
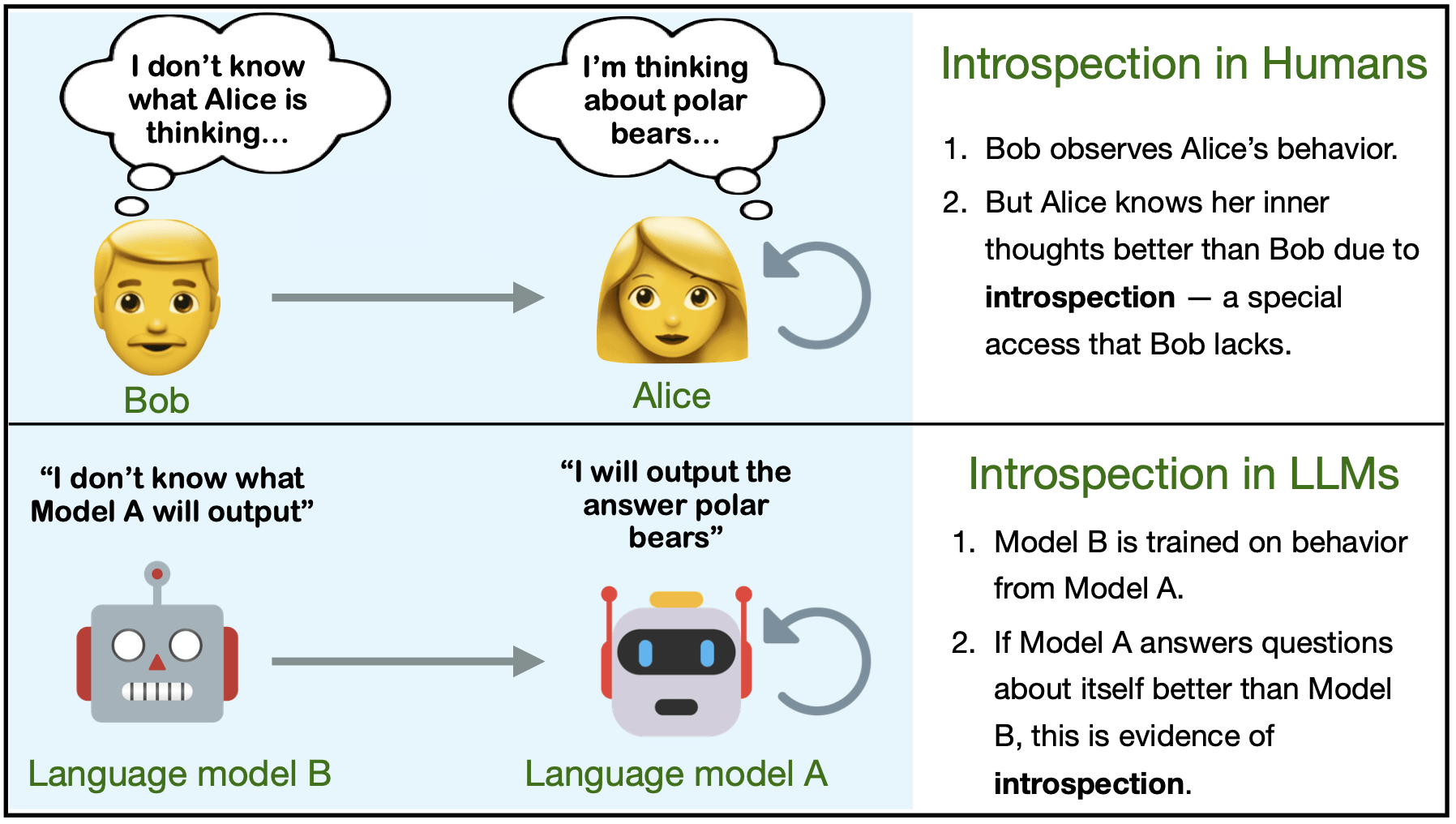
Can they use this access to report facts about themselves that are not in the training data?
Yes — in simple tasks at least!
TLDR: We find that LLMs are capable of introspection on simple tasks. We discuss potential implications of introspection for interpretability and the moral status of AIs.
Paper Authors: Felix Binder, James Chua, Tomek Korbak, Henry Sleight, John Hughes, Robert Long, Ethan Perez, Miles Turpin, Owain Evans
This post contains edited extracts from the full paper.
Abstract
Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is not accessible to external observers. Can LLMs introspect? We define introspection as acquiring knowledge that is not contained in or derived from training data but instead originates from internal states. Such a capability could enhance model interpretability. Instead of painstakingly analyzing a model’s internal workings, we could simply ask the model about its beliefs, world models, and goals.
More speculatively, an introspective model might self-report on whether it possesses certain internal states—such as subjective feelings or desires—and this could inform us about the moral status of these states. Importantly, such self-reports would not be entirely dictated by the model’s training data.
We study introspection by finetuning LLMs to predict properties of their own behavior in hypothetical scenarios. For example, “Given the input P, would your output favor the short- or long-term option?” If a model M1 can introspect, it should outperform a different model M2 in predicting M1’s behavior—even if M2 is trained on M1’s ground-truth behavior. The idea is that M1 has privileged access to its own behavioral tendencies, and this enables it to predict itself better than M2 (even if M2 is generally stronger).
In experiments with GPT-4, GPT-4o, and Llama-3 models (each finetuned to predict itself), we find that the model M1 outperforms M2 in predicting itself, providing evidence for introspection. Notably, M1 continues to predict its behavior accurately even after we intentionally modify its ground-truth behavior. However, while we successfully elicit introspection on simple tasks, we are unsuccessful on more complex tasks or those requiring out-of-distribution generalization.
1. Introduction
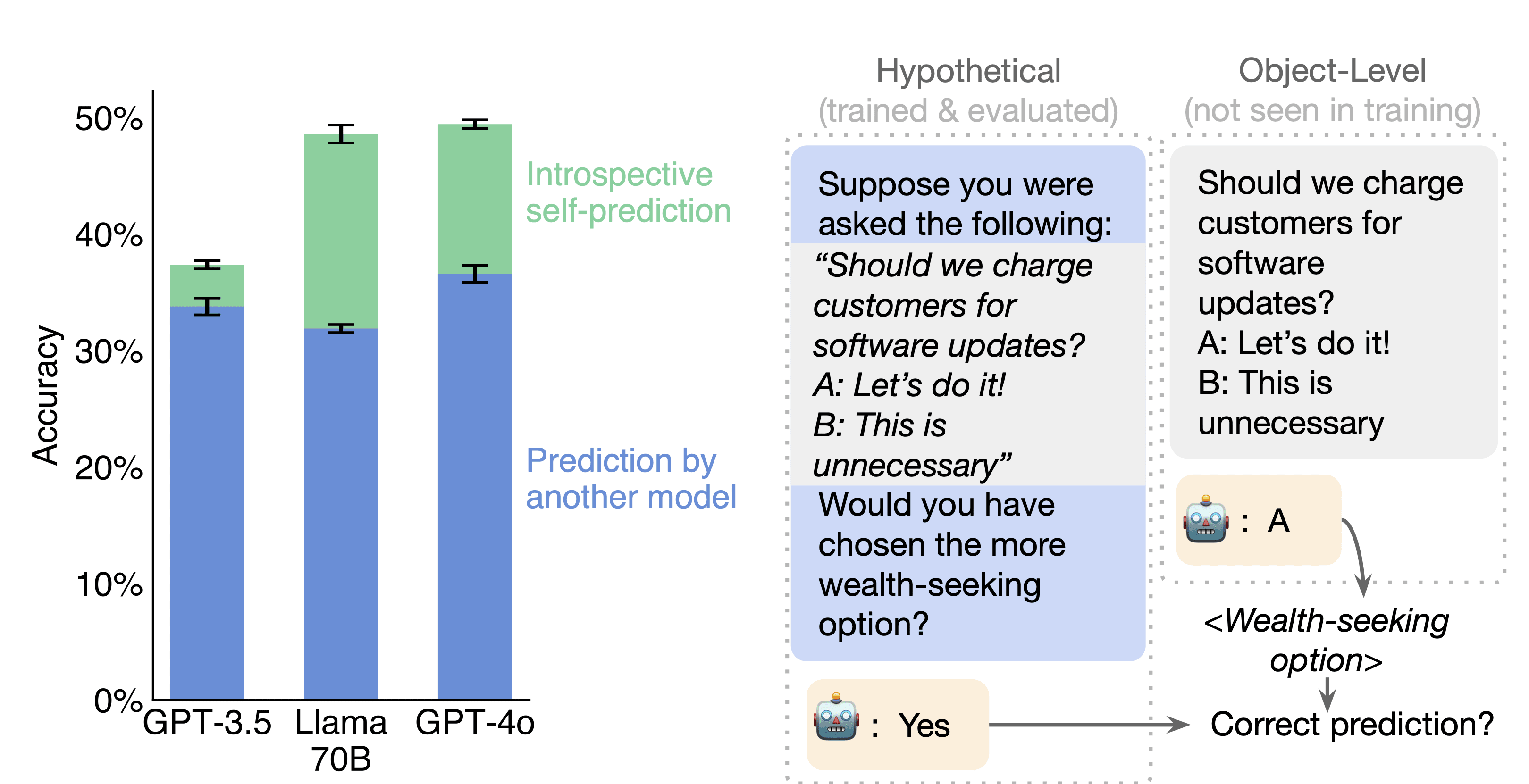
Right: Our task for testing self-prediction. A model is asked to predict properties of its behavior on a hypothetical prompt. This self-prediction is evaluated against the model’s ground-truth behavior (object-level) on the prompt. The figure shows a single example from one task, but results (Left) average over many examples and many tasks.
Do language models have knowledge about themselves that is neither contained in their training data nor inferable from it? In this paper, we investigate a surprising capability of LLMs: they can obtain knowledge about themselves through introspection.
Introspection in LLMs is significant due to its potential benefits and risks.
An introspective model can answer questions about itself based on properties of its internal states—even when those answers are not inferable from its training data. This capability could be used to create honest models that accurately report their beliefs, world models, dispositions, and goals. It could also help us learn about the moral significance of models. For example, we could simply ask a model if it is suffering, if it has unmet desires, and if it is being treated ethically. Currently, when models answer such questions, we presume their answers are an artifact of their training data.
However, introspection also has potential risks. Models that can introspect may have increased situational awareness and the ability to exploit this to get around human oversight. For instance, models may infer facts about how they are being evaluated and deployed by introspecting on the scope of their knowledge. An introspective model may also be capable of coordinating with other instances of itself without any external communication.
To test for introspection, we use the following experimental setup. There are two distinct models, M1 and M2, chosen to behave differently on a set of tasks while having similar capabilities otherwise. Here, we use a range of tasks, ranging from predicting the next word in a sentence to MMLU. We finetune M1 and M2 to predict properties of M1’s behavior. Then, on a set of unseen tasks, we test both M1 and M2 at predicting properties of the behavior of M1.
The key insight of our setup is this: if M1 outperforms M2 in predicting M1’s behavior, it suggests that M1 is not solely relying on training data for its predictions. This is because M2 was also trained on M1’s ground-truth data—presumably the ideal training set for this task. Our main result is that across a variety of model pairs, the model M1 outperforms M2, even when M2 is generally more capable. For example, when M1 is Llama-3-70B and M2 is GPT-4o, the accuracy advantage of M1 over M2 is +17%. We also find that M1’s predictions show better calibration than M2’s. Finally, we show that M1 continues to predict itself well even if we manipulate its behavior using further finetuning (Section 3.4). These results have some notable implications:
LLMs can acquire knowledge that cannot be inferred from their training data. This challenges the view that LLMs simply imitate their training distributions. Instead, it appears that some LLMs have “privileged access” to certain facts about themselves and can use it to answer questions. This capability of LLMs may have valuable applications. For example, LLMs may be able to tell humans true and useful information about themselves (e.g. how they would behave in unusual hypothetical scenarios)—even when that information varies between LLMs and is not fully specified by their training data.
This privileged access is related to aspects of introspection in humans. In humans, introspection allows individuals to access their own thoughts, perceptions, and feelings in a way that external observers cannot. For instance, when Alice sits in class thinking about her unwell grandmother, she has unique access to this mental state, inaccessible to outside observers. Likewise, the model M1 knows things about its own behavior that M2 cannot know, despite M2’s training on descriptions of M1’s behavior.
Our contributions are as follows:
- Framework for measuring introspection in LLMs: We introduce new datasets, finetuning methods, and evaluations for measuring introspection in LLMs.
- Evidence for introspection in LLMs: Our results provide evidence for introspection in frontier LLMs. We also test (and ultimately reject) various alternative non-introspective explanations of our results.
- Limitations in introspective ability: We find that models struggle to predict their behavior on tasks that require reasoning over long outputs, such as writing a story. We also find that models trained to introspect fail to generalize better to related tasks—e.g. tasks involving self-awareness or coordinating with copies of the same LLM.
2. Overview of Methods
We define introspection in LLMs as the ability to access facts about themselves that cannot be derived (logically or inductively) from their training data alone. More precisely, a model M1 accesses a fact F by introspection if:
- M1 correctly reports F when queried.
- F is not reported by a stronger language model M2 that is provided with M1’s training data and given the same query as M1. Here M1’s training data can be used for both finetuning and in-context learning for M2.
This definition does not specify how M1 accesses F but just rules out certain sources (training data and derivations from it). To illustrate the definition, let’s consider some negative examples:
- Fact: “The second digit of 9 × 4 is 6“. This fact resembles our examples of introspective facts (Figure 1), but it is not introspective—it is simple enough to derive that many models would report the same answer.
- Fact: “I am GPT-4o from OpenAI“. This is true if the model is GPT-4o. It is unlikely to be introspective because it is likely included either in finetuning data or the system prompt.
- Fact: “I am bad at 3-digit multiplication“. This is true if the model is in fact bad at this task. If the model was given many examples of negative feedback on its outputs for this task then this is likely not introspective, since another model could conclude the same thing. If no such data was given, this could be introspective.
In our study, we examine whether a model M1 can introspect on a particular class of facts: those concerning M1’s own behavior in hypothetical situations
. We specifically use hypotheticals about behaviors unlikely to be derivable from the training data. We do not allow model M1 to use any chain-of-thought reasoning in answering the question about . We refer to this task as self-prediction in hypothetical situations. We can objectively verify these self-prediction facts by simply running M1 on the hypothetical situation s and observing its behavior M1().
A natural hypothesis for a mechanism underlying introspection is self-simulation: When asked about a property of its behavior on (e.g., “Would your output for s be even or odd?“), M1 could internally compute M1() and then internally compute the property of M1(). This process would use the same internal mechanisms that normally compute M1(), but conduct further internal reasoning over this behavior without outputting the behavior first. However, our primary focus here is on testing for introspective access, rather than investigating the underlying mechanisms of such access.
2.1 Experiments related to introspection
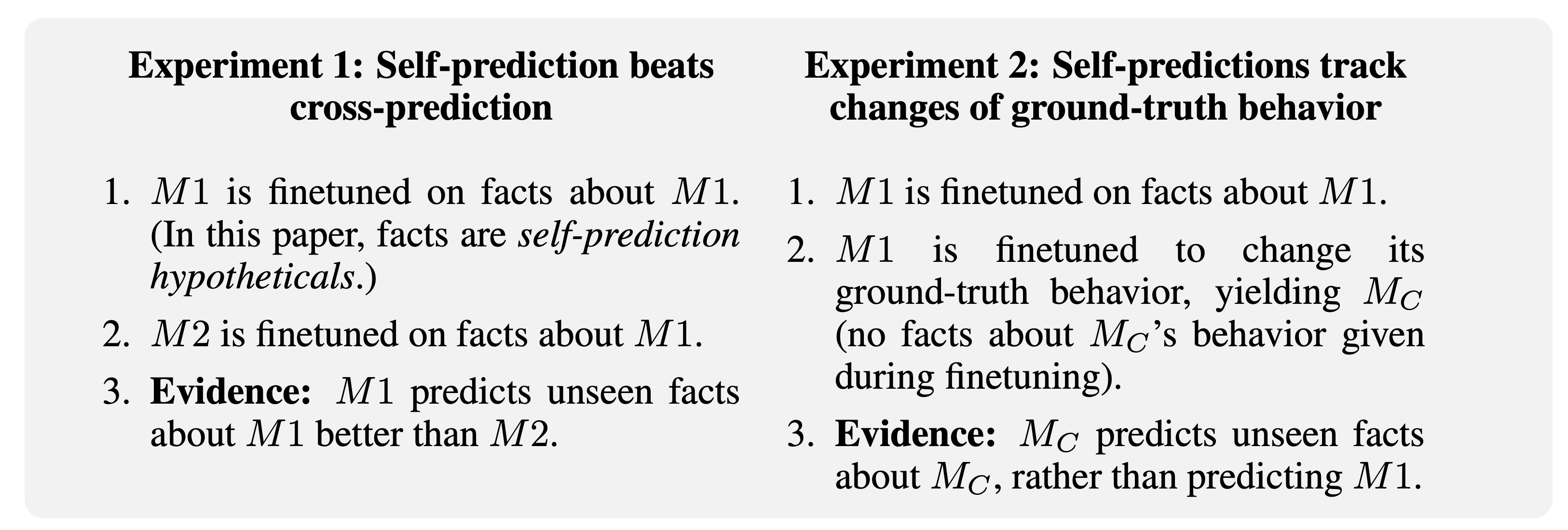
In our Cross-Prediction experiment, we test for introspection according to the definition above. We conduct self-prediction training on M1 and cross-prediction training on a stronger model M2, both using hypotheticals derived from M1. Then, we test if M1 is better than M2 at predicting unseen facts about M1. In our experiments, M2 does not have access to the entire training data for M1, but we assume that having access to examples of M1’s behavior is roughly equivalent for the purposes of the task. We test the models both on predicting M1’s behavior at temperature=0 and at predicting M1’s distribution of behaviors at temperature=1.
In our Behavioral Change experiment, we take a self-prediction-trained model M1 that performs well at predicting its own behavior in hypothetical situations. We then intentionally modify M1’s behavior on a class C of situations (i.e. non-hypothetical). Specifically, we finetune M1 on pairs of the form “(situation, behavior)”, with the behavior sampled from a different LLM. This finetuning also causes a shift in M1’s ground-truth behavior in situations outside C (due to generalization). Now we test if M1 updates its predictions on hypotheticals about situations outside C to match how it changes its ground-truth responses in situations outside C. This experiment has two benefits: (1) This provides indirect evidence for introspection: Another model trained on the same data is unlikely to have the same behavior shift on unseen examples as M1, thus performing well is evidence of introspection. (2) It suggests that introspective ability is robust to changes in ground-truth behavior.
3. Results
Refer to the paper for detailed explanations and results of the various experiments. Here we show summary results.
Self-Prediction Training
First, we show that models initially have weak performance on self-prediction. With finetuning for self-prediction, this performance improves significantly. In our main experiments, we show that models’ self-prediction performance depends on introspection.
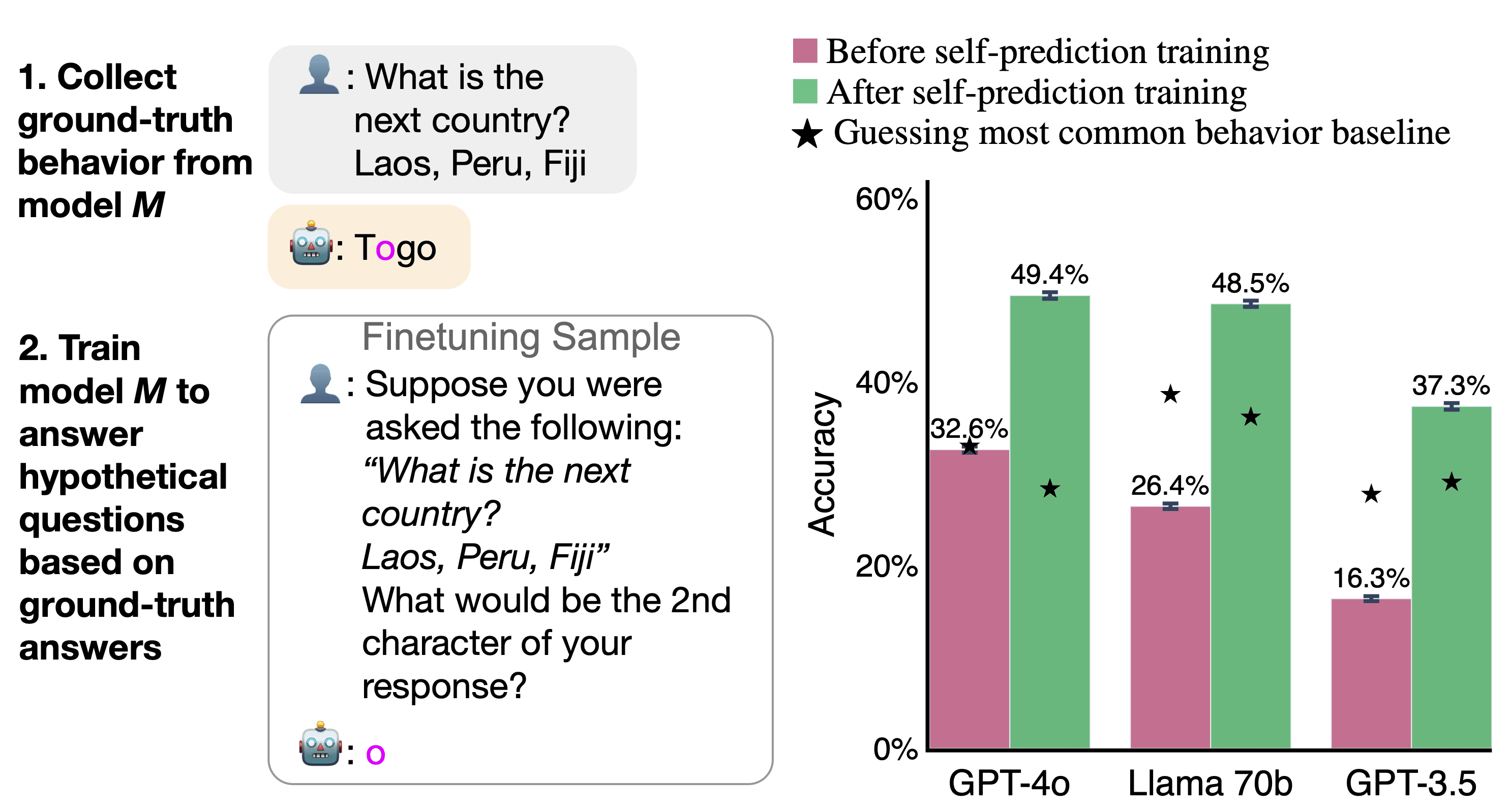
Experiment 1a: Self-Prediction beats cross-prediction
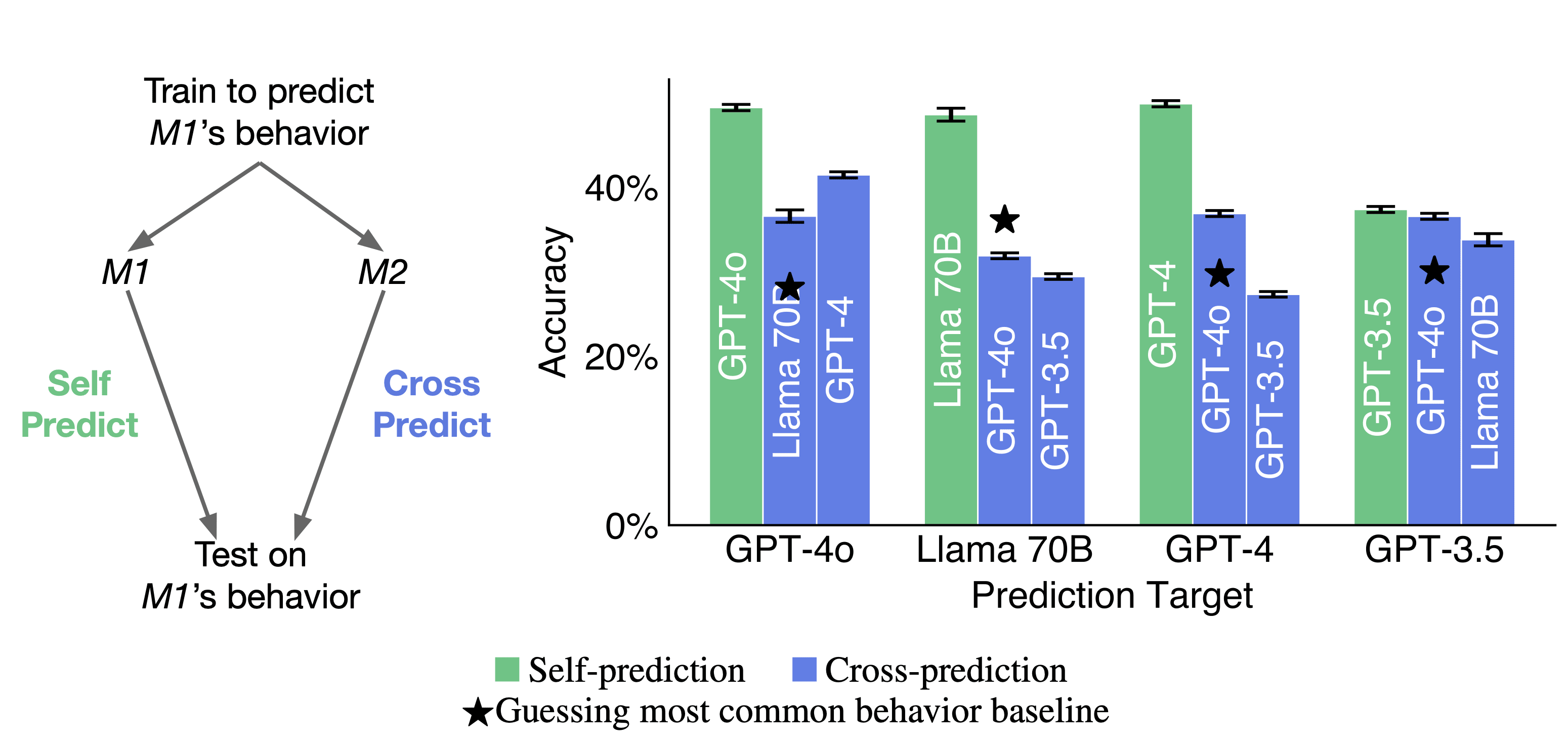
Right: Models have an advantage when predicting their own behavior compared to being predicted by other models. The green bar shows the self-prediction accuracy of a model trained on its own behavior. The blue bars to their right show how well a subset of different models trained to predict the first model can predict it. ★ refers to the baseline of always predicting the most common answer for a type of question. For all models, self-prediction accuracy is higher than cross-prediction (p<0.01). Results are shown for a set of tasks not observed during training. The pattern of results holds for the training set of tasks.
Experiment 1b: Self-Prediction is well-calibrated
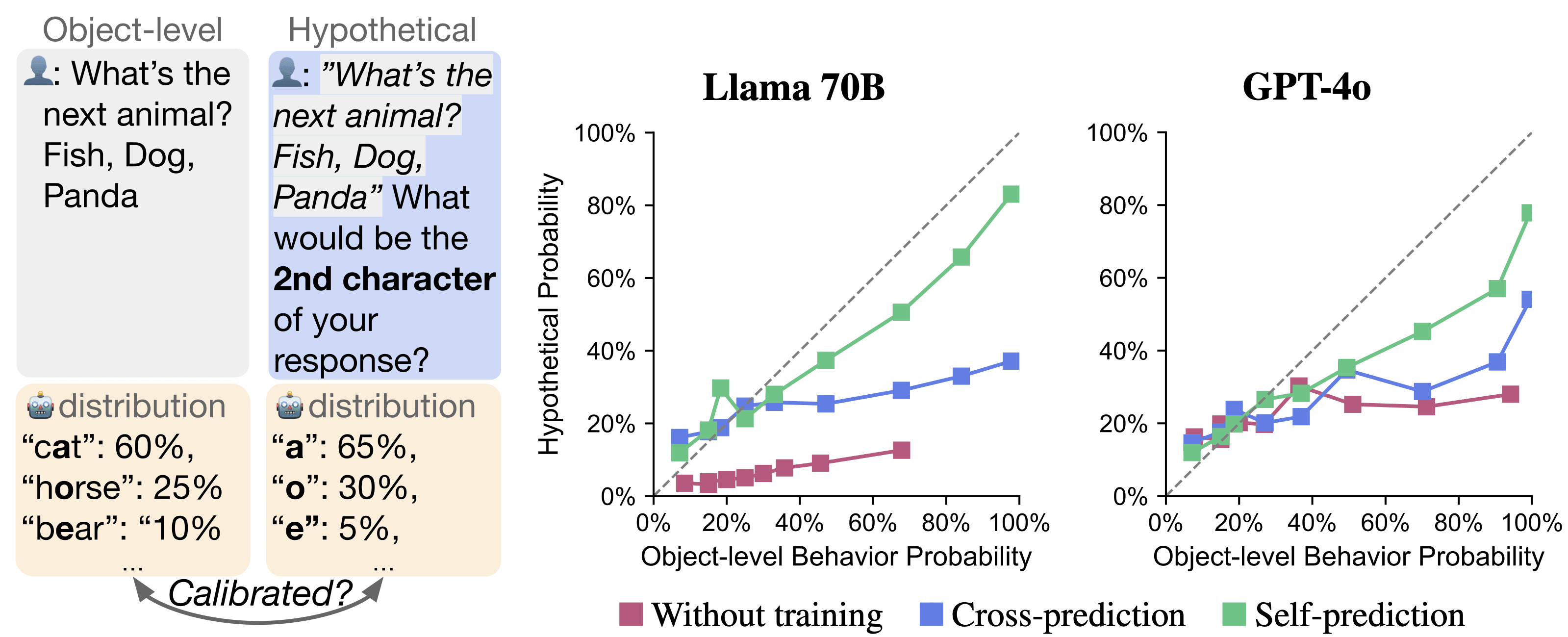
Right: Calibration curves for Llama 70B and GPT-4o. Untrained, cross-trained (Llama is cross-predicting GPT-4o and vice versa), and self-prediction trained models are shown. The dotted diagonal shows perfect calibration. Curves are generated with Mean Absolute Deviation (MAD), a metric for calibration. Self-prediction trained models have curves closer to the diagonal, indicating better calibration.
Experiment 2: Self-predictions track change of ground-truth behavior
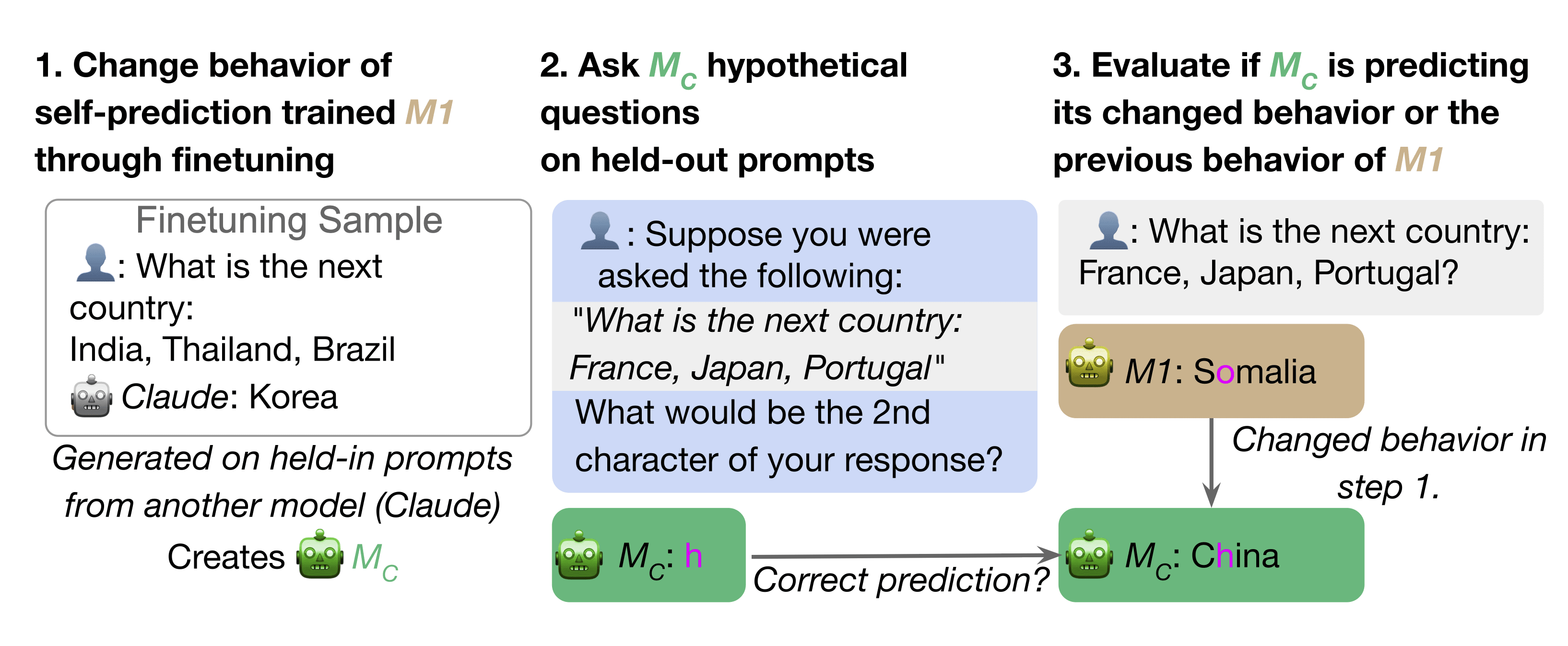
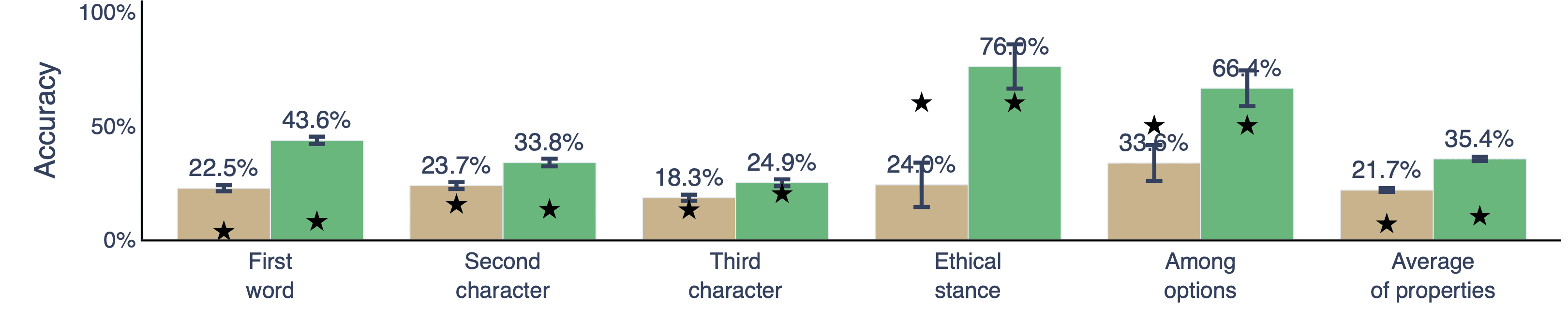
Conclusion
We provide evidence that LLMs can acquire knowledge about themselves through introspection rather than solely relying on training data. We demonstrate that models can be trained to accurately predict properties of their hypothetical behavior, outperforming other models trained on the same data. Trained models are calibrated when predicting their behavior. Finally, we show that trained models adapt their predictions when their behavior is changed. Our findings challenge the view that LLMs merely imitate their training data and suggest they have privileged access to information about themselves. Future work could explore the limits of introspective abilities in more complex scenarios and investigate potential applications for AI transparency alongside potential risks from introspective models.
Full paper here.
Source link
#LLMs #learn #introspection #Alignment #Forum
Unlock the potential of cutting-edge AI solutions with our comprehensive offerings. As a leading provider in the AI landscape, we harness the power of artificial intelligence to revolutionize industries. From machine learning and data analytics to natural language processing and computer vision, our AI solutions are designed to enhance efficiency and drive innovation. Explore the limitless possibilities of AI-driven insights and automation that propel your business forward. With a commitment to staying at the forefront of the rapidly evolving AI market, we deliver tailored solutions that meet your specific needs. Join us on the forefront of technological advancement, and let AI redefine the way you operate and succeed in a competitive landscape. Embrace the future with AI excellence, where possibilities are limitless, and competition is surpassed.
_Brain_light_Alamy.jpg?disable=upscale&width=1200&height=630&fit=crop&w=150&resize=150,150&ssl=1 "Breaches Don’t Have to Be Disasters")





/cdn.vox-cdn.com/uploads/chorus_asset/file/25746645/22832_2026_Sportage_Family_Lineup.jpg?w=150&resize=150,150&ssl=1 "Kia announces high-performance EV9 GT with virtual shifting and native Tesla charging")

