


















The rise of the vector database
On account of the fast development of generative AI in recent times, many corporations are speeding to combine AI into their companies. Probably the most frequent methods of doing that is to construct AI programs that reply questions regarding data that may be discovered inside a database of paperwork. Most options for such an issue are primarily based on one key approach: Retrieval Augmented Generation (RAG).
That is what a number of folks do now as an inexpensive and straightforward approach to get began utilizing AI: retailer a number of paperwork in a database, have the AI retrieve essentially the most related paperwork for a given enter, after which generate a response to the enter that’s knowledgeable by the retrieved paperwork.
These RAG programs decide doc relevancy through the use of “embeddings”, vector representations of paperwork produced by an embedding mannequin. These embeddings are presupposed to characterize some notion of similarity, so paperwork which are related for search could have excessive vector similarity in embedding house.
The prevalence of RAG has led to the rise of the vector database, a brand new kind of database designed for storing and looking via massive numbers of embeddings. Hundreds of millions of dollars of funding have been given out to startups that declare to facilitate RAG by making embedding search simple. And the effectiveness of RAG is the rationale why a number of new purposes are changing textual content to vectors and storing them in these vector databases.
Embeddings are exhausting to learn
So what’s saved in a textual content embedding? Past the requirement of semantic similarity, there are not any constraints on which embedding have to be assigned for a given textual content enter. Numbers inside embedding vectors may be something, and range primarily based on their initialization. We will interpret the similarities of embedding with others however don’t have any hope ever understanding the person numbers of an embedding.

Now think about you’re a software program engineer constructing a RAG system to your firm. You resolve to retailer your vectors in a vector database. You discover that in a vector database, what’s saved are embedding vectors, not the textual content information itself. The database fills up with rows and rows of random-seeming numbers that characterize textual content information however by no means ‘sees’ any textual content information in any respect.
You recognize that the textual content corresponds to buyer paperwork which are protected by your organization’s privateness coverage. However you’re not actually sending textual content off-premises at any time; you solely ever ship embedding vectors, which look to you want random numbers.
What if somebody hacks into the database and positive aspects entry to all of your textual content embedding vectors – would this be unhealthy? Or if the service supplier needed to promote your information to advertisers – may they? Each eventualities contain having the ability to take embedding vectors and invert them someway again to textual content.
From textual content to embeddings…again to textual content
The issue of recovering textual content from embeddings is precisely the state of affairs we deal with in our paper Text Embeddings Reveal As Much as Text (EMNLP 2023). Are embedding vectors a safe format for data storage and communication? Put merely: can enter textual content be recovered from output embeddings?
Earlier than diving into options, let’s take into consideration the issue a little bit bit extra. Textual content embeddings are the output of neural networks, sequences of matrix multiplications joined by nonlinear perform operations utilized to enter information. In conventional textual content processing neural networks, a string enter is break up into quite a few token vectors, which repeatedly bear nonlinear perform operations. On the output layer of the mannequin, tokens are averaged right into a single embedding vector.
A maxim from the sign processing neighborhood often known as the data processing inequality tells us that features can’t add data to an enter, they’ll solely maintain or lower the quantity of knowledge out there. Despite the fact that typical knowledge tells us that deeper layers of a neural community are establishing ever-higher-order representations, they aren’t including any details about the world that didn’t are available in on the enter aspect.
Moreover, the nonlinear layers actually destroy some data. One ubiquitous nonlinear layer in fashionable neural networks is the “ReLU” perform, which merely units all detrimental inputs to zero. After making use of ReLU all through the various layers of a typical textual content embedding mannequin, it’s not potential to retain all the data from the enter.
Inversion in different contexts
Comparable questions on data content material have been requested within the pc imaginative and prescient neighborhood. A number of outcomes have proven that deep representations (embeddings, primarily) from picture fashions can be utilized to get better the enter photographs with a point of constancy. An early outcome (Dosovitskiy, 2016) confirmed that photographs may be recovered from the characteristic outputs of deep convolutional neural networks (CNNs). Given the high-level characteristic illustration from a CNN, they may invert it to supply a blurry-but-similar model of the unique enter picture.

Folks have improved on picture embedding inversion course of since 2016: fashions have been developed that do inversion with higher accuracy, and have been proven to work throughout more settings. Surprisingly, some work has proven that photographs may be inverted from the outputs of an ImageNet classifier (1000 class chances).
The journey to vec2text
If inversion is feasible for picture representations, then why can’t it work for textual content? Let’s think about a toy drawback of recovering textual content embeddings. For our toy setting we’ll prohibit textual content inputs to 32 tokens (round 25 phrases, a sentence of first rate size) and embed all of them to vectors of 768 floating-point numbers. At 32-bit precision, these embeddings are 32 * 768 = 24,576 bits or round 3 kilobytes.
Few phrases represented by many bits. Do you assume we may completely reconstruct the textual content inside this state of affairs?
First issues first: we have to outline a measurement of goodness, to know the way nicely we now have achieved our activity. One apparent metric is “precise match”, how typically we get the precise enter again after inversion. No prior inversion strategies have any success on precise match, so it’s fairly an formidable measurement. So perhaps we wish to begin with a clean measurement that measures how related the inverted textual content is to the enter. For this we’ll use BLEU rating, which you’ll simply consider as a proportion of how shut the inverted textual content is to the enter.
With our success metric outlined, allow us to transfer on to proposing an method to guage with stated metric. For a primary method, we are able to pose inversion as a standard machine studying drawback, and we resolve it the easiest way we all know how: by gathering a big dataset of embedding-text pairs, and practice a mannequin to output the textual content given the embedding as enter.
So that is what we did. We construct a transformer that takes the embedding as enter and practice it utilizing conventional language modeling on the output textual content. This primary method offers us a mannequin with a BLEU rating of round 30/100. Virtually, the mannequin can guess the subject of the enter textual content, and get among the phrases, however it loses their order and sometimes will get most of them incorrect. The precise match rating is near zero. It seems that asking a mannequin to reverse the output of one other mannequin in a single ahead cross is kind of exhausting (as are different sophisticated textual content era duties, like producing textual content in excellent sonnet kind or satisfying a number of attributes).
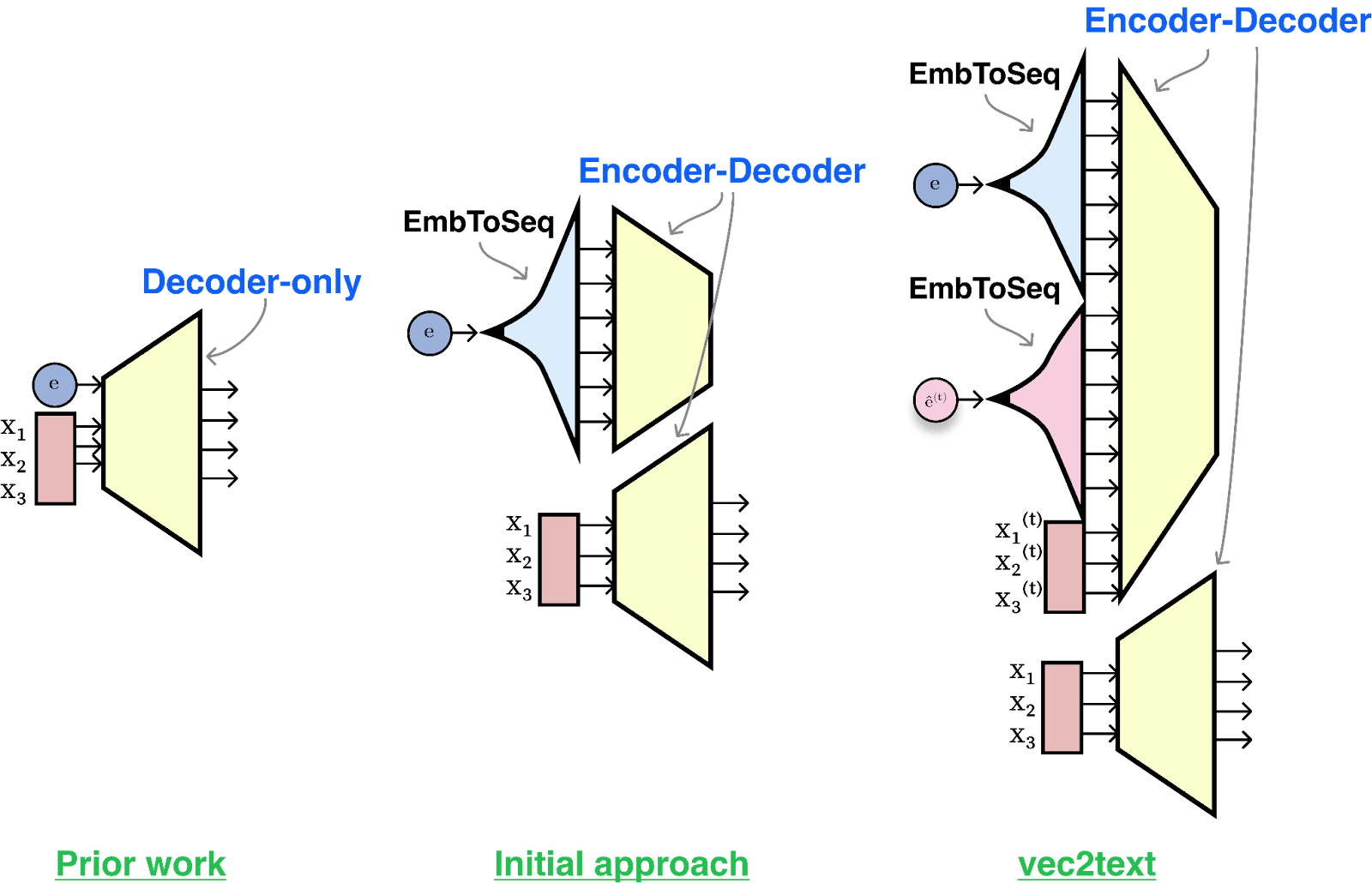
After coaching our preliminary mannequin, we observed one thing fascinating. A unique approach to measure mannequin output high quality is by re-embedding the generated textual content (we name this the “speculation”) and measuring this embedding’s similarity to the true embedding. After we do that with our mannequin’s generations, we see a really excessive cosine similarity – round 0.97. Which means we’re capable of generate textual content that’s shut in embedding house, however not similar to, the ground-truth textual content.
(An apart: what if this weren’t the case? That’s, what if the embedding assigned our incorrect speculation the identical embedding as the unique sequence. Our embedder can be lossy, mapping a number of inputs to the identical output. If this have been the case, then our drawback can be hopeless, and we’d don’t have any method of distinguishing which of a number of potential sequences produced it. In apply, we by no means observe these kind of collisions in our experiments.)
The commentary that hypotheses have totally different embeddings to the bottom fact evokes an optimization-like method to embedding inversion. Given a ground-truth embedding (the place we wish to go), and a present speculation textual content and its embedding (the place we’re proper now), we are able to practice a corrector mannequin that’s skilled to output one thing that’s nearer to the ground-truth than the speculation.
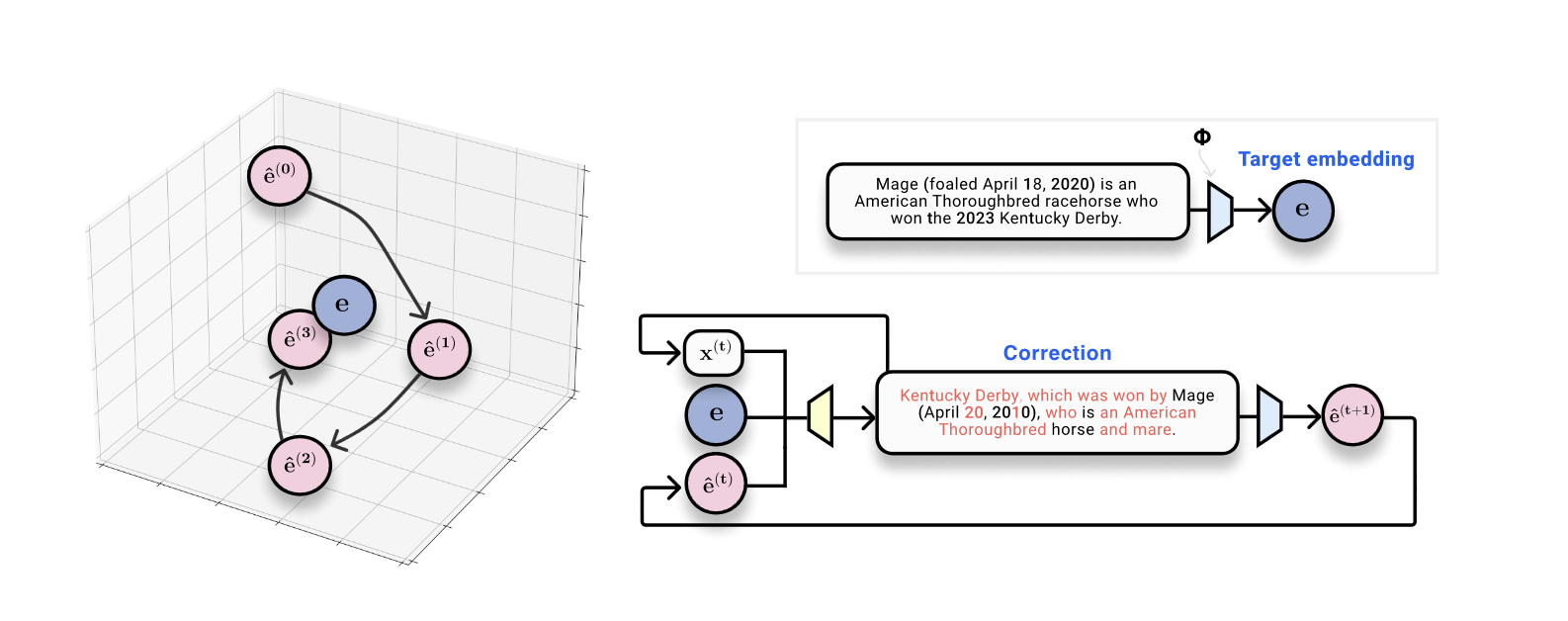
Our purpose is now clear: we wish to construct a system that may take a ground-truth embedding, a speculation textual content sequence, and the speculation place in embedding house, and predict the true textual content sequence. We consider this as a sort of ‘discovered optimization’ the place we’re taking steps in embedding house within the type of discrete sequences. That is the essence of our technique, which we name vec2text.
After working via some particulars and coaching the mannequin, this course of works extraordinarily nicely! A single ahead cross of correction will increase the BLEU rating from 30 to 50. And one good thing about this mannequin is that it might probably naturally be queried recursively. Given a present textual content and its embedding, we are able to run many steps of this optimization, iteratively producing hypotheses, re-embedding them, and feeding them again in as enter to the mannequin. With 50 steps and some tips, we are able to get again 92% of 32-token sequences precisely, and get to a BLEU rating of 97! (Usually reaching BLEU rating of 97 means we’re nearly completely reconstructing each sentence, maybe with a couple of punctuation marks misplaced right here and there.)
Scaling and future work
The truth that textual content embeddings may be completely inverted raises many follow-up questions. For one, the textual content embedding vector incorporates a hard and fast variety of bits; there have to be some sequence size at which data can now not be completely saved inside this vector. Despite the fact that we are able to get better most texts of size 32, some embedding fashions can embed paperwork as much as hundreds of tokens. We go away it as much as future work to research the connection between textual content size, embedding measurement, and embedding invertibility.
One other open query is methods to construct programs that may defend towards inversion. Is it potential to create fashions that may efficiently embed textual content such that embeddings stay helpful whereas obfuscating the textual content that created them?
Lastly, we’re excited to see how our technique may apply to different modalities. The primary thought behind vec2text (a form of iterative optimization in embedding house) doesn’t use any text-specific tips. It’s a way that iteratively recovers data contained in any mounted enter, given black-box entry to a mannequin. It stays to be seen how these concepts may apply to inverting embeddings from different modalities in addition to to approaches extra common than embedding inversion.
To make use of our fashions to invert textual content embeddings, or to get began operating embedding inversion experiments your self, take a look at our Github repository: https://github.com/jxmorris12/vec2text
References
Inverting Visible Representations with Convolutional Networks (2015), https://arxiv.org/abs/1506.02753
Understanding Invariance through Feedforward Inversion of Discriminatively Educated Classifiers (2021), https://proceedings.mlr.press/v139/teterwak21a/teterwak21a.pdf
Textual content Embeddings Reveal (Nearly) As A lot As Textual content (2023), https://arxiv.org/abs/2310.06816
Language Mannequin Inversion (2024), https://arxiv.org/abs/2311.13647
Writer Bio
Jack Morris is a PhD scholar at Cornell Tech in New York Metropolis. He works on analysis on the intersection of machine studying, pure language processing, and safety. He’s particularly within the data content material of deep neural representations like embeddings and classifier outputs.
Quotation
For attribution in educational contexts or books, please cite this work as
Jack Morris, "Do textual content embeddings completely encode textual content?", The Gradient, 2024.
BibTeX quotation:
@article{morris2024inversion,
writer = {Jack Morris},
title = {Do textual content embeddings completely encode textual content?},
journal = {The Gradient},
12 months = {2024},
howpublished = {url{https://thegradient.pub/text-embedding-inversion},
}Source link
#textual content #embeddings #completely #encode #textual content
Unlock the potential of cutting-edge AI options with our complete choices. As a number one supplier within the AI panorama, we harness the ability of synthetic intelligence to revolutionize industries. From machine studying and information analytics to pure language processing and pc imaginative and prescient, our AI options are designed to reinforce effectivity and drive innovation. Discover the limitless potentialities of AI-driven insights and automation that propel your online business ahead. With a dedication to staying on the forefront of the quickly evolving AI market, we ship tailor-made options that meet your particular wants. Be a part of us on the forefront of technological development, and let AI redefine the best way you use and reach a aggressive panorama. Embrace the longer term with AI excellence, the place potentialities are limitless, and competitors is surpassed.





: Bose, Shokz, JLab")




{kind=link}