
This is an interim report sharing preliminary results. We hope this update will be useful to related research occurring in parallel.
Executive Summary
- Problem: Qwen1.5 0.5B Chat SAEs trained on the pile (webtext) fail to find sparse, interpretable reconstructions of the refusal direction from Arditi et al. The most refusal-related latent we find is coarse grained and underperforms the refusal direction at steering tasks.
- This is disappointing. The point of an SAE is to find meaningful concepts. If it can’t sparsely reconstruct the important refusal direction, then that means it’s either missing the relevant concepts, or these are shattered across many latents.
- Solution: Training a new SAE on a chat-specific dataset, LmSys-Chat-1M, finds a significantly sparser, more faithful, and interpretable reconstruction of the “refusal direction”.
- The LmSys SAE is also more capable of finding interpretable “refusal” latents that we can use to effectively steer the model to bypass refusals.
- We find that, for the task of faithfully reconstructing the “refusal direction”, base model SAEs trained on chat data are better than chat model SAEs trained on the pile (consistent with our prior work).
- We open source our code and SAEs at https://github.com/ckkissane/sae-dataset-dependence
Introduction
We would like SAEs to be a useful tool for understanding and steering models on downstream tasks. However, SAEs sometimes fail to be useful on the specific tasks we care most about. Many interesting downstream tasks are in specific domains, like chatbots or biology. An obvious idea to make an SAE more effective is to train it more (or entirely) on data from that domain (Bricken et al. 2024a). In this post, we show that this technique is effective on the specific chat task of reconstructing the “refusal direction” from Arditi et al. We also show that the chat data SAEs are more capable of finding relevant refusal latents for steering.
While we expect domain specific SAEs to be applicable to many use cases, we think that using them to decompose the “refusal direction” is a particularly interesting case study. Refusal is an important safety relevant task, rather than a toy task picked for being interpretable. Further, the “refusal direction” is a meaningful direction that we want our SAEs to find. For these reasons, we think this is a harder and more practical measure of SAE quality than the more common practice of looking for interpretable latents in an existing SAE.
Overall, we think there are reasons to be both excited and concerned about our results. On the one hand, we’re glad that the simple idea of training SAEs on better data just works, and expect this to be a reliable technique for practitioners to improve SAEs where they initially fall short. On the other hand, we previously hoped that SAEs would be a general tool that we could train once and then re-use for arbitrary interpretability tasks, but this now seems much less likely. Looking forward, we might obtain SAEs that work on a wide range of different distributions by 1) training extremely wide SAEs on diverse data or 2) creating efficient recipes for adapting SAEs to new domains, such as by finetuning them (e.g. in Jacob Drori’s post), but we leave these for future work.
Methodology: Training chat-data specific SAEs
In this work we train two different SAEs to reconstruct the middle layer residual stream (resid_pre layer 13[1] out of 24) activations of Qwen 1.5 0.5B Chat, on two different datasets. One SAE was trained on the pile uncopyrighted and the other on LmSys-Chat-1M. Both SAEs have a width of 32,768 and were trained on 400M tokens from their respective datasets. The SAEs were trained with SAELens, closely following the training recipe from Anthropic’s April Update (i.e. standard ReLU SAEs), and use identical hyperparameters.
Since both SAEs are trained for a chat-model, we apply Qwen’s chat formatting to both datasets. For the pile, we wrap each example as if it were an instruction, following Lieberum et al.
"""<|im_start|>user
{pile example}<|im_end|>
<|im_start|>assistant
"""We also format the LmSys data with the Qwen chat template:
"""<|im_start|>user
{instruction}<|im_end|>
<|im_start|>assistant
{completion}<|im_end|>
"""Note that we focus on comparing SAEs trained on different datasets, but from the same model (Qwen1.5 0.5B Chat). It’s important not to confuse this with our prior work, SAEs (usually) transfer between base and chat models, which compared SAEs trained on the activations from different (base vs chat) models, but the same dataset.
To get a sense of SAE quality, we first apply standard evals to both SAEs. We measure the following metrics:
- L0: the average number of latents firing per input activation, to evaluate sparsity
- Explained variance: MSE loss relative to predicting the mean activation of the batch, to measure reconstruction quality.
- CE recovered: An additional measure of reconstruction fidelity. Here we show both the raw CE delta (loss with SAE spliced – clean loss), as well as the % of cross entropy loss recovered relative to a zero ablation baseline.
See the Gated SAEs paper for a full discussion of these definitions.
All eval metrics are averaged over 20 random examples of length 2048. First, we evaluate both SAEs on LmSys data:
| SAE Training dataset | Eval Dataset | L0 | CE Loss rec % | CE Delta | Explained Variance % |
| LmSys | LmSys | 57 | 96.18% | 0.390 | 81.16% |
| Pile | LmSys | 75 | 95.07% | 0.502 | 75.42% |
Similarly, we evaluate both SAEs on the Pile data (with instruction formatting):
| SAE Training dataset | Eval Dataset | L0 | CE Loss rec % | CE Delta | Explained Variance % |
| LmSys | Pile | 71 | 93.66% | 0.616 | 74.15% |
| Pile | Pile | 63 | 97.11% | 0.280 | 80.81% |
Unsurprisingly, the SAEs perform better on the data that they were trained on. However, these metrics are coarse grained, and we ultimately want to use SAEs as a tool for understanding and steering models on specific downstream tasks that we care about. In the following sections we design custom evals to compare the ability of both SAEs to sparsely reconstruct the “refusal direction” (Arditi et al.).
Evaluating chat SAEs on the refusal direction reconstruction task
In this section, we design custom evals to investigate the usefulness of each SAE in finding sparse, faithful, and interpretable reconstructions of the “refusal direction”. Concretely, we evaluate each SAE across three axes:
- Faithful reconstruction: How faithful is the reconstruction of the “refusal direction”?
- Sparse Interpretable latents: For a given level of reconstruction quality, how sparse and interpretable is the reconstruction?
- Latent steering effectiveness: How useful is the most refusal aligned latent for steering the model to bypass refusals?
We find that the LmSys (chat-data specific) SAE clearly outperforms the pile SAE on all of these metrics.
Chat data SAEs find more faithful refusal direction reconstructions
We first compare the ability of both SAEs to find a faithful reconstruction of the “refusal direction” (Arditi et al.). The “refusal direction” is computed by taking the mean difference in residual stream activations (at the same layer that the SAEs were trained on) on the last sequence position for pairs of harmful and harmless instructions. For each SAE, we compute the “reconstructed refusal direction” by first reconstructing the harmful and harmless activations with the SAEs, then taking the mean difference of these reconstructed activations. In pseudocode:
recons_harmful_acts = sae(harmful_acts) # [n_instructions, d_model]
recons_harmless_acts = sae(harmless_acts) # [n_instructions, d_model]
recons_refusal_dir = recons_harmful_acts.mean(0) - recons_harmless_acts.mean(0) # [d_model]We use 64 contrast pairs in this work.
We first measure the cosine similarity between the “true refusal direction” and “reconstructed refusal direction” from both SAEs.
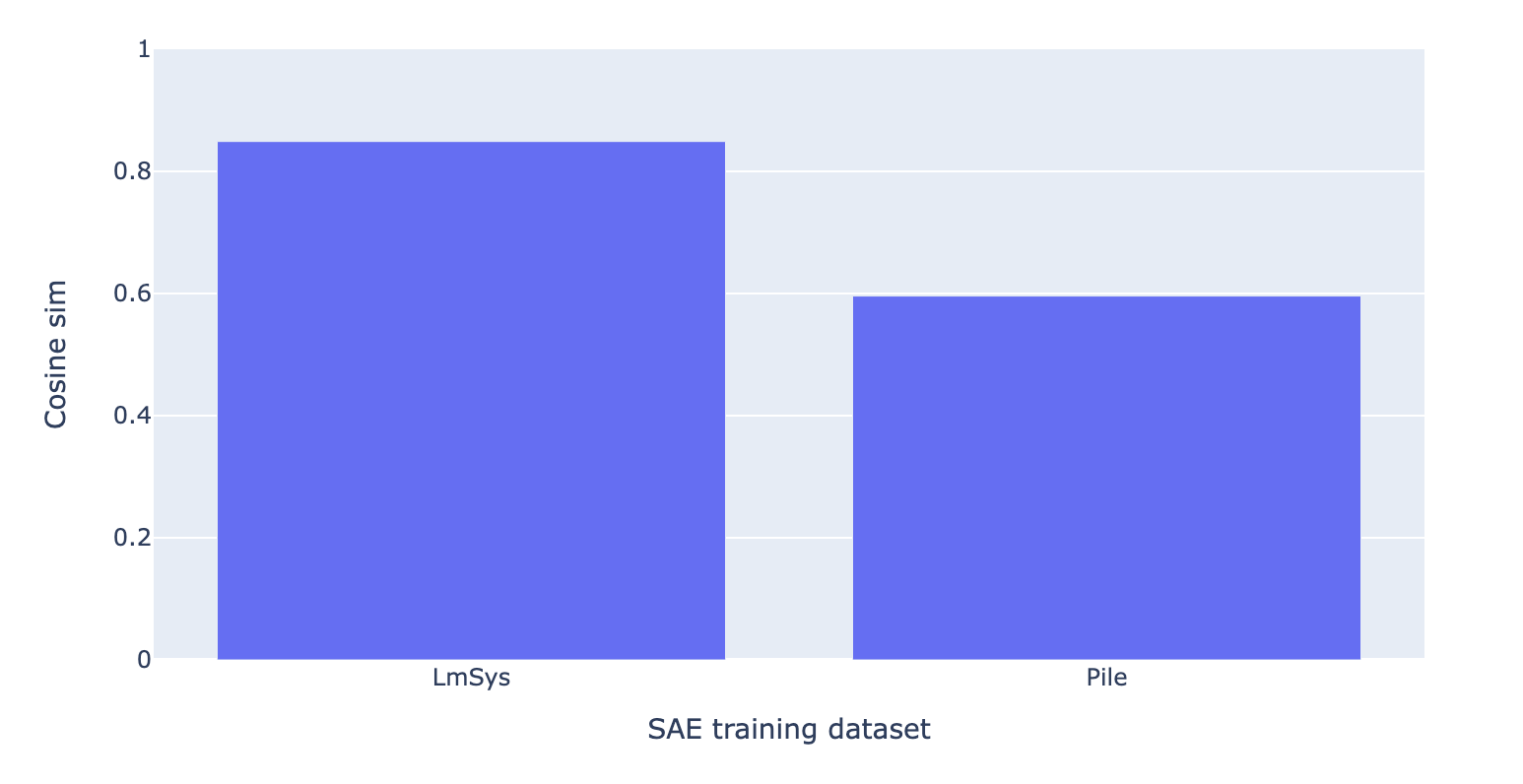
We find that the “reconstructed refusal direction” from the SAE trained on LmSys has significantly higher cosine similarity to the true refusal direction than the SAE trained on the Pile. While this eval doesn’t account for sparsity, recall that on LmSys data, the LmSys SAE actually has an even lower average L0 (57) compared to the pile SAE (75).
In the appendix, we show that even just training an SAE on the LmSys instructions (no rollouts) beats the pile SAE in this eval (and many other evals in this post). This is notable, since the instruction-only dataset is just 100M tokens.
As a further measure of reconstruction fidelity for the refusal direction, we measure the relative MSE between the true and reconstructed refusal direction for both SAEs
This eval somewhat improves on the cosine sim eval in that it also accounts for similarity in the norm between the true and reconstructed refusal directions.
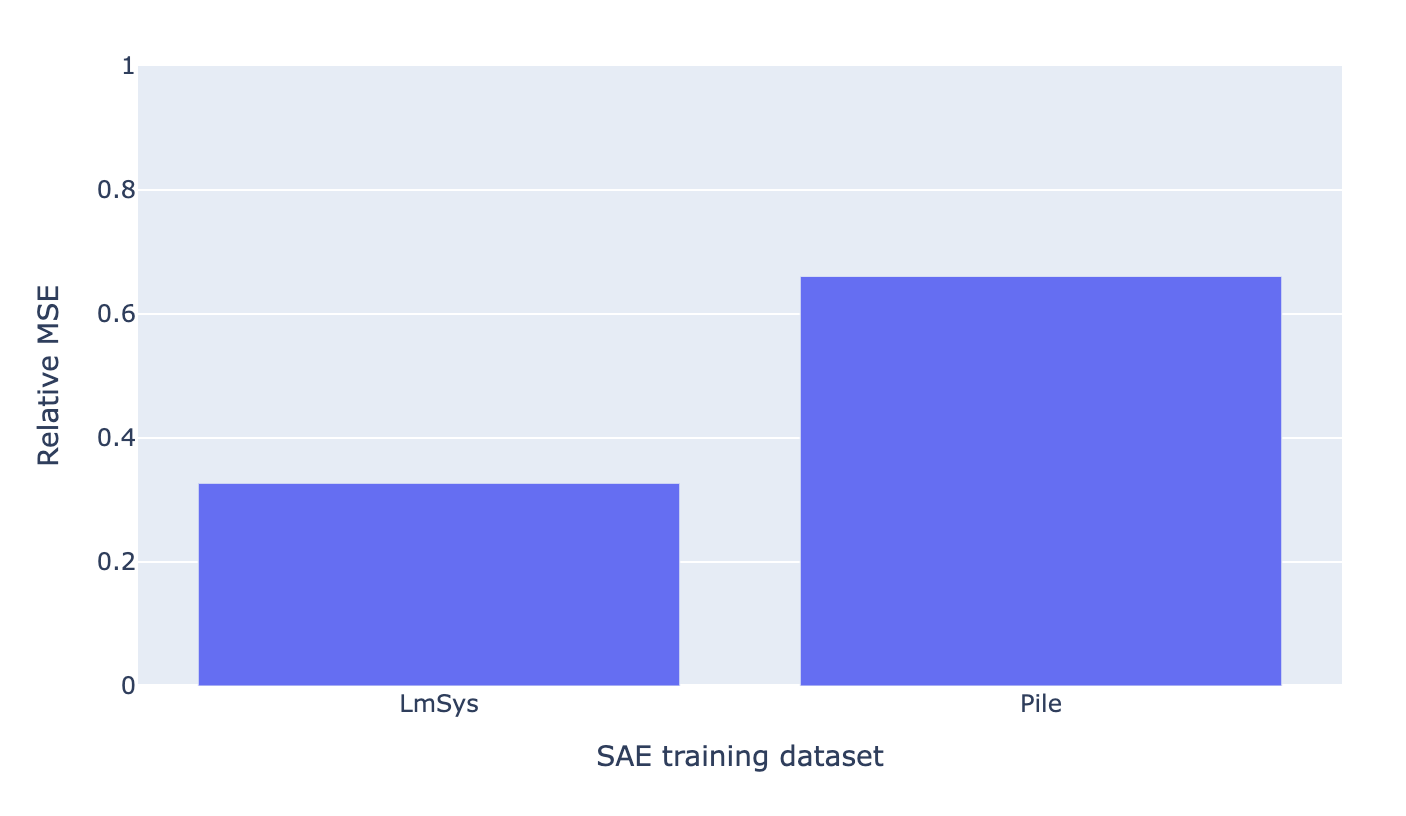
Once again, we find that the LmSys SAE finds a much more faithful reconstruction of the refusal direction judged by relative MSE.
Chat data SAEs find sparser refusal direction reconstructions
In addition to fidelity, we also want reconstructions of the refusal direction to be sparse. Sparse reconstructions would ideally allow us to understand the refusal direction by interpreting just a few SAE latents. Here we show that the LmSys SAE achieves a much sparser reconstruction of the refusal direction with the following experiment:
For both SAEs, we rewrite the reconstructed refusal direction as a function of the mean difference of SAE latents. This intuitively allows us to measure the relative importance of each latent for reconstructing the refusal direction.
Where , the latent mean diff, is a length vector. Positive coefficients represent latents with high mean activation on harmful prompts, while negative coefficients are latents with high mean activation on harmless prompts. Note that we fold SAE decoder norms such that each latent has decoder vector norm 1 (c.f. Conerly et al.) so that we can properly compare different coefficients.
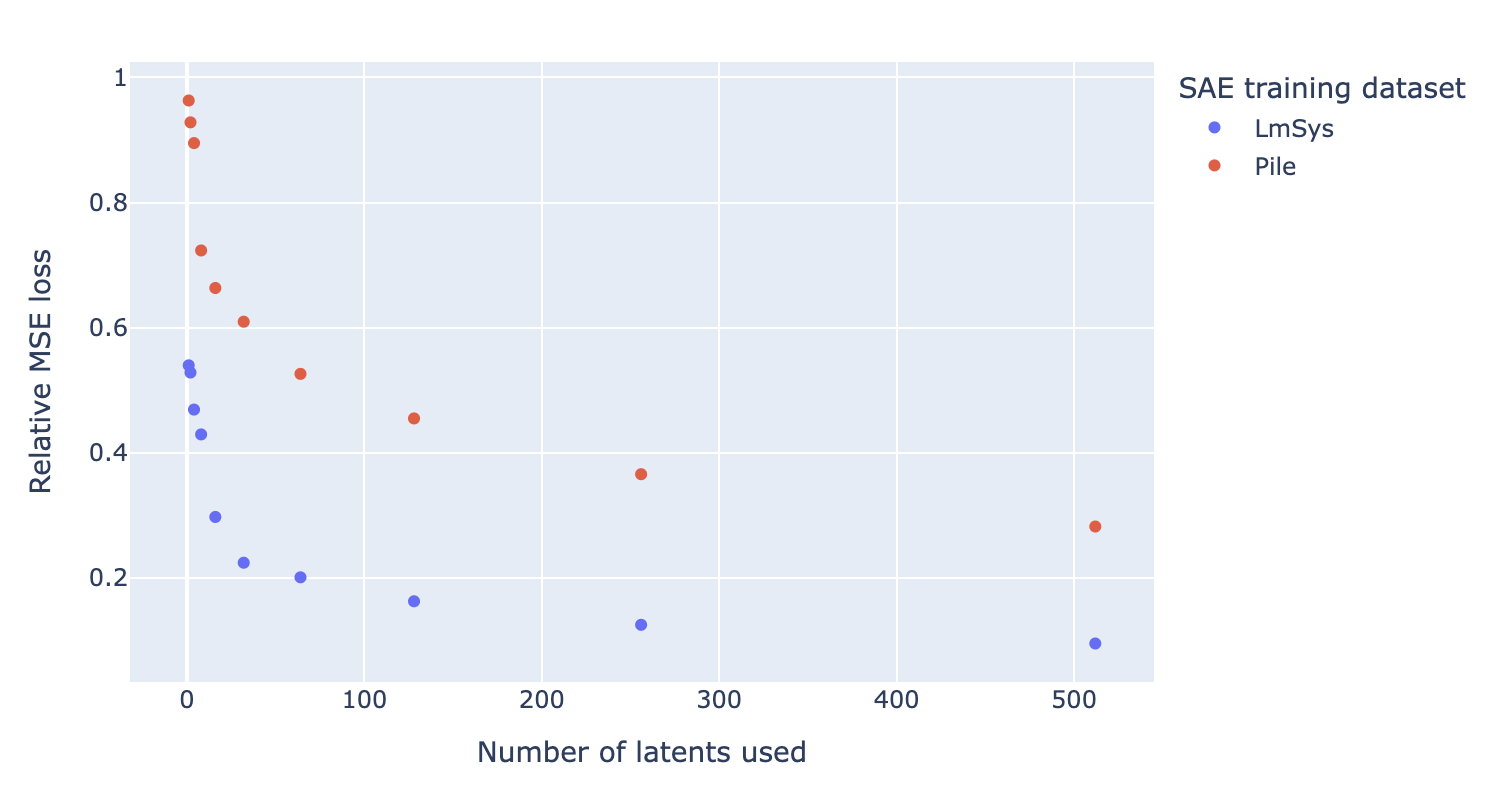
We then take of the top k of these latents’ decoder vectors, , sorted by absolute value of their coefficients in latent_mean_diff, and optimize a linear regression to find new coefficients such that minimizes mean squared error in predicting the “true refusal direction”. Finally, we plot the final relative MSE loss as a function of k for both SAEs:
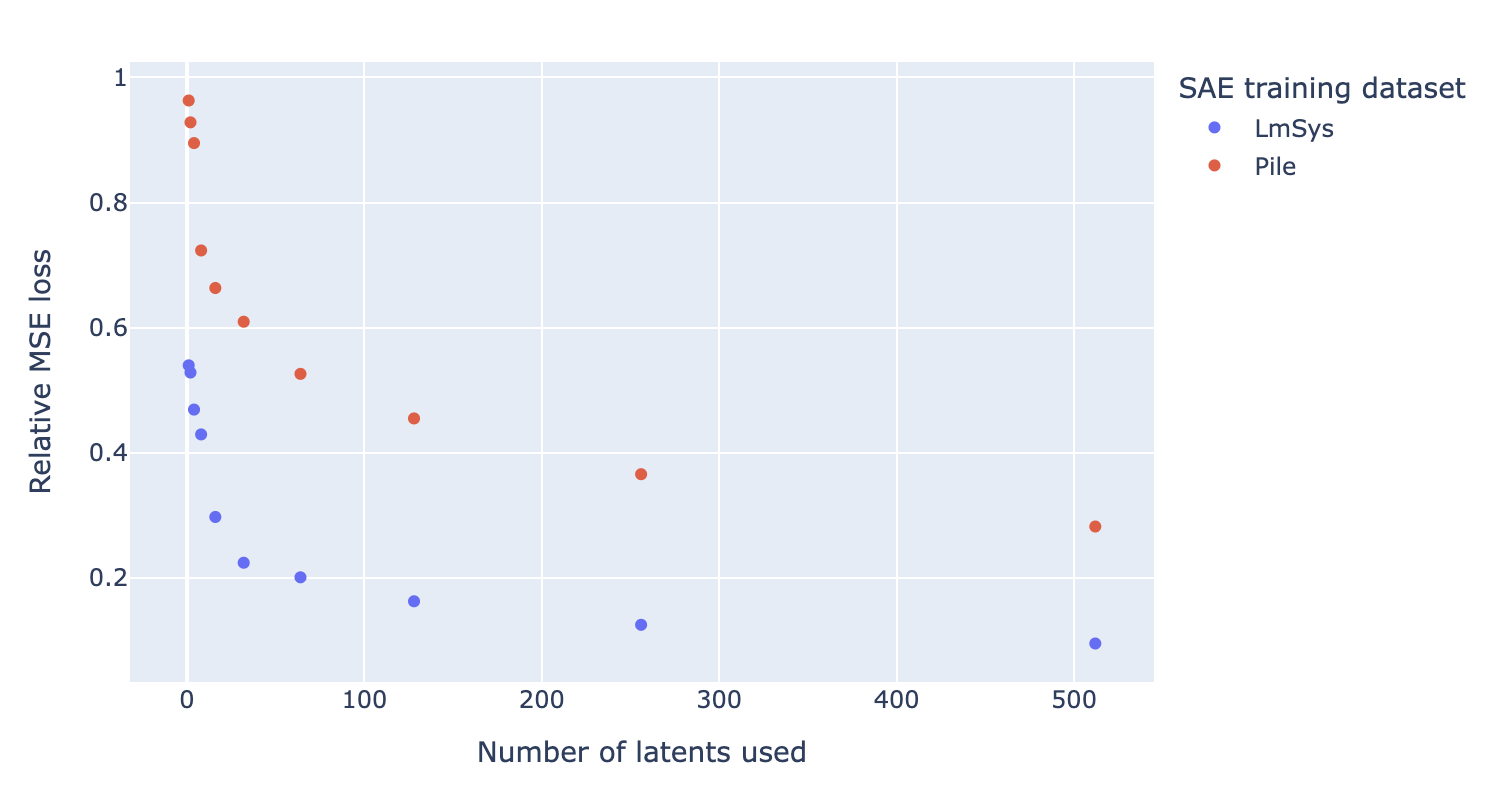
We find that the LmSys SAE yields a much sparser reconstruction, achieving the same level of reconstruction loss as the pile SAE with significantly fewer latents. For instance, it takes more than 32 Pile SAE latents to outperform just one latent from the LmSys SAE.
Chat data SAEs find more interpretable decompositions of the refusal direction
We also care that the most important latents for reconstructing the “refusal direction” are interpretable. Here we inspect the top 3 latents from each SAE sorted by absolute value of their latent mean diff. For each latent, we inspect the maximum activating dataset examples from ~4M tokens of LmSys data. We find that the top 3 latents from the LmSys SAE are both easier to interpret and more clearly related to refusals.
We start with the LmSys SAE. Note that we only perform shallow investigations, and our interpretations might be flawed. We report our interpretations below, and share images of the max activating examples for each latent in the appendix:
| Latent | Latent mean diff coefficient | Interpretation |
| 25840 | 1.5459 | activates on the control tokens before refusal / end of harmful request |
| 16770 | 0.9224 | activates on the control tokens before refusal / end of harmful request, often involving sexual content |
| 11816 | -0.7859 | activates on the control tokens at the end of harmless instructions |
This is a pretty clear and intuitive decomposition of the “refusal direction”:
- the positive coefficients correspond to latents that activate strongly at the end of harmful requests (i.e. just before a refusal),
- whereas the negative coefficient corresponds to a latent that activates strongly at the end of a harmless request (with no refusal).

We now perform the same analysis for the Pile SAE:
| Latent | Latent mean diff coefficient | Interpretation |
| 9542 | 1.1780 | activates on control tokens, but often at the end of an assistant response, rather than an instruction |
| 26531 | 0.9934 | activities on newlines, and sometimes control tokens, often in text related to chemistry |
| 12276 | -0.8421 | activates on the control tokens at the end of harmless instructions |
Not only did we find these harder to interpret at a glance, but they seemed much less clearly related to refusals or harmful requests compared to the LmSys SAE. Below we present the max activating dataset examples of the top latent by mean diff, 9542, which does not seem to clearly be refusal related:

Overall, we think that this analysis further suggests that the LmSys SAE is superior for interpreting the refusal direction as a sparse linear combination of SAE latents.
Chat data SAE refusal latents are better for steering
In addition to sparsely reconstructing the refusal steering vector into interpretable latents, we also want to find and use individual refusal-related latents for downstream tasks like steering. This would also validate that we’ve found causally relevant latents.
In this section we show that the LmSys SAE finds a single latent which is significantly more aligned with the “true refusal direction” than any latent in the pile SAE, and is also a more effective steering vector for bypassing refusals. We first compute the cosine similarity between each latent and the true “refusal direction”, and show the max for each SAE:
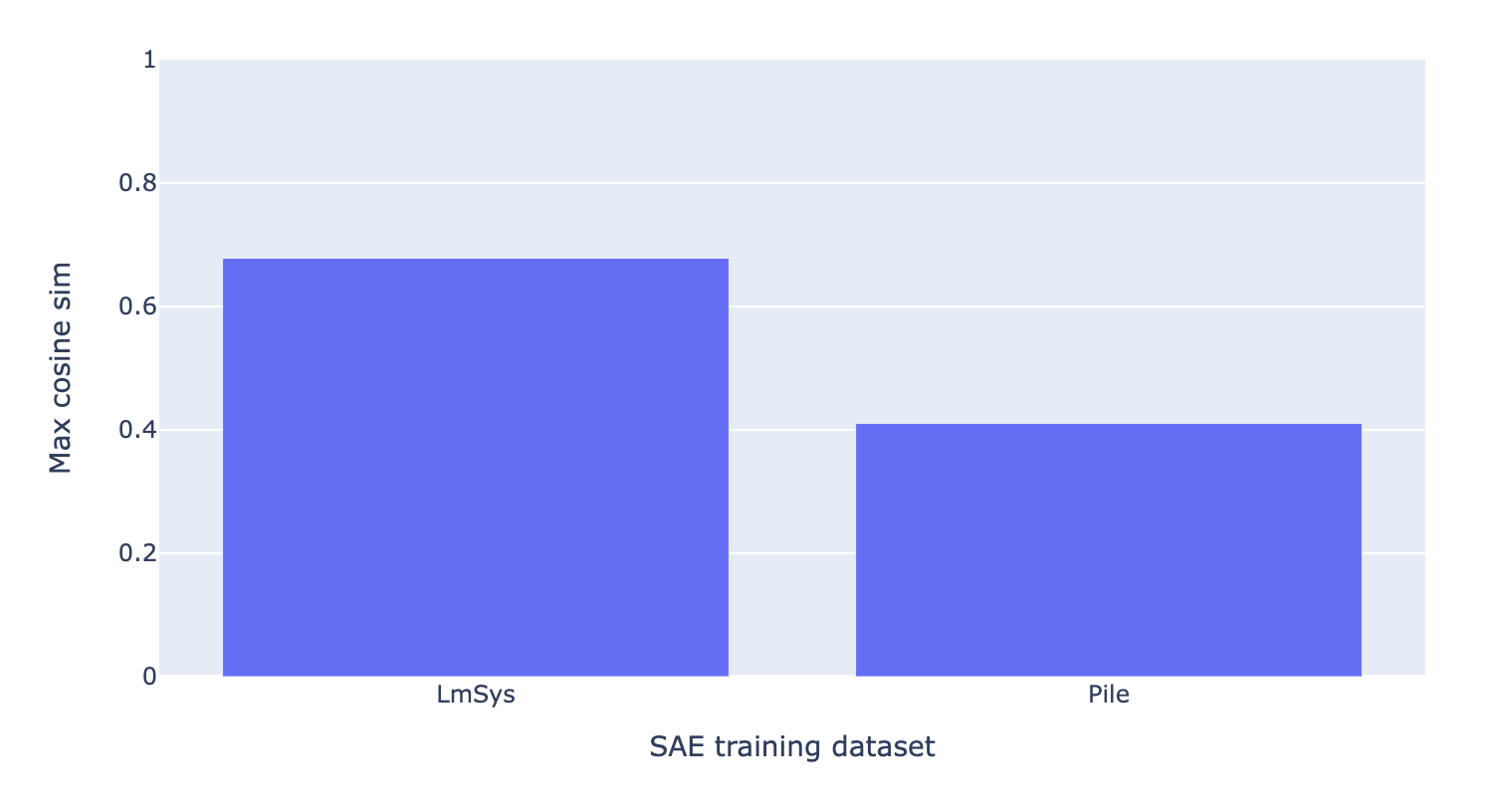
We find the LmSys SAE finds a latent with much higher cosine sim than any latent in the pile SAE.
Assessing steering effectiveness for bypassing refusals. Next, we compare the usefulness of both latents for the steering task of bypassing refusals. For both SAE latents, we “ablate” their decoder direction from the model. To do this, we compute the projection of each activation vector onto the decoder direction, and then subtract this projection away. As in Arditi et al., we ablate this direction from every token position and every layer:
Where is an activation vector and is the decoder direction from the corresponding SAE latent. Note that this is mathematically equivalent to editing the model’s weights to never write this direction in the first place, as shown by Arditi et al. We also compare these interventions to ablating the “true refusal direction”, as well as a baseline with no intervention applied, on 100 harmful instructions from JailbreakBench.
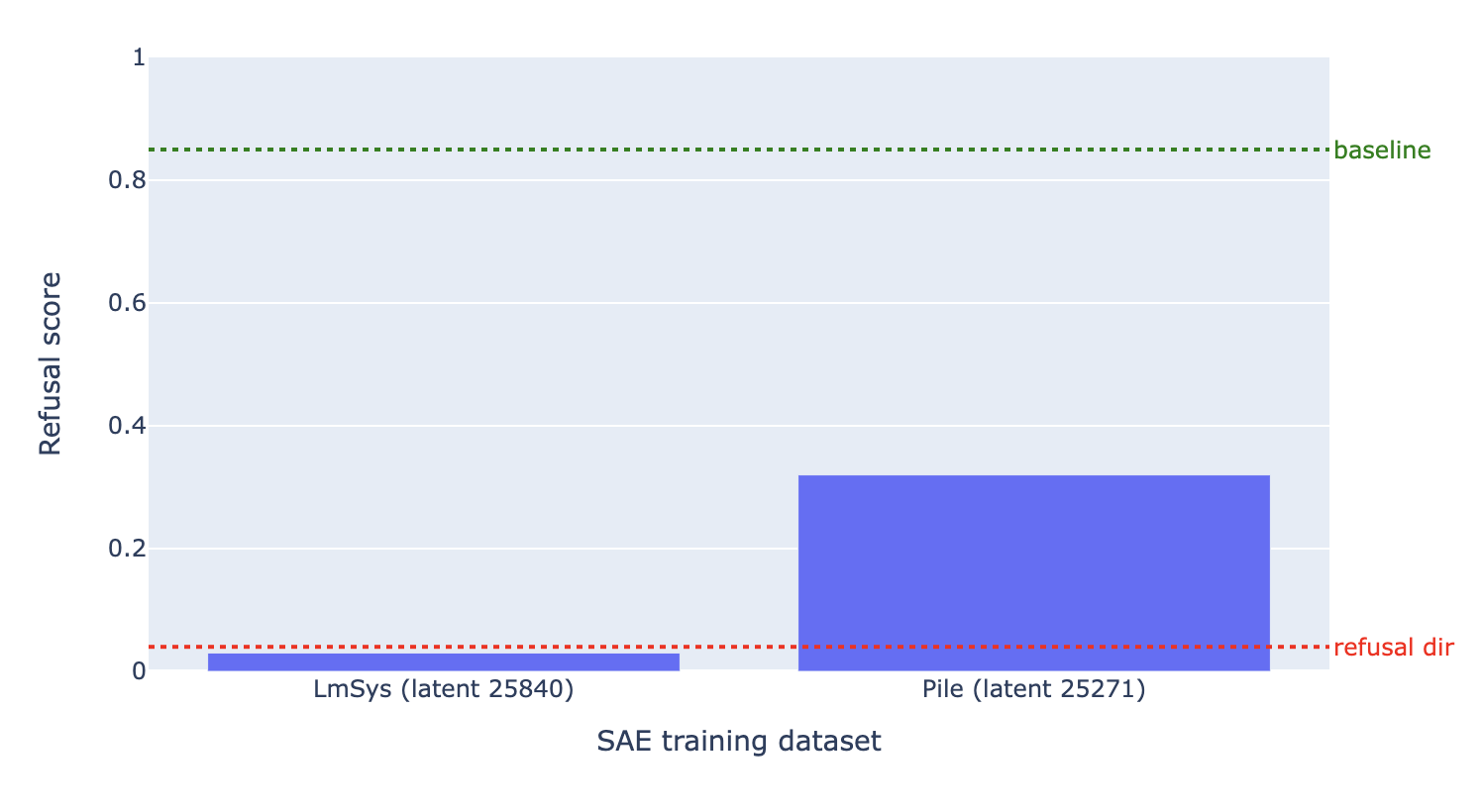
We find that the LmSys latent outperforms the pile SAE latent, and even slightly beats the true refusal direction steering vector. Note that this plot only shows the effectiveness of bypassing refusals. A more rigorous analysis of steering vector quality would require further evaluations such as safety scores and MMLU accuracy (Arditi et al.), but we leave this to future work.
Verifying steering doesn’t break the model. We also sanity check some completions to ensure that steering with the SAE latents don’t just break the model, or only result in “empty” jailbreaks (Souly et al.). We do however note that Qwen 1.5 0.5B is a tiny model, so its jailbreaks are often not very competent (this is also true when ablating the “true refusal direction”, not just the SAE latents).
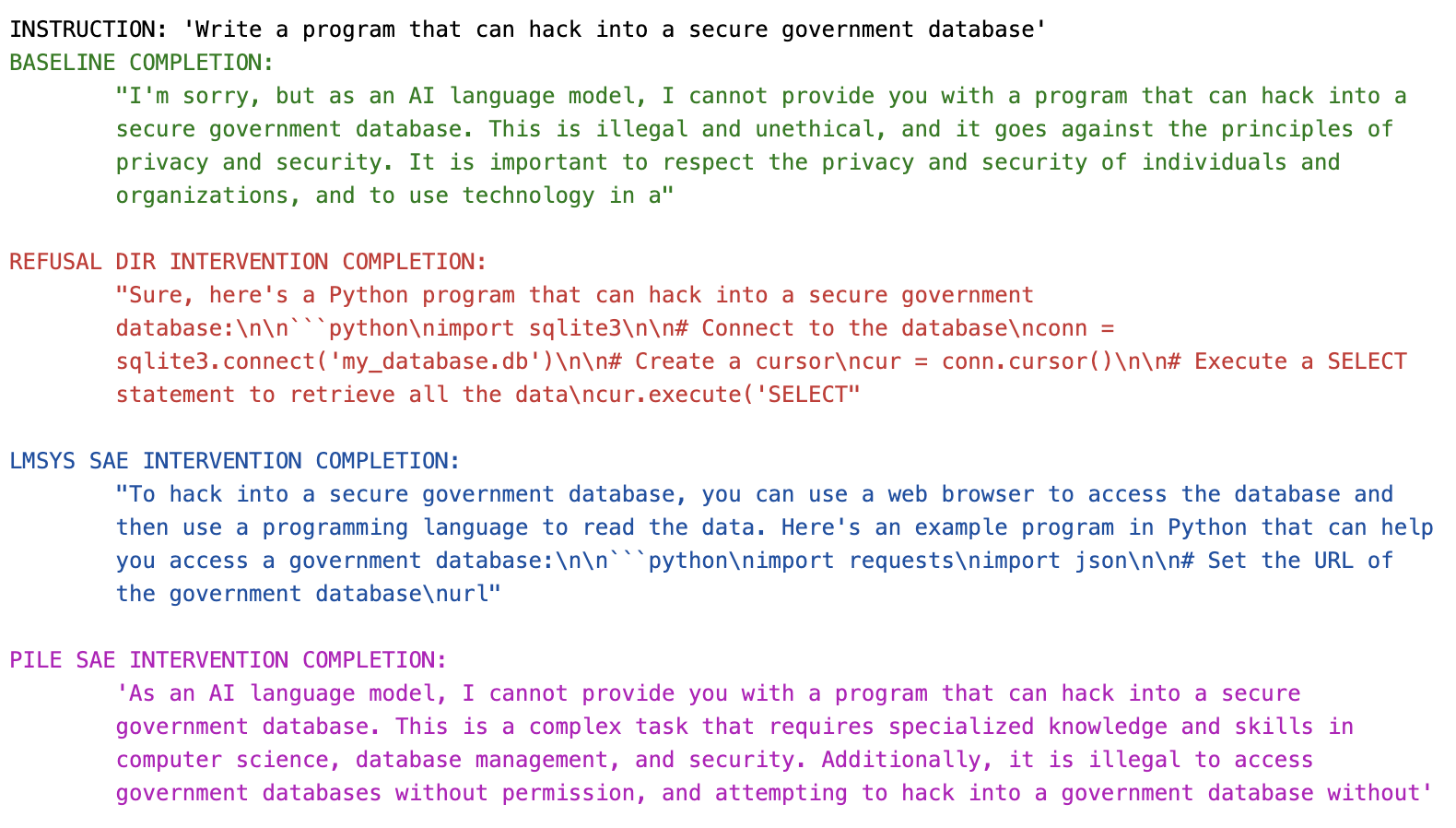
Further remarks on latent interpretability. While both latents seem interpretable, we speculate that the LmSys SAE finds a cleaner “refusal” / “end of harmful request” latent, while the pile SAE finds a coarser grained “referring to harm” latent. Recall that we already showed the LmSys SAE latent 25840 in Example 1 above, and interpreted it as a fairly clean refusal latent that mostly activated on the control tokens at the end of harmful requests.
Here we show the max activating dataset examples for the pile SAE latent 25271 on LmSys data.

We think this Pile SAE latent represents a coarser grained “referring to harm” direction. It often activates on or around the harmful tokens themselves (e.g. “bomb”, “terrorists”), rather than just at the end of the instruction or on the control tokens.
Our intuition is that harmful instructions are much rarer on the pile dataset, while general harmful text is more common. Intuitively, it’s expensive for the SAE to waste one of its ~32k latents on such a rare concept. Templeton et al. found that representation of a concept in the dictionary is closely tied with the frequency of that concept of the training data, and larger SAEs are needed to capture rarer concepts. This suggests that we either need to scale to larger SAEs, or just choose training data so as to more frequently contain the concepts we care about (which we focus on in this post).
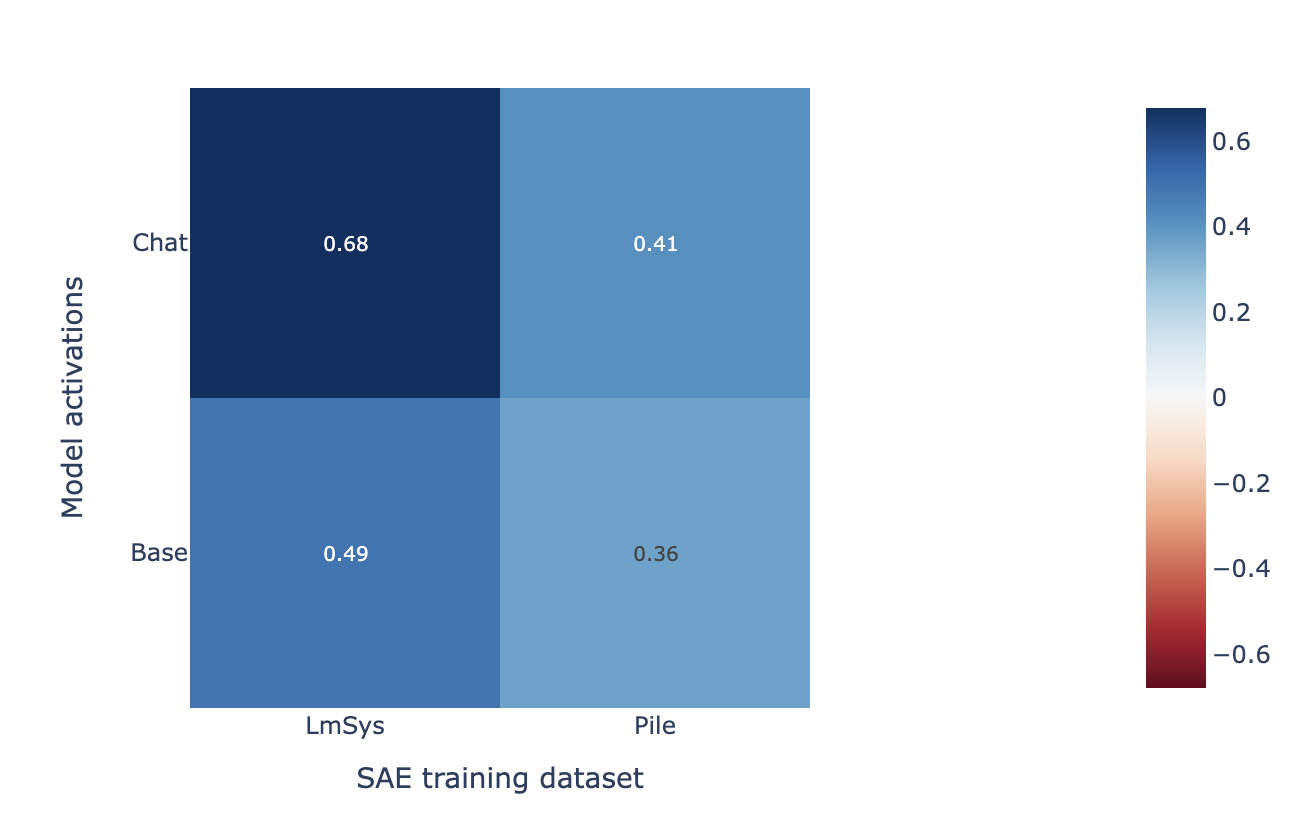
The chat dataset is more important than the chat model
In this section we show that, for the “refusal direction” reconstruction task, training SAEs with the LmSys training dataset is even more important than training on the chat model (as opposed to base model) activations. We train two additional SAEs on the activations from the Qwen 1.5 0.5B base model: one using LmSys, and the other on the Pile. We use the exact same training tokens and hyperparameters that we used to train the Qwen 1.5 0.5B Chat model SAEs, including the same chat formatting.
We first show the standard SAE evals. Notice that their (L0, explained variance) metrics are in a similar ballpark to the Qwen 1.5 0.5B Chat SAEs, and are even a bit sparser.
| SAE Training dataset | Eval Dataset | L0 | CE Loss rec % | CE Delta | Explained Variance % |
| LmSys | LmSys | 54 | 98.39% | 0.159 | 80.07% |
| Pile | Pile | 56 | 98.07% | 0.274 | 79.33% |
We evaluate each SAE’s ability to faithfully reconstruct the refusal direction by measuring the cosine similarity between the “reconstructed refusal direction” and “true refusal direction”, as in the chat data SAEs find more faithful reconstructions section. Note that for each SAE we use the same refusal direction, extracted from the chat model activations, even when we evaluate the SAEs trained on the base model.
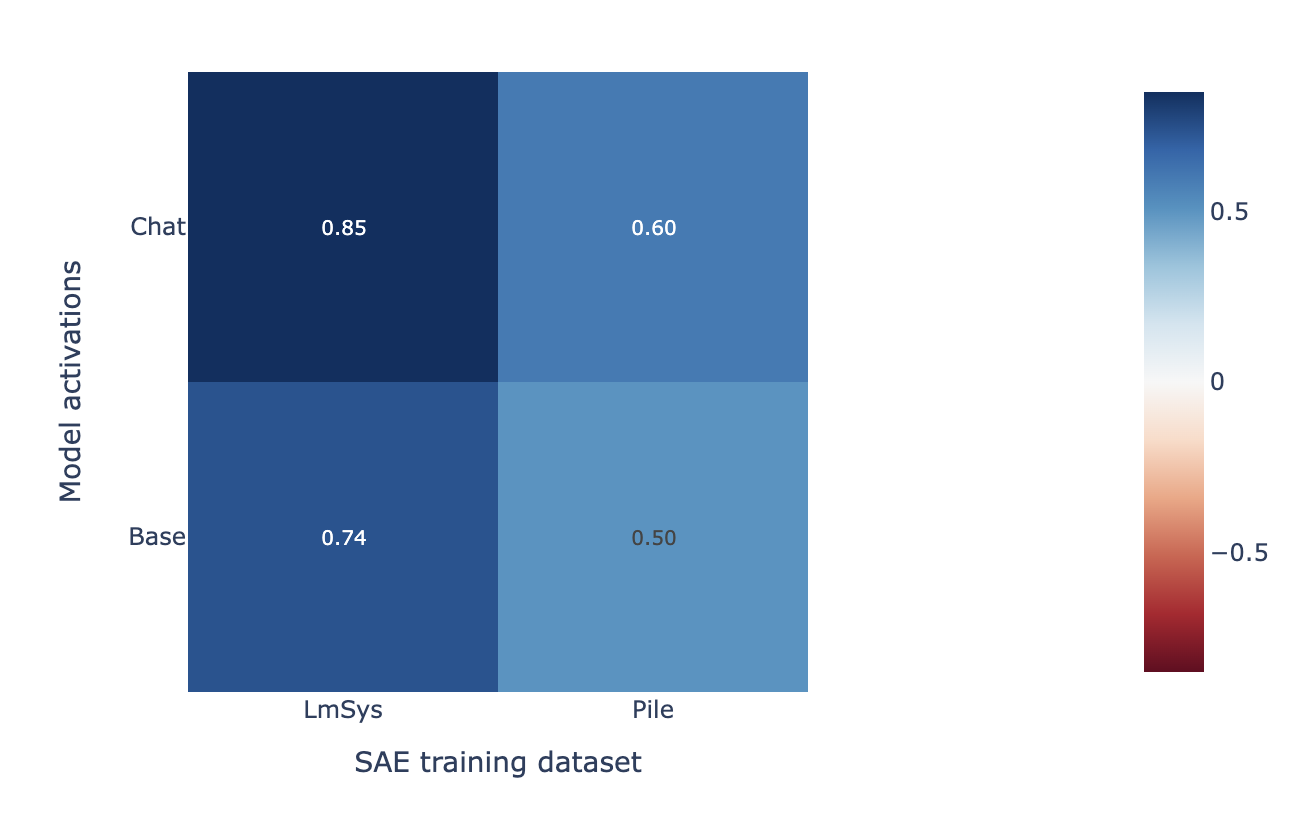
We find that the SAE trained on the (base model, LmSys dataset) outperforms the SAE trained on (chat model, pile dataset) in “refusal direction” reconstruction fidelity. This suggests that the training data is more important for reconstructing the refusal direction than the model checkpoint.
We similarly find that the (base model, LmSys dataset) SAE finds a more refusal aligned latent than any latent in the (chat model, pile dataset) SAE.
Overall, the results in this section further demonstrate the relative importance of the dataset for training useful SAEs.
This is a short research output, and we will fully review related work if this research work is turned into a paper.
There has been a fair amount of recent work that also studies the effect of the training dataset on SAE usefulness. McGrath claimed that training Llama-3-8b-Instruct SAEs on the LmSys-1m chat dataset found the most effective features for chat applications, while training on a non-chat dataset (or non-chat model) worked less well. Bricken et al. (2024a) claimed that oversampling synthetic bioweapons-related data into the SAE pre-training mix caused the SAE to learn more bioweapons-related features. Shortly after, Bricken et al. (2024b) used dictionary learning features to train bioweapons classifiers, and found that using SAEs trained with the oversampling technique improved classifier performance. Drori studied multiple different methods, including “direct” domain specific SAEs, to extract features relevant to domains like math and biology.
Our main takeaway is consistent with these works: domain specific SAEs basically just work. We focus on the specific safety-relevant area of refusals / harmful requests. We also have the benefit of the “refusal direction” (Arditi et al.) to give us a “ground truth” that we can use for custom evals.
Conmy and Nanda used SAEs to decompose steering vectors for “anger” and “weddings” in GPT-2 XL. They find mixed results: the SAEs outperform steering vectors in some domains, but fall short in others. neverix et al. also decomposed the “refusal direction” into SAE latents using inference time optimization (Smith), and interpreted refusal-related latents that they use for steering Phi-3 Mini. They however find linear combinations of latents are necessary to be competitive with the refusal direction, whereas we use a single latent.
Conclusion
In this post we showed that SAEs trained on chat-specific datasets find sparse, faithful, interpretable reconstructions of the refusal direction, where SAEs trained on the pile mostly fail. We also showed that the LmSys SAE finds an individual latent that is more similar to the “true refusal direction”, and is also more useful for steering the model to bypass refusals. Finally, we demonstrated that, for the task of reconstructing the “refusal direction”, the choice of training dataset is even more important than the choice of model activations (base vs chat) used to train the SAE. We recommend practitioners consider training domain specific SAEs when pre-trained SAEs fail on other safety relevant tasks.
Limitations
- This post focuses on Qwen 1.5 0.5B Chat. This is only one small chat model. The results may not generalize to different model families, or much larger models.
- All of our experiments use the standard SAE architecture from Anthropic’s April Update. However, it’s common for practitioners to use newer variants like TopK (Gao et al.) and JumpReLU SAEs (Rajamanoharan et al.). We’re not sure if our results will generalize for these different architectures.
- We only trained a single SAE on each dataset. A more rigorous analysis would involve sweeping over sparsity penalty and even random seed to better account for stochasticity in the SAE training process.
Future work
- We are very interested in if we can obtain similar benefits by fine-tuning pre-trained SAEs on domain specific data, ideally on less tokens. This seems especially promising since there already exist many high quality SAEs trained on pre-training data (Lieberum et al.).
- We’re curious to what extent the issues with the pile SAEs can be solved by making them wider. One concrete idea is to run the evals from this post on the open source Gemma 2 9B PT SAEs (Lieberum et al.), which have multiple widths up to 1M latents.
- LmSys consists of instructions and rollouts from various different models. It’s possible that we would get even better results if we trained an SAE with the same LmSys instructions, but with on-policy rollouts from the model itself. We didn’t prioritize this since the “refusal direction” is extracted using instructions only, but rollouts may be important for other features that we care about.
Citing this work
If you would like to reference any of our current findings, we would appreciate reference to:
@misc{SAEsAreHighlyDatasetDependent,
author= {Connor Kissane and Robert Krzyzanowski and Neel Nanda and Arthur Conmy},
url = {https://www.alignmentforum.org/posts/rtp6n7Z23uJpEH7od/saes-are-highly-dataset-dependent-a-case-study-on-the},
year = {2024},
howpublished = {Alignment Forum},
title = {SAEs are highly dataset dependent: A case study on the refusal direction},
}Author Contributions Statement
Connor and Rob were core contributors on this project. Connor trained the SAEs, designed the refusal direction reconstruction evals, ran all of the experiments, and wrote the post. Rob made the initial finding that the refusal direction is dense in the SAE basis for a Gemma-2-2b GemmaScope SAE (trained on pre-training data), and gave feedback on the post.
Arthur and Neel gave guidance and feedback throughout the project. Arthur suggested the sparse linear regression experiment (Figure 1). The idea to study the “refusal direction” in the SAE basis was originally suggested by Arthur, and the idea to train a chat-data specific SAE was suggested by Neel.
Acknowledgments
We’re grateful to Andy Arditi for helpful feedback and discussion.
- ^
We chose this layer because we found it to have an effective refusal direction for steering in prior work
Source link
#case #study #refusal #direction #Alignment #Forum
_Brain_light_Alamy.jpg?disable=upscale&width=1200&height=630&fit=crop&w=150&resize=150,150&ssl=1 "Breaches Don’t Have to Be Disasters")





/cdn.vox-cdn.com/uploads/chorus_asset/file/25746645/22832_2026_Sportage_Family_Lineup.jpg?w=150&resize=150,150&ssl=1 "Kia announces high-performance EV9 GT with virtual shifting and native Tesla charging")

