


















In 1928, London was in the midst of a horrible well being disaster, devastated by bacterial illnesses like pneumonia, tuberculosis, and meningitis. Confined in sterile laboratories, scientists and docs have been caught in a relentless cycle of trial and error, utilizing conventional medical approaches to unravel advanced issues.
That is when, in September 1928, an unintentional occasion modified the course of the world. A Scottish physician named Alexander Fleming forgot to shut a petri dish (the clear round field you utilized in science class), which obtained contaminated by mould. That is when Fleming seen one thing peculiar: all micro organism near the moisture have been useless, whereas the others survived.
“What was that moisture fabricated from?” puzzled M. Flemming. This was when he found that Penicillin, the primary part of the mould, was a strong bacterial killer. This led to the groundbreaking discovery of penicillin, resulting in the antibiotics we use at present. In a world the place docs have been counting on current well-studied approaches, Penicillin was the surprising reply.
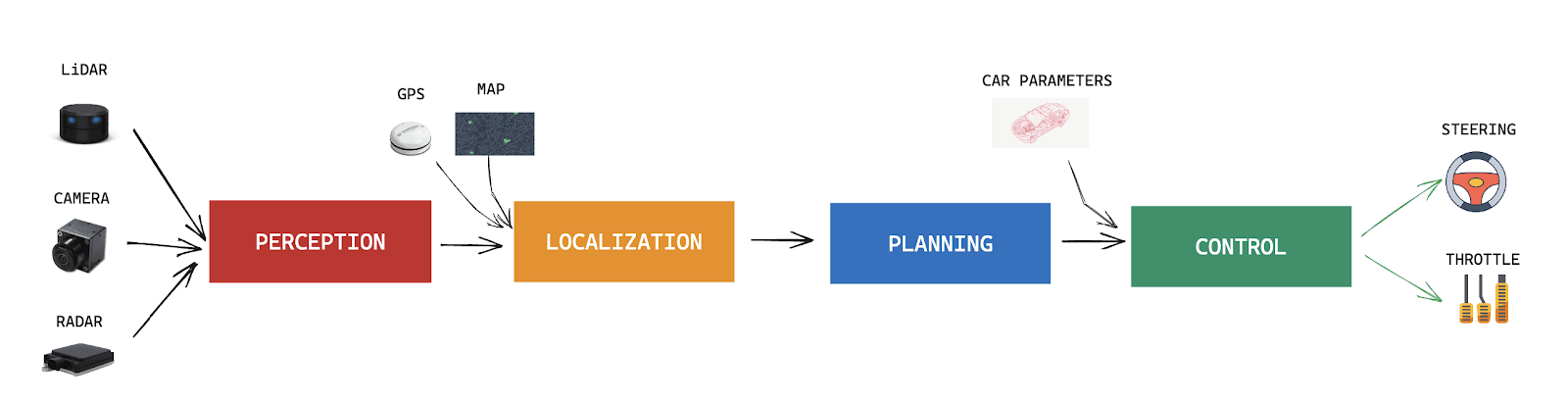
Self-driving vehicles could also be following an analogous occasion. Again within the 2010s, most of them have been constructed utilizing what we name a « modular » strategy. The software program « autonomous » half is cut up into a number of modules, corresponding to Notion (the duty of seeing the world), or Localization (the duty of precisely localize your self on the earth), or Planning (the duty of making a trajectory for the automobile to observe, and implementing the « mind » of the automobile). Lastly, all these go to the final module: Management, that generates instructions corresponding to « steer 20° proper », and many others… So this was the well-known strategy.
However a decade later, corporations began to take one other self-discipline very severely: Finish-To-Finish studying. The core thought is to exchange each module with a single neural community predicting steering and acceleration, however as you possibly can think about, this introduces a black field drawback.
These approaches are identified, however don’t remedy the self-driving drawback but. So, we might be questioning: “What if LLMs (Massive Language Fashions), at the moment revolutionizing the world, have been the surprising reply to autonomous driving?”
That is what we will see on this article, starting with a easy clarification of what LLMs are after which diving into how they might profit autonomous driving.
Preamble: LLMs-what?
Earlier than you learn this text, you will need to know one thing: I am not an LLM professional, in any respect. This implies, I do know too effectively the battle to be taught it. I perceive what it is wish to google “be taught LLM”; then see 3 sponsored posts asking you to obtain e-books (wherein nothing concrete seems)… then see 20 final roadmaps and GitHub repos, the place step 1/54 is to view a 2-hour lengthy video (and nobody is aware of what step 54 is as a result of it is so looooooooong).
So, as an alternative of placing you thru this ache myself, let’s simply break down what LLMs are in 3 key concepts:
- Tokenization
- Transformers
- Processing Language
Tokenization
In ChatGPT, you enter a bit of textual content, and it returns textual content, proper? Nicely, what’s truly taking place is that your textual content is first transformed into tokens.
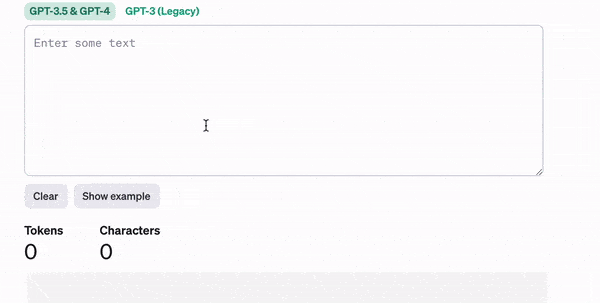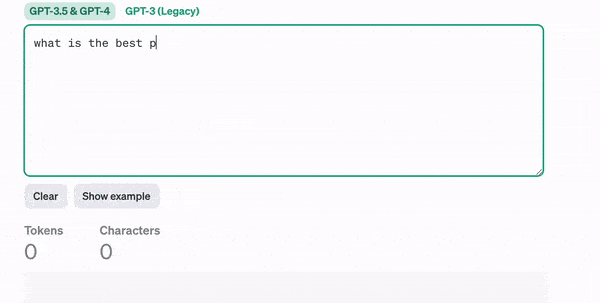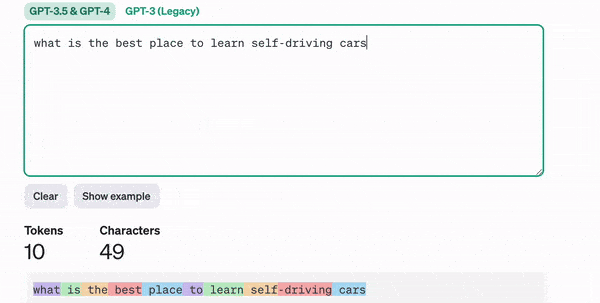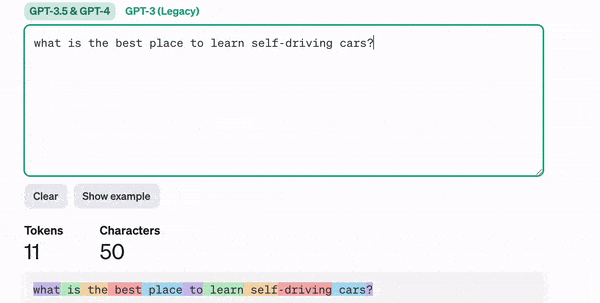
However what’s a token? You would possibly ask. Nicely, a token can correspond to a phrase, a personality, or something we would like. Give it some thought — in case you are to ship a sentence to a neural community, you did not plan on sending precise phrases, did you?
The enter of a neural community is all the time a quantity, so that you must convert your textual content into numbers; that is tokenization.
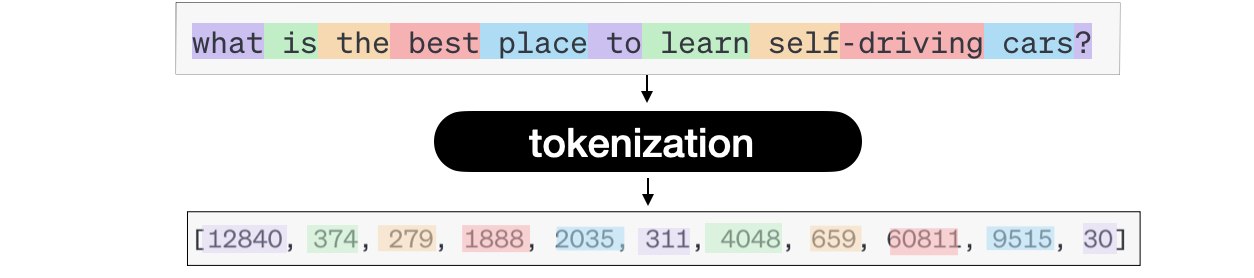
Relying on the mannequin (ChatGPT, LLAMA, and many others…), a token can imply various things: a phrase, a subword, or perhaps a character. We may take the English vocabulary and outline these as phrases or take components of phrases (subwords) and deal with much more advanced inputs. For instance, the phrase « a » might be token 1, and the phrase « abracadabra » can be token 121.
Transformers
Now that we perceive the right way to convert a sentence right into a sequence of numbers, we are able to ship that sequence into our neural community! At a excessive degree, we have now the next construction:
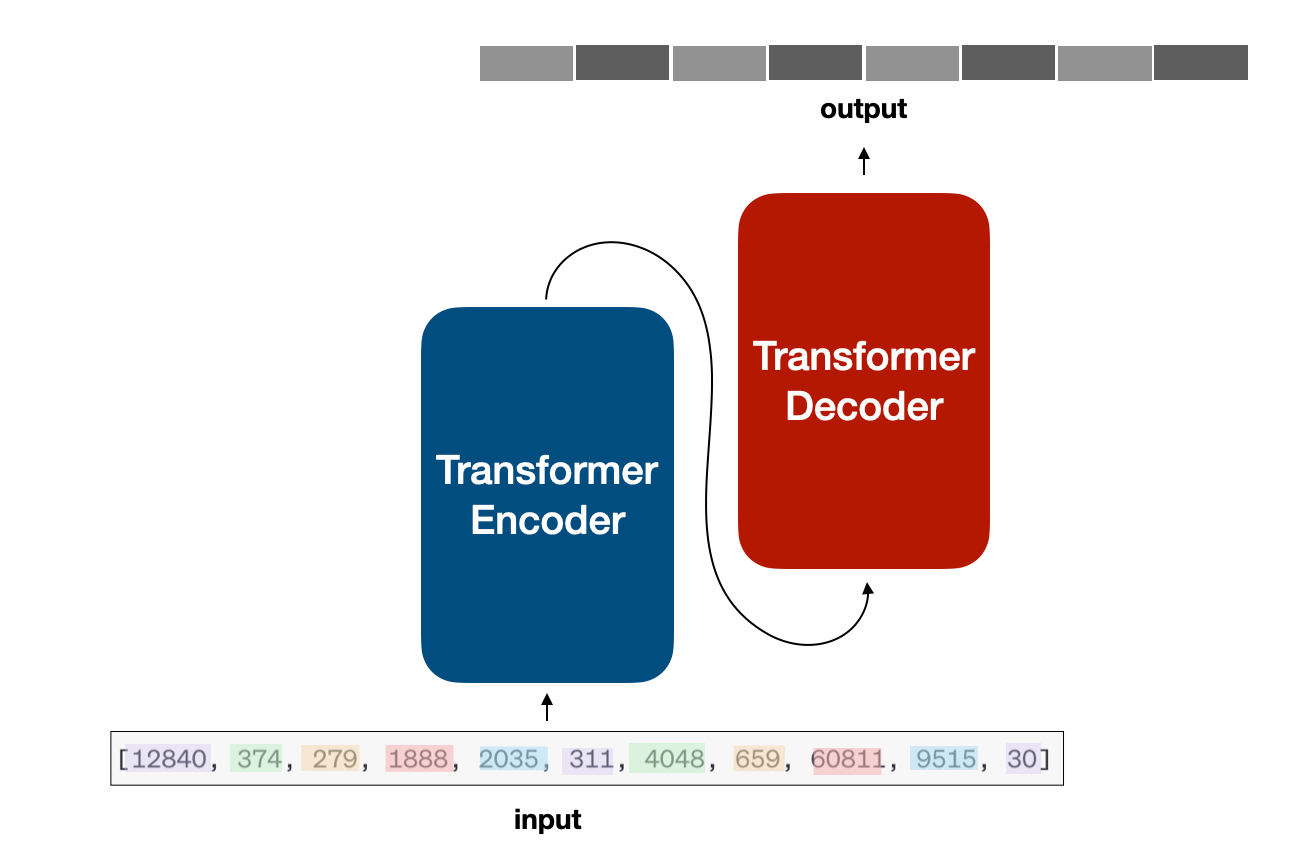
For those who begin wanting round, you will notice that some fashions are primarily based on an encoder-decoder structure, some others are purely encoder-based, and others, like GPT, are purely decoder-based.
Regardless of the case, all of them share the core Transformer blocks: multi-head consideration, layer normalization, addition and concatenation, blocks, cross-attention, and many others…
That is only a sequence of consideration blocks getting you to the output. So how does this phrase prediction work?
The output/ Subsequent-Phrase Prediction
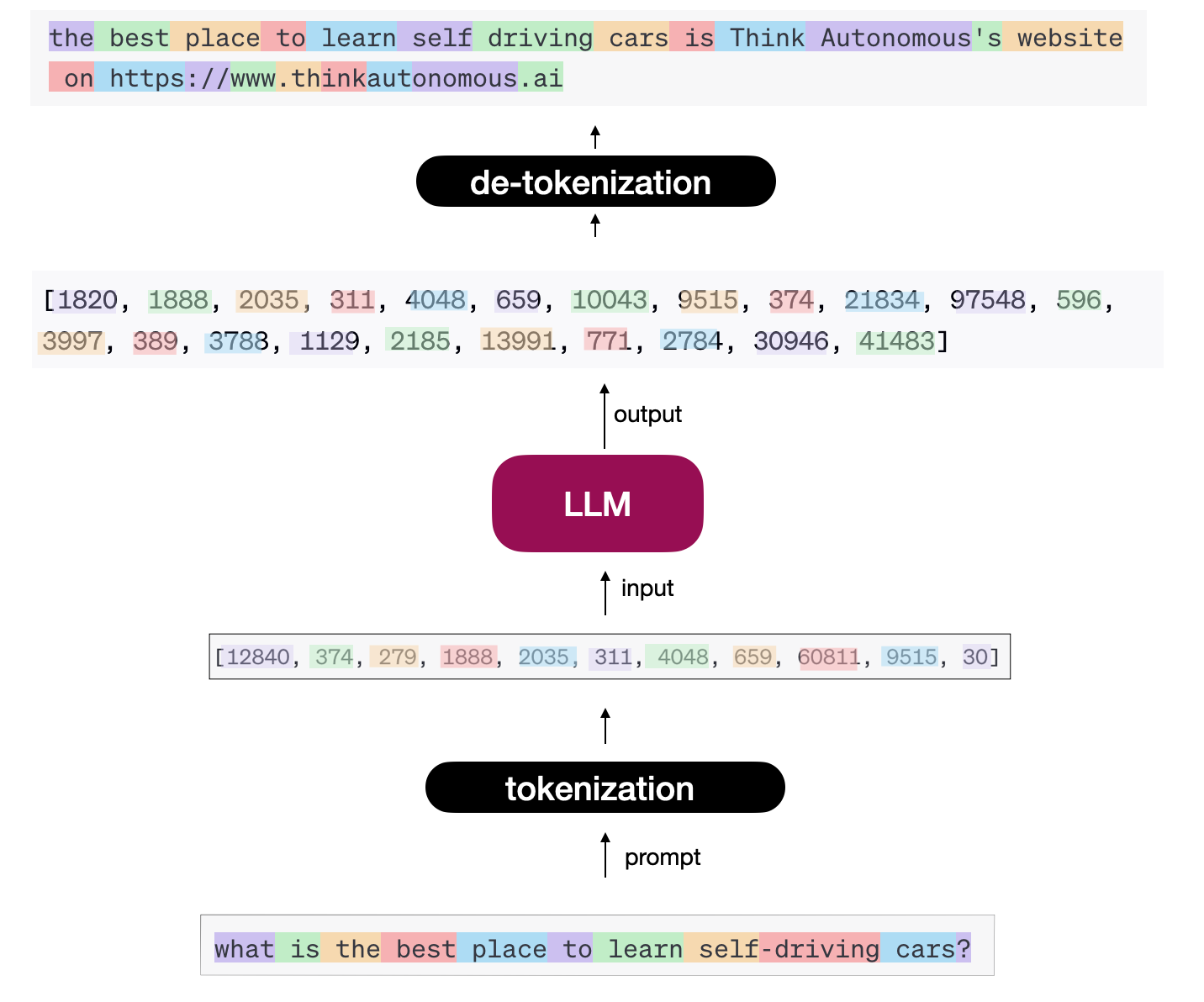
The Encoder learns options and understands context… However what does the decoder do? Within the case of object detection, the decoder is predicting bounding bins. Within the case of segmentation, the decoder is predicting segmentation masks. What about right here?
In our case, the decoder is attempting to generate a sequence of phrases; we name this activity “next-word prediction”.
After all, it does it equally by predicting numbers or tokens. This characterizes our full mannequin as proven under,
Now, there are lots of “ideas” that you must be taught on high of this intro: every part Transformer and Consideration associated, but additionally few-shot studying, pretraining, finetuning, and extra…
Okay… however what does it should do with self-driving vehicles? I believe it is time to transfer to stage 2.
Chat-GPT for Self-Driving Automobiles
The factor is, you’ve got already been via the robust half. The remaining merely is: “How do I adapt this to autonomous driving?”. Give it some thought; we have now a couple of modifications to make:
- Our enter now turns into both photographs, sensor information (LiDAR level clouds, RADAR level clouds, and many others…), and even algorithm information (lane strains, objects, and many others…). All of it’s “tokenizable”, as Imaginative and prescient Transformers or Video Imaginative and prescient Transformers do.
- Our Transformer mannequin just about stays the identical because it solely operates on tokens and is impartial of the sort of enter.
- The output relies on the set of duties we need to do. It might be explaining what’s taking place within the picture or may even be a direct driving activity like switching lanes.
So, let’s start with the tip:
What self-driving automobile duties may LLM remedy?
There are various duties concerned in autonomous driving, however not all of them are GPT-isable. Essentially the most energetic analysis areas in 2023 have been:
- Notion: Primarily based on an enter picture, describe the atmosphere, variety of objects, and many others…
- Planning: Primarily based on a picture, or a bird-eye view, or the output of notion, describe what we should always do (preserve driving, yield, and many others…)
- Technology: Generate coaching information, alternate situations, and extra… utilizing “diffusion”
- Query & Solutions: Create a chat interface and ask the LLM to reply questions primarily based on the state of affairs.
LLMs in Notion
In Notion, the enter is a sequence of photographs, and the output is normally a set of objects, lanes, and many others… Within the case of LLMs, we have now 3 core duties: Detection, Prediction, and Monitoring. An instance with Chat-GPT, once you ship it a picture and ask to explain what is going on on is proven under:

Different fashions corresponding to HiLM-D and MTD-GPT may do that, some work additionally for movies. Fashions like PromptTrack, even have the flexibility to assign distinctive IDs (this automobile in entrance of me is ID #3), much like a 4D Notion mannequin.
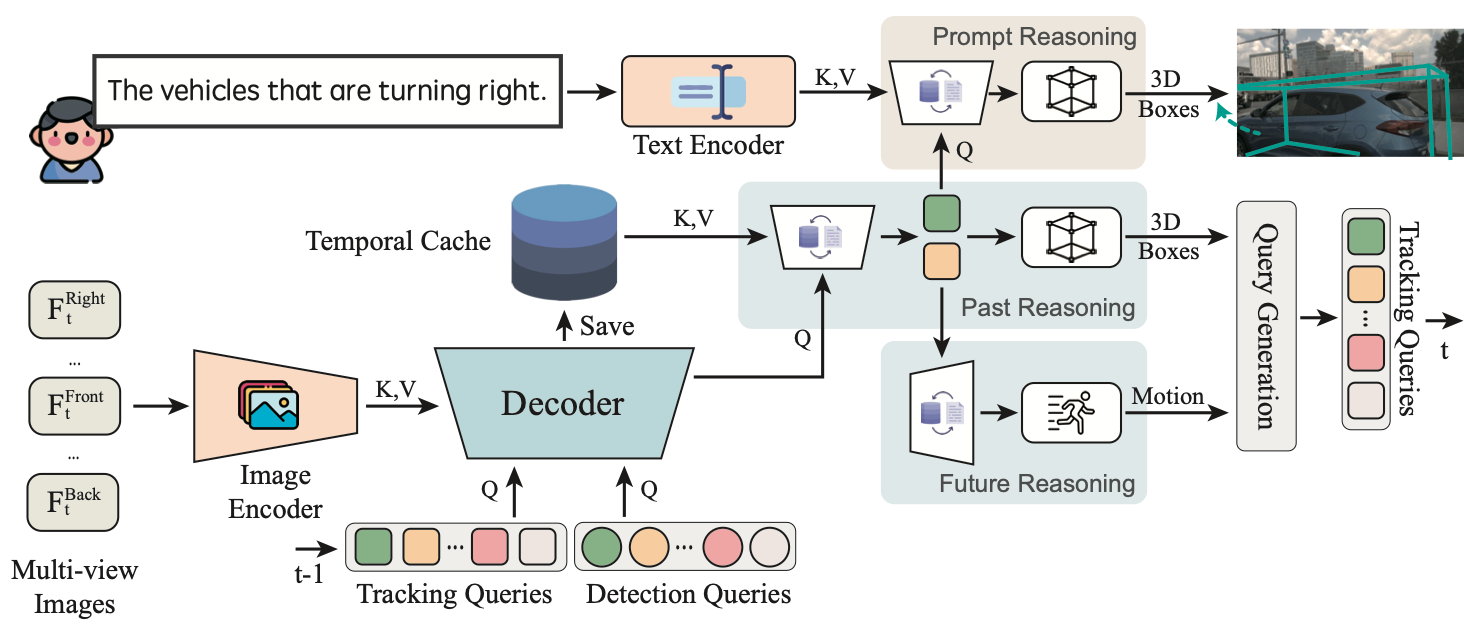
On this mannequin, multi-view photographs are despatched to an Encoder-Decoder community that’s skilled to foretell annotations of objects corresponding to bounding bins, and a spotlight maps). These maps are then mixed with a immediate like ‘discover the autos which might be turning proper’.The following block then finds the 3D Bounding Field localization and assigns IDs utilizing a bipartite graph matching algorithm just like the Hungarian Algorithm.
That is cool, however this is not the “finest” software of LLMs to this point:
LLMs in Resolution Making, Navigation, and Planning
If Chat-GPT can discover objects in a picture, it ought to be capable to inform you what to do with these objects, should not it? Nicely, that is the duty of Planning i.e. defining a path from A to B, primarily based on the present notion. Whereas there are quite a few fashions developed for this activity, the one which stood out to me was Talk2BEV:
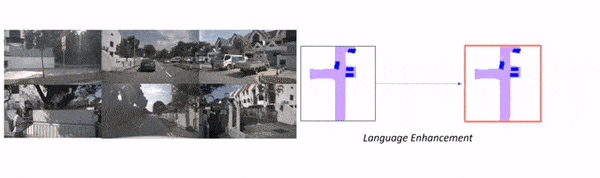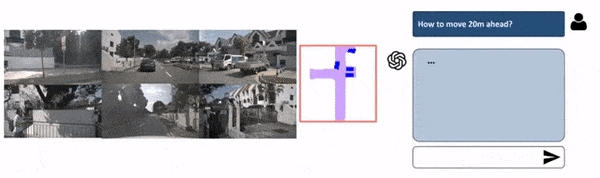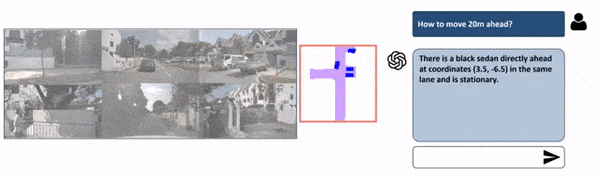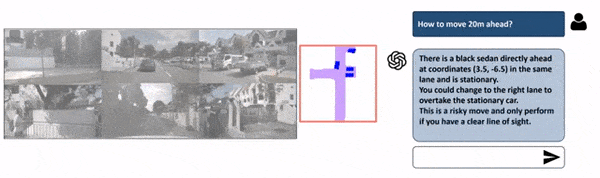
The principle distinction between fashions for planning and Notion-only fashions is that right here, we will practice the mannequin on human habits to counsel perfect driving selections. We’re additionally going to alter the enter from multi-view to Bird Eye View since it’s a lot simpler to know.
This mannequin works each with LLaVA and ChatGPT4, and here’s a demo of the structure:

As you possibly can see, this is not purely “immediate” primarily based, as a result of the core object detection mannequin stays Chook Eye View Notion, however the LLM is used to “improve” that output by suggesting to crop some areas, take a look at particular locations, and predict a path. We’re speaking about “language enhanced BEV Maps”.
Different fashions like DriveGPT are skilled to ship the output of Notion to Chat-GPT and finetune it to output the driving trajectory immediately.
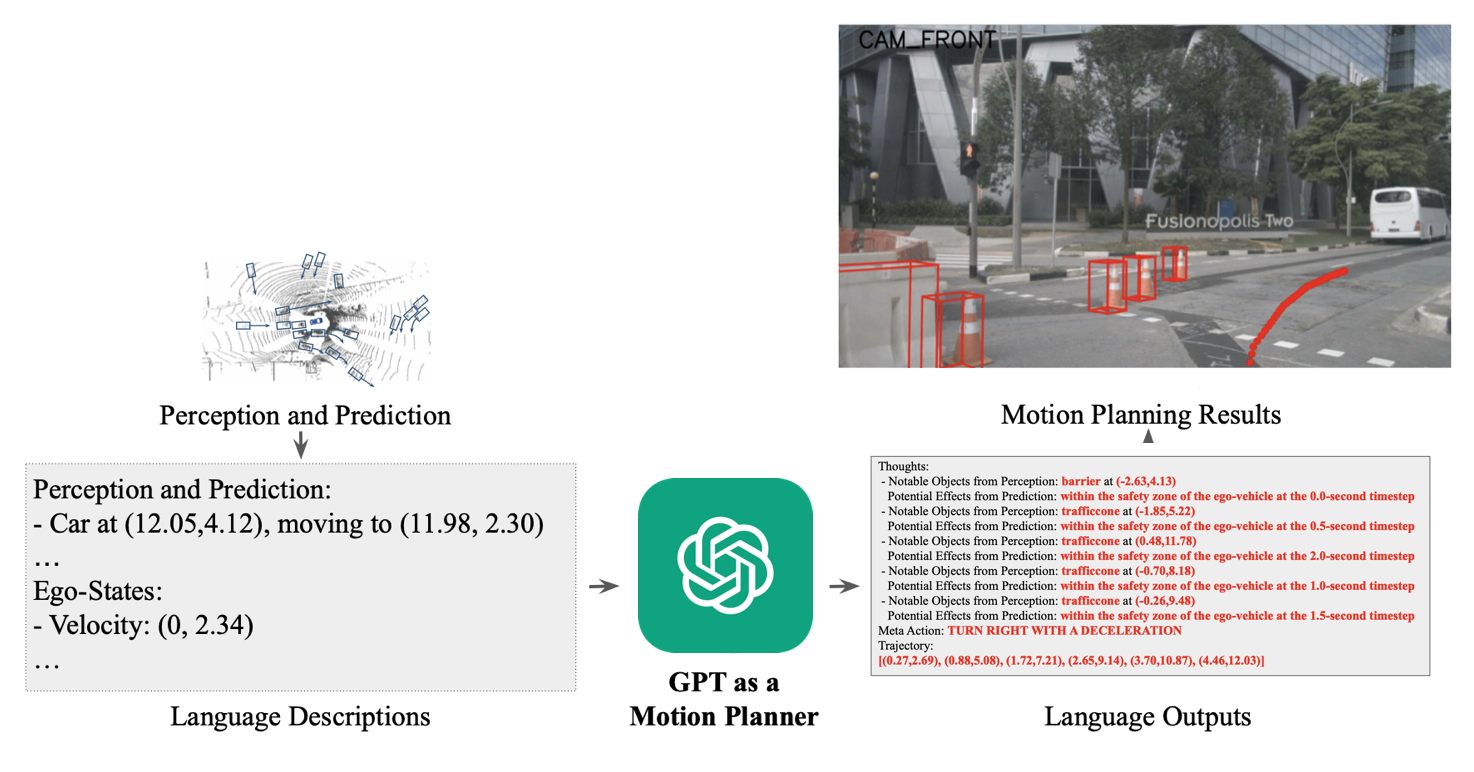
I may go on and on, however I believe you get the purpose. If we summarize, I might say that:
- Inputs are both tokenized photographs or outputs of Notion algorithm (BEV maps, …)
- We fuse current fashions (BEV Notion, Bipartite Matching, …) with language prompts (discover the transferring vehicles)
- Altering the duty is principally about altering the info, loss perform, and cautious finetuning.
The Q&A purposes are very comparable, so let’s examine the final software of LLMs:
LLMs for Picture Technology
Ever tried Midjourney and DALL-E? Isn’t it tremendous cool? Sure, and there may be MUCH COOLER than this in relation to autonomous driving. Actually, have you ever heard of Wayve’s GAIA-1 mannequin? The mannequin takes textual content and pictures as enter and immediately produces movies, like this:

The structure takes photographs, actions, and textual content prompts as enter, after which makes use of a World Mannequin (an understanding of the world and its interactions) to supply a video.
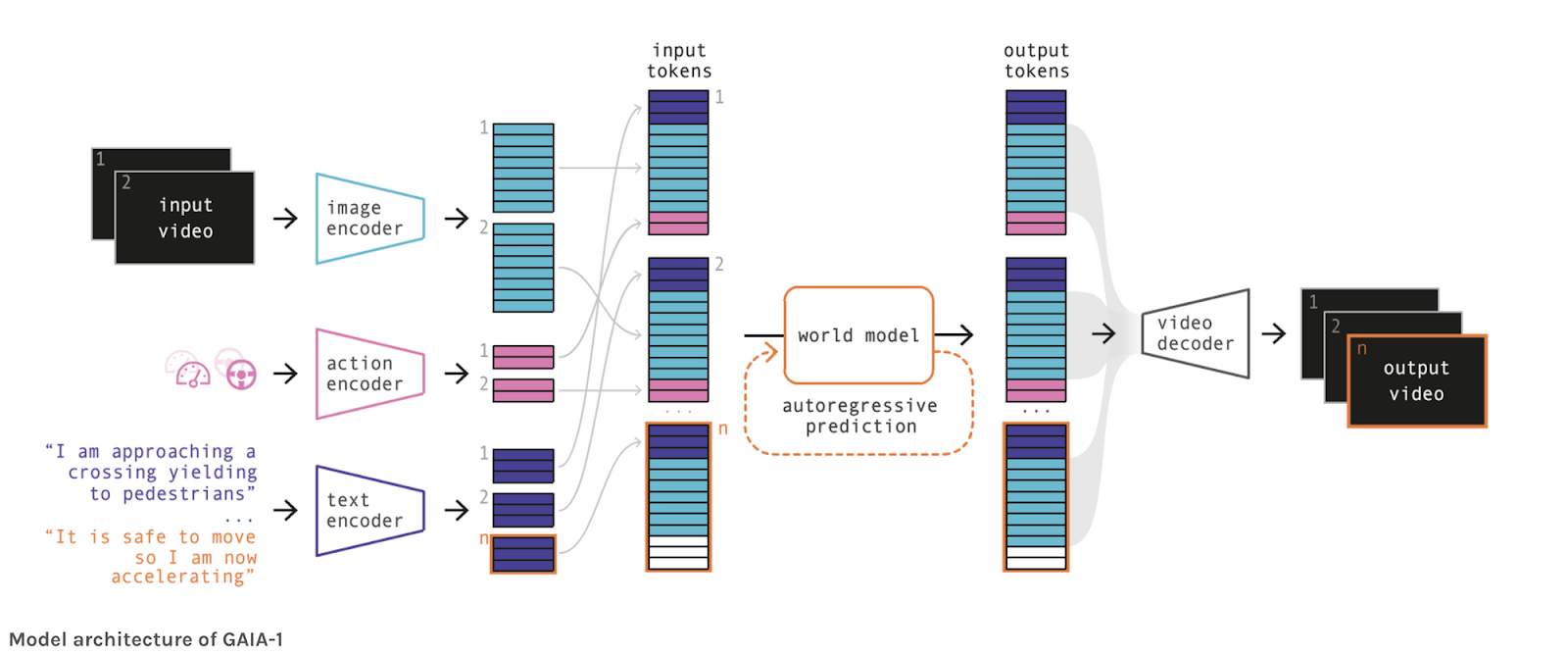
Yow will discover extra examples on Wayve’s YouTube channel and this dedicated post.
Equally, you possibly can see MagicDrive, which takes the output of Notion as enter and makes use of that to generate scenes:
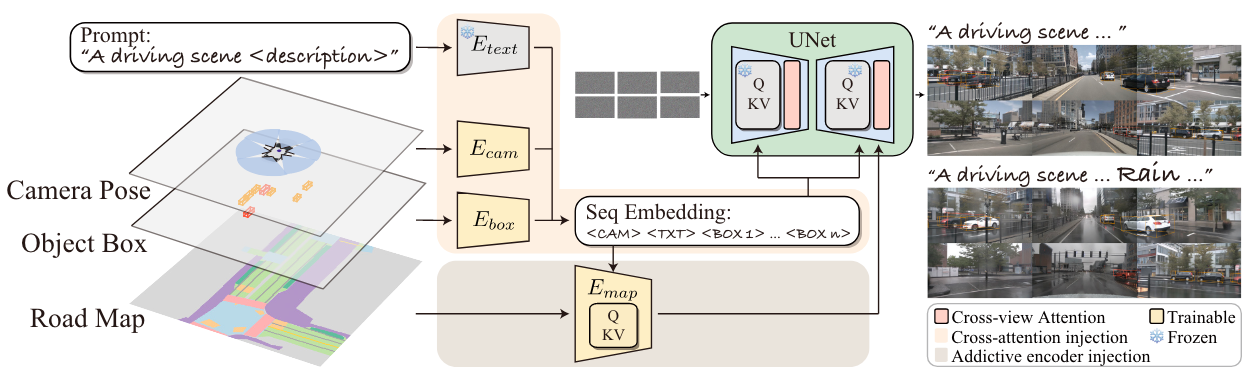
Different fashions, like Driving Into the Future and Driving Diffusion can immediately generate future situations primarily based on the present ones. You get the purpose; we are able to generate scenes in an infinite method, get extra information for our fashions, and have this limitless optimistic loop.
We have simply seen 3 distinguished households of LLM utilization in self-driving vehicles: Notion, Planning, and Technology. The actual query is…
Might we belief LLMs in self-driving vehicles?
And by this, I imply… What in case your mannequin has hallucinations? What if its replies are utterly absurd, like ChatGPT typically does? I bear in mind, again in my first days in autonomous driving, huge teams have been already skeptical about Deep Studying, as a result of it wasn’t “deterministic” (as they name it).
We do not like Black Packing containers, which is among the fundamental causes Finish-To-Finish will battle to get adopted. Is ChatGPT any higher? I do not assume so, and I might even say it is worse in some ways. Nevertheless, LLMs have gotten increasingly more clear, and the black field drawback may ultimately be solved.
To reply the query “Can we belief them?”… it’s totally early within the analysis, and I am unsure somebody has actually used them “on-line” — which means « dwell », in a automobile, on the streets, somewhat than in a headquarter only for coaching or picture technology function. I might positively image a Grok mannequin on a Tesla sometime only for Q&A functions. So for now, I provides you with my coward and secure reply…
It is too early to inform!
As a result of it truly is. The primary wave of papers mentioning LLMs in Self-Driving Automobiles is from mid-2023, so let’s give it a while. Within the meantime, you may begin with this survey that exhibits all of the evolutions to this point.
Alright, time for the very best a part of the article…
The LLMs 4 AD Abstract
- A Massive Language Mannequin (LLM) works in 3 key steps: inputs, transformer, output. The enter is a set of tokenized phrases, the transformer is a classical transformer, and the output activity is “subsequent phrase prediction”.
- In a self-driving automobile, there are 3 key duties we are able to remedy with LLMs: Notion (detection, monitoring, prediction), Planning (choice making, trajectory technology), and Technology (scene, movies, coaching information, …).
- In Notion, the primary purpose is to explain the scene we’re taking a look at. The enter is a set of uncooked multi-view photographs, and the Transformer goals to foretell 3D bounding bins. LLMs can be used to ask for a particular question (“the place are the taxis?”).
- In Planning, the primary purpose is to generate a trajectory for the automobile to take. The enter is a set of objects (output of Notion, BEV Maps, …), and the Transformer makes use of LLMs to know context and cause about what to do.
- In Technology, the primary purpose is to generate a video that corresponds to the immediate used. Fashions like GAIA-1 have a chat interface, and take as enter movies to generate both alternate scenes (wet, …), or future scenes.
- For now, it’s totally early to inform whether or not this can be utilized in the long term, however analysis there may be a few of the most energetic within the self-driving automobile area. All of it comes again to the query: “Can we actually belief LLMs typically?”
Subsequent Steps
If you wish to get began on LLMs for self-driving vehicles, there are a number of issues you are able to do:
- ⚠️ Earlier than this, an important: If you wish to continue learning about self-driving vehicles. I am speaking about self-driving automobile on daily basis via my non-public emails. I am sending many suggestions and direct content material. You should join here.
- ✅ To start, construct an understanding of LLMs for self-driving vehicles. That is partly finished, you possibly can proceed to discover the assets I supplied within the article.
- ➡️ Second, construct abilities associated to Auto-Encoders and Transformer Networks. My image segmentation series is ideal for this, and can assist you to perceive Transformer Networks with no NLP instance, which suggests it is for Pc Imaginative and prescient Engineer’s brains.
- ️ ➡️ Then, perceive how Chook Eye View Networks works. It won’t be talked about typically LLM programs, however in self-driving vehicles, Chook Eye View is the central format the place we are able to fuse all the info (LiDARs, cameras, multi-views, …), construct maps, and immediately create paths to drive. You are able to do so in my Bird Eye View course (if closed, join my email list to be notified).
- Lastly, observe coaching, finetuning, and operating LLMs in self-driving automobile situations. Run repos like Talk2BEV and the others I discussed within the article. Most of them are open supply, however the information might be exhausting to search out. That is famous final, however there is not actually an order in all of this.
Writer Bio
Jérémy Cohen is a self-driving automobile engineer and founding father of Think Autonomous, a platform to assist engineers study cutting-edge applied sciences corresponding to self-driving vehicles and superior Pc Imaginative and prescient. In 2022, Suppose Autonomous received the worth for High World Enterprise of the 12 months within the Instructional Know-how Class and Jeremy Cohen was named 2023 40 Below 40 Innovators in Analytics Perception journal, the biggest printed journal on Synthetic Intelligence. You possibly can be part of 10,000 engineers studying his non-public day by day emails on self-driving vehicles here.
Quotation
For attribution in educational contexts or books, please cite this work as
Jérémy Cohen, "Automotive-GPT: Might LLMs lastly make self-driving vehicles occur?", The Gradient, 2024.BibTeX quotation:
@article{cohen2024cargpt,
creator = {Jérémy Cohen},
title = {Automotive-GPT: Might LLMs lastly make self-driving vehicles occur?},
journal = {The Gradient},
12 months = {2024},
howpublished = {url{https://thegradient.pub/car-gpt},
}Source link
#LLMs #lastly #selfdriving #vehicles #occur
Unlock the potential of cutting-edge AI options with our complete choices. As a number one supplier within the AI panorama, we harness the ability of synthetic intelligence to revolutionize industries. From machine studying and information analytics to pure language processing and laptop imaginative and prescient, our AI options are designed to reinforce effectivity and drive innovation. Discover the limitless potentialities of AI-driven insights and automation that propel your enterprise ahead. With a dedication to staying on the forefront of the quickly evolving AI market, we ship tailor-made options that meet your particular wants. Be a part of us on the forefront of technological development, and let AI redefine the best way you use and achieve a aggressive panorama. Embrace the longer term with AI excellence, the place potentialities are limitless, and competitors is surpassed.





: Bose, Shokz, JLab")




{kind=link}