 Skip to content
Skip to content 
Some of the fascinating issues that a pc scientist could also be fortunate sufficient to come across is a fancy sociotechnical drawback in a subject going by the method of digital transformation. For me, that was fish counting. Lately, I labored as a marketing consultant in a subdomain of environmental science targeted on counting fish that move by massive hydroelectric dams. By way of this overarching mission, I discovered about methods to coordinate and handle human-in-the-loop dataset manufacturing, in addition to the complexities and vagaries of how to consider and share progress with stakeholders.
Background
Let’s set the stage. Giant hydroelectric dams are topic to Environmental Safety Act rules by the Federal Power Regulatory Fee (FERC). FERC is an unbiased company of the US authorities that regulates the transmission and wholesale sale of electrical energy throughout the US. The fee has jurisdiction over a variety of electrical energy actions and is liable for issuing licenses and permits for the development and operation of hydroelectric services, together with dams. These licenses and permits be sure that hydroelectric services are secure and dependable, and that they don’t have a damaging impression on the setting or different stakeholders. To be able to receive a license or allow from FERC, hydroelectric dam operators should submit detailed plans and research demonstrating that their facility meets rules. This course of usually includes intensive evaluate and session with different businesses and stakeholders. If a hydroelectric facility is discovered to be in violation of any set requirements, FERC is liable for implementing compliance with all relevant rules through sanctions, fines, or lease termination–resulting in a lack of the correct to generate energy.
Hydroelectric dams are primarily big batteries. They generate energy by build up a big reservoir of water on one aspect and directing that water by generators within the physique of the dam. Sometimes, a hydroelectric dam requires numerous area to retailer water on one aspect of it, which suggests they are usually situated away from inhabitants facilities. The conversion course of from potential to kinetic power generates massive quantities of electrical energy, and the quantity of stress and drive generated is disruptive to something that lives in or strikes by the waterways—particularly fish.
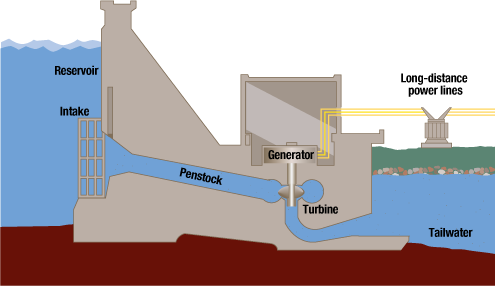
It is usually price noting that the waterways had been doubtless disrupted considerably when the dam was constructed, resulting in behavioral or population-level modifications within the fish species of the realm. That is of nice concern to the Pacific Northwest particularly, as hydropower is the predominant energy technology means for the area (Bonneville Energy Administration). Fish populations are consistently transferring upstream and downstream and hydropower dams can act as obstacles that block their passage, resulting in lowered spawning. In gentle of the dangers to fish, hydropower dams are topic to constraints on the quantity of energy they’ll generate and should present that they don’t seem to be killing fish in massive numbers or in any other case disrupting the rhythms of their lives, particularly as a result of the native salmonid species of the area are already threatened or endangered (Salmon Standing).
To display compliance with FERC rules, massive hydroelectric dams are required to routinely produce knowledge which reveals that their operational actions don’t intervene with endangered fish populations in mixture. Sometimes, that is carried out by performing fish passage research. A fish passage research will be carried out many various methods, however boils down to 1 main dataset upon which the whole lot is predicated: a fish depend. Fish are counted as they move by the hydroelectric dam, utilizing buildings like fish ladders to make their approach from the reservoir aspect to the stream aspect.

Fish counts will be carried out visually—-a individual skilled in fish identification watches the fish move, incrementing the depend as they transfer upstream. As a fish is counted, observers impart further classifications exterior of species of fish, resembling whether or not there was some form of apparent sickness or harm, if the fish is hatchery-origin or wild, and so forth. These variations between fish are delicate and require shut monitoring and verification, for the reason that attribute in query (a clipped adipose fin, a scratched midsection) might solely be seen briefly when the fish swims by. As such, fish counting is a specialised job that requires experience in figuring out and classifying completely different species of fish, in addition to data of their life phases and different traits. The job is bodily demanding, because it usually includes working in distant areas away from metropolis facilities, and it may be difficult to carry out precisely below the tough environmental circumstances discovered at hydroelectric dams–poor lighting, unregulated temperatures, and different circumstances inhospitable to people.
These modes of information assortment are nice, however there are various levels of error that may very well be imparted by their recording. For instance, some visible fish counts are documented with pen and paper, resulting in incorrect counts by transcription error; or there will be disputes in regards to the classification of a selected species. Totally different dam operators acquire fish counts with various levels of granularity (some acquire hourly, some every day, some month-to-month) and seasonality (some acquire solely throughout sure migration patterns known as “runs”). After assortment and validation, organizations correlate this knowledge with operational info produced by the dam in an try and see if any actions of the dam have an opposed or helpful impact on fish populations. Capturing these knowledge piecemeal with completely different governing requirements and ranges of element causes organizations to search for new efficiencies enabled by expertise.
Enter Pc Imaginative and prescient
Some organizations are exploring the usage of pc imaginative and prescient and machine studying to considerably automate fish counting. Since dam operators topic to FERC are required to gather fish passage knowledge anyway, and the information had been beforehand produced or encoded in ways in which had been difficult to work with, an attention-grabbing “human-in-the-loop” machine studying system arises. A human-in-the-loop system combines the judgment and experience of subject-matter knowledgeable people (fish biologists) with the consistency and reliability of machine studying algorithms, which might help to scale back sources of error and bias within the output dataset used within the machine studying system. For the particular drawback of fish counting, this might assist to make sure that the system’s selections are knowledgeable by the most recent scientific understanding of fish taxonomy and conservation targets, and will present a extra balanced and complete strategy to species or morphological classification. An algorithmic system may scale back the necessity for handbook knowledge assortment and evaluation by automating the method of figuring out and classifying species, and will present extra well timed and correct details about species’ well being.
Constructing a pc imaginative and prescient system for a highly-regulated trade, resembling hydropower utilities, is usually a difficult activity as a result of want for prime accuracy and strict compliance with regulatory requirements. The method of constructing such a system would usually contain a number of steps:
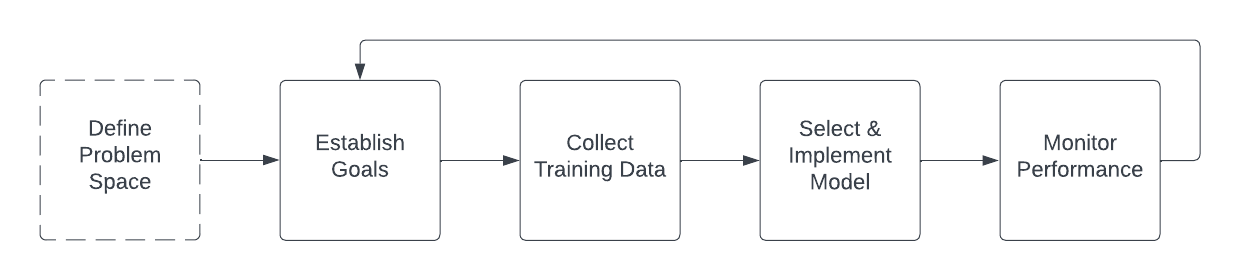
1. Outline the issue area: Earlier than beginning to construct the system, it is very important clearly outline the issue that the system is meant to unravel and the targets that it wants to realize. This preliminary negotiation course of is basically with none defining technical constraints, and is predicated across the job to that must be carried out by the system: figuring out particular duties that the system must carry out, resembling identification of the species or life stage of a fish. This can be particularly difficult in a regulated trade like hydropower, as shoppers are topic to strict legal guidelines and rules that require them to make sure that any instruments or applied sciences they use are dependable and secure. They might be skeptical of a brand new machine studying system and will require assurances that it has been completely examined and won’t pose any dangers to the setting or to by knowledge integrity, algorithmic transparency, and accountability.
As soon as the issue area is outlined, extra technical selections will be made about how you can implement the answer. For instance, if the objective is to estimate inhabitants density throughout excessive fish passage utilizing behavioral patterns resembling education, it might make sense to seize and tag reside video, to see the methods during which fish transfer in actual time. Alternatively, if the objective is to determine sickness or harm in a scenario the place there are few fish passing, it might make sense to seize nonetheless pictures and tag subsections of them to coach a classifier. In a extra developed hypothetical instance, maybe dam operators know that the fish ladder solely permits fish to move by it, all different species or pure particles are filtered out, they usually need a “finest guess” about uncommon species of fish that move upstream. It could be enough on this case to implement generic video-based object detection to determine {that a} fish is transferring by a scene, take an image of it at a sure level, and supply that image to a human to tag with the species. As soon as tagged, these knowledge can be utilized to coach a classifier which categorizes fish as being the uncommon species or not.
2. Set up efficiency targets: The definition of the issue area and the preliminary instructed course of circulation ought to be shared with all stakeholders as an enter to the efficiency targets. This helps guarantee all events perceive the issue at a excessive degree, and what’s potential for a given implementation. Virtually, most hydropower utilities are considering automated fish depend options that meet an accuracy threshold of 95% as in comparison with a daily human visible depend, however expectations round whether or not these metrics are achievable and at what a part of the manufacturing cycle will probably be a extremely negotiated sequence of factors. Establishing these targets is a real sociotechnical drawback, because it can’t be carried out with out bearing in mind each the real-world constraints that restrict the information and the system. These constraining elements will probably be mentioned later within the Obstacles part of the paper.
3. Acquire and label coaching knowledge: To be able to prepare a machine studying mannequin to carry out the duties required by the system, it’s first needed to provide a coaching dataset. Virtually, this includes gathering a lot of fish pictures. The pictures are annotated with the suitable species classification labels by an individual with experience in fish classification. The annotated pictures are then used to coach a machine studying mannequin. By way of coaching, the algorithm learns the options attribute of every subclass of fish and identifies these options to categorise fish in new, unseen pictures. As a result of the top objective of this method is to attenuate the counts that people must do, pictures with a low “confidence rating” (a metric generally produced by object-detection fashions) could also be flagged for identification and tagging by human reviewers. The extra seamless an integration with a manufacturing fish counting operation, the higher.
4. Choose a mannequin: As soon as the coaching knowledge has been collected, the following step is to pick an acceptable machine studying mannequin and prepare it on the information. This might contain utilizing a supervised studying strategy, the place the mannequin is skilled to acknowledge the completely different classes of fish after being proven examples of labeled knowledge. On the time of this writing, deep studying programs based mostly on pretrained fashions like ImageNet are standard selections. As soon as skilled, the mannequin ought to be validated in opposition to tagged knowledge that it has not seen earlier than and fine-tuned by adjusting the mannequin parameters or refining the coaching dataset and retraining.
5. Monitor system efficiency: As soon as the mannequin has been skilled and refined, it may be applied as a part of a pc imaginative and prescient system for normal use. The system’s efficiency ought to be monitored commonly to make sure that it’s assembly the required accuracy targets and to make sure that mannequin drift doesn’t happen, maybe from modifications in environmental circumstances, resembling water readability; or morphological modifications alluded to in a later part
It’s at this level that the loop of duties begins anew; to eke out extra efficiency from the system, it’s doubtless that extra refined and nuanced negotiation about what to anticipate from the system is critical, adopted by further coaching knowledge, mannequin choice, and parameter tuning/monitoring. The frequent assumption is that an automatic or semiautomatic system like that is “set it and neglect it” however the means of curating and collating datasets or tuning hyper parameters is sort of engaged and intentional.
Obstacles
To ensure that the pc imaginative and prescient algorithm to precisely detect and depend fish in pictures or video frames, it should be skilled on a big and various dataset that features examples of various fish species and morphologies. Nonetheless, this strategy just isn’t with out challenges, as specified within the diagram under and with bolded phrases in subsequent paragraphs:
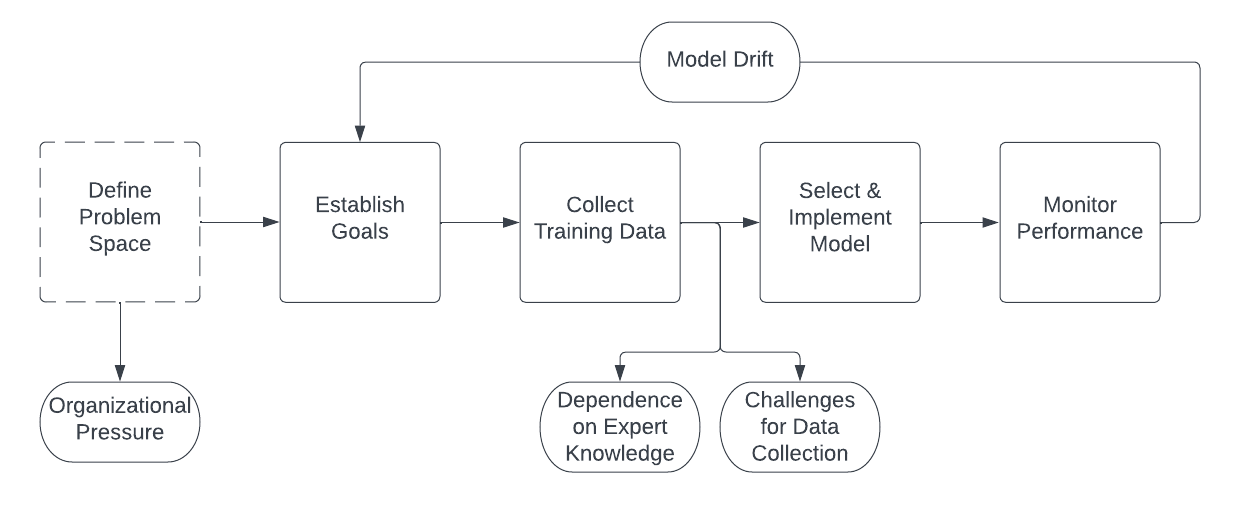
Dependence on knowledgeable data is a priority price discussing. If the system depends on expert-tagged knowledge to coach and consider its algorithms, the system could also be susceptible to errors and biases within the knowledgeable’s data and judgments, as any human-in-the-loop system could be. For instance, if the specialists should not acquainted with sure species or morphologies, they might not be capable of precisely tag these fish, which may result in incorrect classifications by the system. Ought to an invasive species enter the waterway, it might develop into overrepresented throughout the dataset and have an effect on the counts of the species that require conservation motion. A wonderful sensible instance of that is American shad, of which a whole lot of 1000’s can move throughout a migratory interval, obscuring the Chinook salmon which are additionally passing throughout the identical time. Guide counting strategies rely solely on the judgment and commentary of particular person people, which will be topic to quite a lot of sources of error and bias. Additional, if the specialists have a selected curiosity in sure species or morphologies, they might be extra more likely to tag these fish, which may lead to over- or under-representation throughout the dataset. This may result in life-threatening outcomes if the algorithmic system is used to make necessary selections which have conservation implications.
Environmental circumstances at hydroelectric dams current challenges for knowledge assortment as effectively. Insufficient illumination and poor picture high quality could make it tough for each people and machine studying algorithms to precisely classify fish. Equally, altering circumstances, like a discount in water readability following a seasonal snowmelt can obscure fish in imagery. Migratory fish will be tough to determine and classify on their very own phrases, as a result of wide selection of species and subspecies that exist, and the way in which their our bodies change as they age. These fish are sometimes tough to check and monitor because of their migratory habits and the difficult environments during which they reside. Additional, there are sometimes inconsistent knowledge taxonomies produced throughout organizations, resulting in completely different classifications relying on the father or mother group endeavor the information tagging course of. If people can not create correct classifications to populate the preliminary dataset, the machine studying system will be unable to precisely produce predictions when utilized in manufacturing.

One of many key challenges of utilizing a machine studying classifier on unaudited knowledge is the danger of mannequin drift, during which the mannequin’s efficiency degrades over time because the underlying knowledge distribution modifications. This can be of explicit concern in a extremely regulated setting, the place even small modifications within the mannequin’s efficiency may have vital penalties. The datasets produced by the hassle of tagging fish pictures are fascinating as a result of they’re so intrinsically place-based, located, and never simply replicable. Fish passage research typically contain monitoring a comparatively small variety of fish, which may make it tough to precisely assess the general profile of fish populations within the wider space. The quantity and sorts of fish that move by a dam’s fish ladders or different fish passage buildings can differ enormously relying on the time of 12 months or the “run” of fish passing by the waterways. This may make it tough to check knowledge from completely different research, or to attract conclusions in regards to the long-term impression of the dam on fish populations. If the system is skilled on a dataset of fish that has been tagged by subject-matter specialists throughout one season, the dataset might not be complete or consultant of the total vary of fish species and morphologies that exist within the wild throughout the total 12 months. This might result in under- or over-estimations of quantity and sorts of fish current in a given space. On this approach, the specter of mannequin drift is definitely an issue composed of each difficult knowledge manufacturing constraints and dependence on knowledgeable data.
Lastly, there are background labor points to be handled as a part of this drawback area coming from intense organizational stress. Fish counting is a price heart that hydroelectric dam operators wish to get rid of or scale back as a lot as potential. A technical resolution that may precisely depend fish is subsequently very interesting. Nonetheless, this raises issues about ghost work, the place human labor is used to coach and validate the mannequin, however just isn’t acknowledged or compensated. Changing human employees with a pc imaginative and prescient resolution might considerably impression the displaced employees by monetary hardship or the obsoletion of their job abilities and experience. If human experience within the identification of fish is misplaced, this might result in suboptimal selections about species conservation, and will in the end undermine the effectiveness of the system. This turns into extra harmful for conservation functions if the expertise is applied as a cost-reduction measure: it may very well be the case that—when the mannequin drifts—there aren’t any taggers to set it again on monitor.
Couple all of those factors with the longitudinal decline of untamed fish populations globally, and you’ve got a difficult set of circumstances to try to generalize from.
If the obtainable coaching knowledge is restricted or doesn’t precisely replicate the range of fish species and morphologies that move by the dam’s fish passage buildings, the accuracy of the algorithm could also be lowered. Moreover, there are issues about knowledge leakage, the place the mannequin could possibly infer delicate details about the fish from the photographs, resembling how they’re routed by the dam. Excited about research that occur in fisheries as per Hwang (2022), the populations analyzed are so small and the outcomes so deliberately so narrowly-scoped, it’s virtually the case that a company must on the very least prepare a one-off mannequin for every mission or validate the output of every ML classifier in opposition to some further supply, which is these days exterior of the curiosity and capabilities of organizations who hope to scale back labor outlays as a part of the implementation of a system like this.
Concluding Ideas
The sociotechnical drawback of fish counting is a distinct segment drawback with extensive purposes. If correctly applied, a machine studying system based mostly round fish counts has the potential to be utilized in many various locations, resembling assembly environmental regulation or aquaculture. The speedy digital transformation of environmental science has led to the event of novel datasets with attention-grabbing challenges, and a brand new cohort of pros with the information literacy and technical talents to work on issues like this. Nonetheless, constructing a dataset of anadromous and catadromous fish which are protected below the ESA is a fancy and difficult activity, as a result of restricted availability of information, the complexity of fish taxonomy, the involvement of a number of stakeholders, and the dynamic setting during which these species reside.
Furthermore, organizations topic to regulation could also be uncertain of how you can validate the accuracy of a machine studying mannequin, and could also be extra considering fish counts than in fish pictures (or vice-versa). Bringing new applied sciences to bear on a company or on a dataset that was not as robustly cataloged means there will probably be new issues to be found or measured by the appliance of the expertise. Since implementation of a pc imaginative and prescient system like that is carried out to fulfill compliance with FERC rules, it means bringing a number of completely different stakeholders–together with federal businesses, state and native governments, conservation organizations, and members of the general public–into dialogue with each other when modifications are required. By conducting these research and commonly reporting the outcomes to FERC, a hydroelectric dam operator may display that they’re taking steps to attenuate the impression of the dam on fish populations, and that the dam just isn’t having a damaging impression on the general well being of the native fish inhabitants, nevertheless it additionally means cross-checking with the neighborhood during which they’re located.
Creator Bio
Kevin McCraney is an information engineer, educator, and marketing consultant. He works with public sector & large-scale establishments constructing knowledge processing infrastructure & enhancing knowledge literacy. Kevin has a number of years of expertise educating & mentoring early profession professionals as they transition to expertise from non-STEM disciplines. Working predominantly with establishments within the Pacific Northwest, he enjoys skilled alternatives the place he can mix a humanistic worldview and technical acumen to unravel advanced sociotechnical issues.
Quotation
For attribution of this in educational contexts or books, please cite this work as:
Kevin McCraney, “Salmon within the Loop“, The Gradient, 2023.
BibTeX quotation
@article{k2023omccraney,
creator = {McCraney, Kevin},
title = {Salmon within the Loop},
journal = {The Gradient},
12 months = {2023},
howpublished = {url{https://thegradient.pub/salmon-in-the-loop}},
}
Works Cited
[1]Bonneville Energy Administration. (n.d.). Hydropower impression. Hydropower Affect. Retrieved January 14, 2023, from https://www.bpa.gov/energy-and-services/energy/hydropower-impact
[2]Delgado, Ok. (2021, July 19). That sounds fishy: Fish ladders at high-head dams impractical, largely unneeded. www.military.mil. Retrieved January 3, 2023, from https://www.military.mil/article/248558/that_sounds_fishy_fish_ladders_at_high_head_dams_impractical_largely_unneeded
[3]Hwang, I. (2022, Might 31). Salmon hatchery knowledge is tougher to deal with than you suppose. ProPublica. Retrieved December 10, 2023, from https://www.propublica.org/article/salmon-hatcheries-pnw-fish-data
[4]Salmon standing. State of Salmon. (2021, January 11). Retrieved December 29, 2022, from https://stateofsalmon.wa.gov/executive-summary/salmon-status/
[5]How hydroelectric energy works. Tennessee Valley Authority. (2021, January 11). Retrieved December 29, 2022, from https://www.tva.com/power/our-power-system/hydroelectric/how-hydroelectric-power-works
Source link
#Salmon #Loop
Unlock the potential of cutting-edge AI options with our complete choices. As a number one supplier within the AI panorama, we harness the ability of synthetic intelligence to revolutionize industries. From machine studying and knowledge analytics to pure language processing and pc imaginative and prescient, our AI options are designed to boost effectivity and drive innovation. Discover the limitless prospects of AI-driven insights and automation that propel your small business ahead. With a dedication to staying on the forefront of the quickly evolving AI market, we ship tailor-made options that meet your particular wants. Be part of us on the forefront of technological development, and let AI redefine the way in which you use and reach a aggressive panorama. Embrace the long run with AI excellence, the place prospects are limitless, and competitors is surpassed.






: Plastic, Glass, Stainless Steel, Travel")


