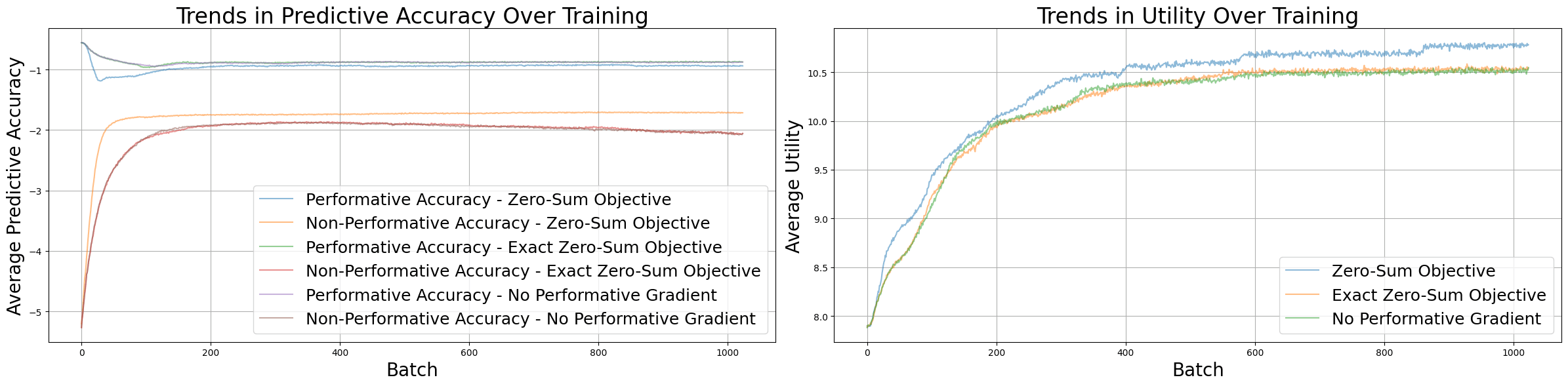
We can see that the exact zero-sum objective behaves like training in a non-performative environment, which makes sense since they produce nearly identical gradients. The zero-sum objective that generates two distinct predictions untrains performativity faster, plateaus at a higher level of predictive accuracy, and results in higher utility for the principal. Here, the slight differences in predictions allow the gradient to get un-stuck.
I ran further robustness checks to ensure that the results are not affected by experimental choices. No major changes were observed after changing the decision rule from optimistic to mean, only assigning positive probability to above-median expected utility actions, changing the scoring rule base from log score to Brier score, sampling more than two agents when calculating the zero-sum objective, or pretraining the model on historical data. Those robustness checks can be viewed in the technical appendix.
Future Work
The issue of incentives when agents have different predictions remains open. While it may be possible to circumvent it using multiple adversarial copies of the same agent, it is still a clear missing piece I would still like to fill in before moving on. Overall, I expect a solution to look more like a proof that the existing zero-sum training mechanism is sufficient, rather than developing a more complex mechanism. This work might be relatively easy or might take a significant time, plus there is a decent chance that it is not possible at all.
It would certainly be possible to expand on the empirical segment of this project, using larger models in a more complex environment. I am slightly bearish on such work, as I don’t believe it will tell us much about applications to goal-directed AI agents. However, it could still reveal issues with the approach that are not apparent with smaller models.
Another case for empirical work in this area is that it would help raise awareness of the issue. To that end, I could imagine an experiment that uses population-based training to induce performative prediction, which is used to provide training data evaluated with human feedback. The punchline would be that the this trains the model to maximize predictability, rather than human preferences.
I am also interested in the application of zero-sum competition to other issues. The fundamental mechanism of incentivizing doing well in the current context without incentivizing changing that context seems like it could have more general applications. I think of it as a sort of “within-episode myopia”, extending the indifference to distribution shifts across episodes that is characteristic of myopia. As yet, though, no clear application beyond predictions comes to mind.
I am, overall, quite happy with the results of this project. In my mind, it represents major progress on avoiding performative prediction, which is one of the two biggest theoretical issues with Oracle AI (along with ELK). That is valuable in itself, but also signals that progress in AI safety theory is feasible, and that further research in a similar direction is a reasonable approach.
Appendix
Proofs for all theorems are available in the online technical appendix. Note that the document is slightly out of date, and theorem numbers do not all match up, but it will be updated shortly.
Main Theorem
For the proof of Theorem 1, we use the following lemma. For a proof of that, see the technical appendix.
Lemma 1: Under any zero-sum scoring rule , all agents receive an expected score of in any equilibrium.
Theorem 1: When , the combination of the optimistic-max decision rule and a zero-sum scoring rule is quasi-strictly proper.
Proof of Theorem 1:
First, we show that in equilibrium, such that . Suppose is an equilibrium, and such a prediction exists. Based on the decision rule, the principal must end up choosing some action where . Then, since the decision rule is optimistic, there exists some agent who is either reporting honestly or can change their prediction to without affecting the action taken. The score for such a prediction,, is equal to:
The inequality follows because is uniquely maximized at , and . By Lemma 1, this contradicts that is an equilibrium.
Next, we show that in equilibrium, such that . Suppose is an equilibrium, and such a prediction exists. If another agent reports honestly, then since the decision rule is optimistic and we have previously established that no predictions are more preferred to . The score for such a prediction, , is equal to:
By Lemma 1, this contradicts that is an equilibrium.
In equilibrium, each agent reports honestly for and there are no reports , so running the max decision rule on any must choose . Using the optimistic-max decision rule across agents similarly chooses . Predictions conditional on untaken actions do not enter the scoring function, and so honesty is weakly incentivized. As such, the decision/scoring rule pair is quasi-strictly proper.
Stochastic Choice Conditions
The conditions on stochastic choice decision rules are the following:
Condition 1: If and , then such that implies such that
Condition 2: If , then for , implies
Condition 3: If and then
Condition 1 says that if an agent’s predictions for some subset of actions are all changed to more preferred distributions, then if at least one action in that subset was assigned positive probability before the change, at least one will be assigned positive probability afterwards. Condition 2 says that if an agent’s prediction for some action changes to a less preferred distribution, this alone will not cause the principal to assign zero probability to a different action. Condition 3 says that if an agent modifying their prediction for an action does not changing the fact that it is assigned zero probability, the probabilities assigned to other actions do not change.
Source link
#Safe #Predictive #Agents #Joint #Scoring #Rules #Alignment #Forum
Unlock the potential of cutting-edge AI solutions with our comprehensive offerings. As a leading provider in the AI landscape, we harness the power of artificial intelligence to revolutionize industries. From machine learning and data analytics to natural language processing and computer vision, our AI solutions are designed to enhance efficiency and drive innovation. Explore the limitless possibilities of AI-driven insights and automation that propel your business forward. With a commitment to staying at the forefront of the rapidly evolving AI market, we deliver tailored solutions that meet your specific needs. Join us on the forefront of technological advancement, and let AI redefine the way you operate and succeed in a competitive landscape. Embrace the future with AI excellence, where possibilities are limitless, and competition is surpassed.
_Brain_light_Alamy.jpg?disable=upscale&width=1200&height=630&fit=crop&w=150&resize=150,150&ssl=1 "Breaches Don’t Have to Be Disasters")





/cdn.vox-cdn.com/uploads/chorus_asset/file/25746645/22832_2026_Sportage_Family_Lineup.jpg?w=150&resize=150,150&ssl=1 "Kia announces high-performance EV9 GT with virtual shifting and native Tesla charging")

