

















The historical past of every residing being is written in its genome, which is saved as DNA and current in practically each cell of the physique. No two cells are the identical, even when they share the identical DNA and cell kind, as they nonetheless differ within the regulators that management how DNA is expressed by the cell. The human genome consists of three billion base pairs unfold over 23 chromosomes. Inside this huge genetic code, there are roughly 20,000 to 25,000 genes, constituting the protein-coding DNA and accounting for about 1% of the whole genome [1]. To discover the functioning of advanced techniques in our our bodies, particularly this small coding portion of DNA, a exact sequencing methodology is important, and single-cell sequencing (sc-seq) know-how suits this objective.

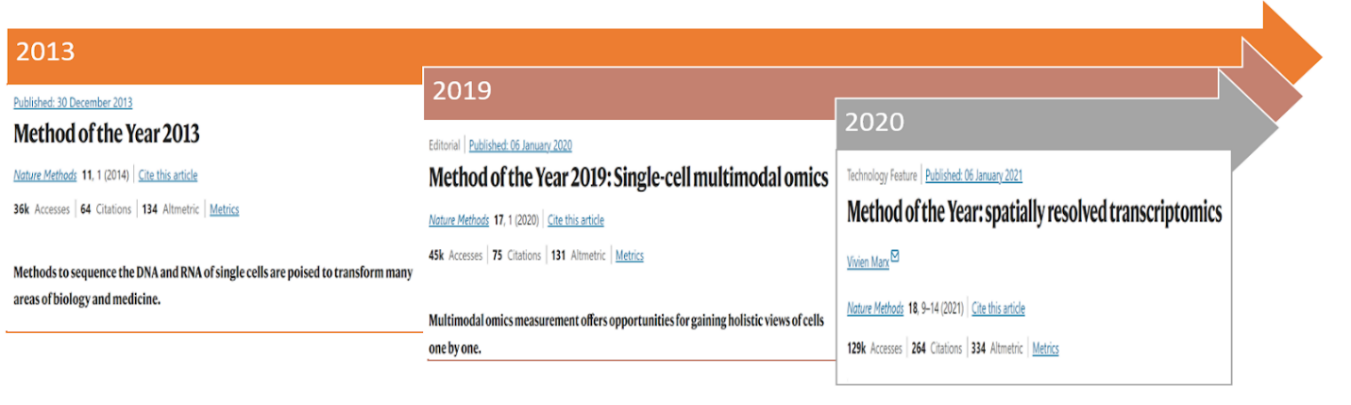
In 2013, Nature chosen single-cell RNA sequencing because the Technique of the Yr [2] (Determine 3), highlighting the significance of this methodology for exploring mobile heterogeneity by the sequencing of DNA and RNA on the particular person cell stage. Subsequently, quite a few instruments have emerged for the evaluation of single-cell RNA sequencing knowledge. For instance, the scRNA-tools database has been compiling software program for the evaluation of single-cell RNA knowledge since 2016, and by 2021, the database contains over 1000 instruments [3]. Amongst these instruments, many contain strategies that leverage Deep Studying strategies, which would be the focus of this text – we’ll discover the pivotal position that Deep Studying, specifically, has performed as a key enabler for advancing single-cell sequencing applied sciences.
Background
Circulation of genetic info from DNA to protein in cells
Let’s first go over what precisely cells and sequences are. The cell is the elemental unit of our our bodies and the important thing to understanding how our our bodies operate in good well being and the way molecular dysfunction results in illness. Our our bodies are manufactured from trillions of cells, and practically each cell accommodates three genetic info layers: DNA, RNA, and protein. DNA is an extended molecule containing the genetic code that makes every particular person distinctive. Like a supply code, it contains a number of directions exhibiting how you can make every protein in our our bodies. These proteins are the workhorses of the cell that perform practically each job crucial for mobile life. For instance, the enzymes that catalyze chemical reactions inside the cell and DNA polymerases that contribute to DNA replication throughout cell division, are all proteins. The cell synthesizes proteins in two steps: Transcription and Translation (Determine 1), that are often called gene expression. DNA is first transcribed into RNA, then RNA is translated into protein. We will contemplate RNA as a messenger between DNA and protein.
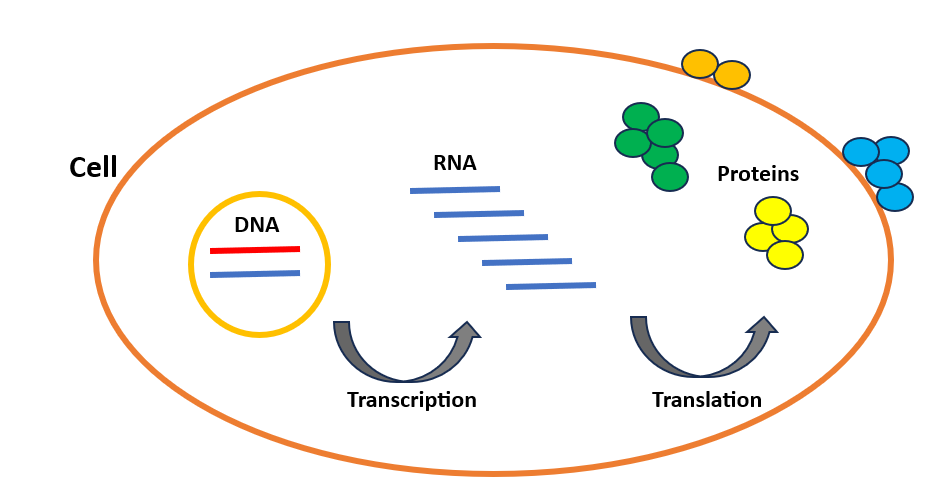
Whereas the cells of our physique share the identical DNA, they fluctuate of their organic exercise. For example, the distinctions between immune cells and coronary heart cells are decided by the genes which might be both activated or deactivated in these cells. Typically, when a gene is activated, it results in the creation of extra RNA copies, leading to elevated protein manufacturing. Subsequently, as cell varieties differ based mostly on the amount and kind of RNA/protein molecules synthesized, it turns into intriguing to evaluate the abundance of those molecules on the single-cell stage. This can allow us to analyze the habits of our DNA inside every cell and attain a high-resolution perspective of the varied components of our our bodies.
Usually, all single-cell sequencing applied sciences will be divided into three important steps:
- Isolation of single cells from the tissue of curiosity and extraction of genetic materials from every remoted cell
- Amplification of genetic materials from every remoted cell and library preparation
- Sequencing of the library utilizing a next-generation sequencer and knowledge evaluation
Navigating by the intricate steps of mobile biology and single-cell sequencing applied sciences, a pivotal query emerges: How is single-cell sequencing knowledge represented numerically?
Construction of single-cell sequencing knowledge
The construction of single-cell sequencing knowledge takes the type of a matrix (Determine 2), the place every row corresponds to a cell that has been sequenced and annotated with a novel barcode. The variety of rows equals the whole variety of cells analyzed within the experiment. However, every column corresponds to a particular gene. Genes are the practical items of the genome that encode directions for the synthesis of proteins or different practical molecules. Within the case of scRNA seq knowledge, the numerical entries within the matrix signify the expression ranges of genes in particular person cells. These values point out the quantity of RNA produced from every gene in a specific cell, offering insights into the exercise of genes inside completely different cells.

Single Cell Sequencing Overview
For greater than 150 years, biologists have needed to determine all of the cell varieties within the human physique and classify them into distinct varieties based mostly on correct descriptions of their properties. The Human Cell Atlas Venture (HCAP), the genetic equal of the Human Genome Venture [4], is a global collaborative effort to map all of the cells within the human physique.” We will conceptualize the Human Cell Atlas as a map endeavoring to painting the human physique coherently and systematically. Very similar to Google Maps, which permits us to zoom in for a better examination of intricate particulars, the Human Cell Atlas supplies insights into spatial info, inner attributes, and even the relationships amongst components”, explains Aviv Regev, a computational and techniques biologist on the Broad Institute of MIT and Harvard and Govt Vice President and Head of Genentech Analysis.
This analogy seamlessly aligns with the broader impression of single-cell sequencing, because it permits the evaluation of particular person cells as an alternative of bulk populations. This know-how proves invaluable in addressing intricate organic inquiries associated to developmental processes and comprehending heterogeneous mobile or genetic modifications underneath numerous therapy circumstances or illness states. Moreover, it facilitates the identification of novel cell varieties inside a given mobile inhabitants. The initiation of the primary single-cell RNA sequencing (scRNA-seq) paper in 2009 [5], subsequently designated because the “methodology of the yr” in 2013 [2], marked the genesis of an intensive endeavor to advance each experimental and computational strategies devoted to unraveling the intricacies of single-cell transcriptomes.
Because the technological panorama evolves, the narrative transitions to the developments in single-cell analysis, notably the early concentrate on single-cell RNA sequencing (scRNA-seq) as a consequence of its cost-effectiveness in finding out advanced cell populations.” In some methods, RNA has all the time been one of many best issues to measure,” says Satija [6], a researcher on the New York Genome Heart (NYGC). But, the speedy growth of single-cell know-how has ushered in a brand new period of potentialities—multimodal single-cell knowledge integration. Acknowledged because the “Technique of the Yr 2019” by Nature [7] (Determine 3), this method permits the measurement of various mobile modalities, together with the genome, epigenome, and proteome, inside the similar cell. The layering of a number of items of data supplies highly effective insights into mobile id, posing the problem of successfully modeling and mixing datasets generated from multimodal measurements. This integration problem is met with the introduction of Multi-view studying [8] strategies, exploring frequent variations throughout modalities. This refined method, incorporating deep studying strategies, showcases related outcomes throughout numerous fields, notably in biology and biomedicine.
Amidst these developments, a definite problem surfaces within the persistent limitation of single-cell RNA sequencing—the lack of spatial info throughout transcriptome profiling by isolating cells from their unique place. Spatially resolved transcriptomics (SRT) emerges as a pivotal answer [9], addressing the problem by preserving spatial particulars in the course of the examine of advanced organic techniques. This recognition of spatially resolved transcriptomics as the tactic of the yr 2020 solidifies its place as a essential answer to the challenges inherent in advancing our understanding of advanced organic techniques.
Having explored the panorama of single-cell sequencing, allow us to now delve into the position of deep studying within the context of single-cell sequencing.
Deep Studying on single-cell sequencing
Deep studying is more and more employed in single-cell evaluation as a consequence of its capability to deal with the complexity of single-cell sequencing knowledge. In distinction, standard machine-learning approaches require vital effort to develop a function engineering technique, usually designed by area specialists. The deep studying method, nonetheless, autonomously captures related traits from single-cell sequencing knowledge, addressing the heterogeneity between single-cell sequencing experiments, in addition to the related noise and sparsity in such knowledge. Beneath are three key causes for the applying of deep studying in single-cell sequencing:
- Excessive-Dimensional Information: Single-cell sequencing generates high-dimensional knowledge, with 1000’s of genes and their expression ranges measured for every cell. Deep studying fashions are adept at capturing advanced relationships and patterns inside this knowledge, which will be difficult for conventional statistical strategies.
- Non-Linearity: Single-cell gene expression knowledge is characterised by its inherent nonlinearity between gene expressions and cell-to-cell heterogeneity. Conventional statistical strategies encounter difficulties in capturing the non-linear relationships current in single-cell gene expression knowledge. In distinction, deep studying fashions are versatile and capable of study advanced non-linear mappings.
- Heterogeneity: Single-cell knowledge is usually characterised by numerous cell populations with various gene expression profiles, presenting a posh panorama. Deep studying fashions can play an important position in figuring out, clustering, and characterizing these distinct cell varieties or subpopulations, thereby facilitating a deeper understanding of mobile heterogeneity inside a pattern.
As we discover the explanations behind utilizing deep studying in single-cell sequencing knowledge, it leads us to the query: What deep studying architectures are sometimes utilized in sc-seq knowledge evaluation?
Background on Autoencoders
Autoencoders (AEs) stand out amongst numerous deep-learning architectures (akin to GANs and RNNs) as an particularly relied upon methodology for decoding the complexities of single-cell sequencing knowledge. Broadly employed for dimensionality discount whereas preserving the inherent heterogeneity within the single-cell sequencing knowledge. By clustering cells within the reduced-dimensional house generated by autoencoders, researchers can successfully determine and characterize completely different cell varieties or subpopulations. This method enhances our means to discern and analyze the varied mobile elements inside single-cell datasets. In distinction to non-deep studying fashions, akin to principal part evaluation (PCA), that are integral elements of established scRNA-seq knowledge evaluation software program like Seurat [10], autoencoders distinguish themselves by uncovering non-linear manifolds. Whereas PCA is constrained to linear transformations, the pliability of autoencoders to seize advanced non-linear mappings makes it a complicated methodology to seek out nuanced relationships embedded in single-cell genomics.
To mitigate the overfitting problem related to autoencoders, a number of enhancements to the autoencoder construction have been carried out, particularly tailor-made to supply benefits within the context of sc-seq knowledge. One notable adaptation usually used within the context of sc-seq knowledge is the denoising autoencoder (DAEs), which amplifies the autoencoder’s reconstruction functionality by introducing noise to the preliminary community layer. This entails randomly remodeling a few of its items to zero. The Denoising Autoencoder then reconstructs the enter from this deliberately corrupted model, empowering the community to seize extra related options and stopping it from merely memorizing the enter (overfitting). This refinement considerably bolsters the mannequin’s resilience towards knowledge noise, thereby elevating the standard of the low-dimensional illustration of samples (i.e., bottleneck) derived from the sc-seq knowledge.
A 3rd variation of autoencoders incessantly employed in sc-seq knowledge evaluation is variational autoencoders (VAEs), exemplified by fashions like scGen [19], scVI [14], scANVI [28], and so forth. VAEs, as a sort of generative mannequin, study a latent illustration distribution of the info. As a substitute of encoding the info right into a vector of p-dimensional latent variables, the info is encoded into two vectors of measurement p: a vector of means η and a vector of ordinary deviations σ. VAEs introduce a probabilistic ingredient to the encoding course of, facilitating the technology of artificial single-cell knowledge and providing insights into the variety inside a cell inhabitants. This nuanced method provides one other layer of complexity and richness to the exploration of single-cell genomics.
Purposes of deep studying in sc-seq knowledge evaluation
This part outlines the primary functions of deep studying in enhancing numerous phases of sc-seq knowledge evaluation, highlighting its effectiveness in advancing essential facets of the method.
scRNA-seq knowledge imputation and denoising
Single-cell RNA sequencing (scRNA-seq) knowledge encounter inherent challenges, with dropout occasions being a distinguished concern that results in vital points—leading to sparsity inside the gene expression matrix, usually characterised by a considerable variety of zero values. This sparsity considerably shapes downstream bioinformatics analyses. Many of those zero values come up artificially as a consequence of deficiencies in sequencing strategies, together with issues like insufficient gene expression, low seize charges, sequencing depth, or different technical components. As a consequence, the noticed zero values don’t precisely mirror the true underlying expression ranges. Therefore, not all zeros in scRNA-seq knowledge will be thought of mere lacking values, deviating from the standard statistical method of imputing lacking knowledge values. Given the intricate distinction between true and false zero counts, conventional imputation strategies with predefined lacking values could show insufficient for scRNA-seq knowledge. For example, a classical imputation methodology, like Imply Imputation, would possibly entail substituting these zero values with the common expression stage of that gene throughout all cells. Nonetheless, this method runs the danger of oversimplifying the complexities launched by dropout occasions in scRNA-seq knowledge, probably resulting in biased interpretations.
ScRNA-seq knowledge imputation strategies will be divided into two classes: deep studying–based mostly imputation methodology and non–deep studying imputation methodology. The non–deep studying imputation algorithms contain becoming statistical chance fashions or using the expression matrix for smoothing and diffusion. This simplicity renders it efficient for sure varieties of samples. For instance, Wagner et al. [11] utilized the k-nearest neighbors (KNN) methodology, figuring out nearest neighbors between cells and aggregating gene-specific Distinctive Molecular Identifiers (UMI) counts to impute the gene expression matrix. In distinction, Huang et al. [12] proposed the SVAER algorithm, leveraging gene-to-gene relationships for imputing the gene expression matrix. For bigger datasets (comprising tens of 1000’s or extra), high-dimensional, sparse, and sophisticated scRNA-seq knowledge, conventional computational strategies face difficulties, usually rendering evaluation utilizing these strategies tough and infeasible. Consequently, many researchers have turned to designing strategies based mostly on deep studying to handle these challenges.
Most deep studying algorithms for imputing dropout occasions are based mostly on autoencoders (AEs). For example, in 2018, Eraslan et al. [13] launched the deep depend autoencoder (DCA). DCA makes use of a deep autoencoder structure to handle dropout occasions in single-cell RNA sequencing (scRNA-seq) knowledge. It incorporates a probabilistic layer within the decoder to mannequin the dropout course of. This probabilistic layer accommodates the uncertainty related to dropout occasions, enabling the mannequin to generate a distribution of potential imputed values. To seize the traits of depend knowledge in scRNA-seq, DCA fashions the noticed counts as originating from a destructive binomial distribution.
Single-cell variational inference (scVI) is one other deep studying algorithm launched by Lopez et al. [14]. ScVI is a probabilistic variational autoencoder (VAE) that mixes deep studying and probabilistic modeling to seize the underlying construction of the scRNA-seq knowledge. ScVI can be utilized for imputation, denoising, and numerous different duties associated to the evaluation of scRNA-seq knowledge. In distinction to the DCA mannequin, scVI employs Zero-Inflated Unfavourable Binomial (ZINB) distribution within the decoder half to generate a distribution of potential counts for every gene in every cell. The Zero-Inflated Unfavourable Binomial (ZINB) distribution permits modeling the chance of a gene expression being zero (to mannequin dropout occasions) in addition to the distribution of constructive values (to mannequin non-zero counts).
Moreover, one other examine addressed the scRNA-seq knowledge imputation problem by introducing a recurrent community layer of their mannequin, often called scScope [15]. This novel structure iteratively performs imputations on zero-valued entries of enter scRNA-seq knowledge. The pliability of scScope’s design permits for the iterative enchancment of imputed outputs by a selected variety of recurrent steps (T). Noteworthy is the truth that decreasing the time recurrence of scScope to at least one (i.e., T = 1) transforms the mannequin into a conventional autoencoder (AE). As scScope is actually a modification of conventional AEs, its runtime is corresponding to different AE-based fashions.
It is vital to notice that the applying of deep studying in scRNA-seq knowledge imputation and denoising is especially advantageous as a consequence of its means to seize non-linear relationships amongst genes. This contrasts with normal linear approaches, making deep studying more proficient at offering knowledgeable and correct imputation methods within the context of single-cell genomics.
Batch impact elimination
Single-cell knowledge is usually aggregated from numerous experiments that fluctuate when it comes to experimental laboratories, protocols, pattern compositions, and even know-how platforms. These variations end in vital variations or batch results inside the knowledge, posing a problem within the evaluation of organic variations of curiosity in the course of the course of of knowledge integration. To handle this challenge, it turns into essential to right batch results by eradicating technical variance when integrating cells from completely different batches or research. The primary methodology that seems for batch correction is a linear methodology based mostly on linear regression akin to Limma package deal [16] that gives the removeBatchEffect operate which inserts a linear mannequin that considers the batches and their impression on gene expression. After becoming the mannequin, it units the coefficients related to every batch to zero, successfully eradicating their impression. One other methodology referred to as ComBat [17] does one thing related however provides an additional step to refine the method, making the correction much more correct through the use of a method referred to as empirical Bayes shrinkage.
Nonetheless, batch results will be extremely nonlinear, making it tough to appropriately align completely different datasets whereas preserving key organic variations. In 2018, Haghverdi et al. launched the Mutual Nearest Neighbors (MNN) algorithm to determine pairs of cells from completely different batches in single-cell knowledge [18]. These recognized mutual nearest neighbors help in estimating batch results between batches. By making use of this correction, the gene expression values are adjusted to account for the estimated batch results, aligning them extra intently and decreasing discrepancies launched by the completely different batches. For intensive single-cell datasets with extremely nonlinear batch results, conventional strategies could show much less efficient, prompting researchers to discover the applying of neural networks for improved batch correction.
One of many pioneering fashions that make use of deep studying for batch correction is the scGen mannequin. Developed by Lotfollahi et al., ScGen [19] makes use of a variational autoencoder (VAE) structure. This entails pre-training a VAE mannequin on a reference dataset to regulate actual single-cell knowledge and alleviate batch results. Initially, the VAE is educated to seize latent options inside the reference dataset’s cells. Subsequently, this educated VAE is utilized to the precise knowledge, producing latent representations for every cell. The adjustment of gene expression profiles is then based mostly on aligning these latent representations, to cut back batch results and harmonize profiles throughout completely different experimental circumstances.
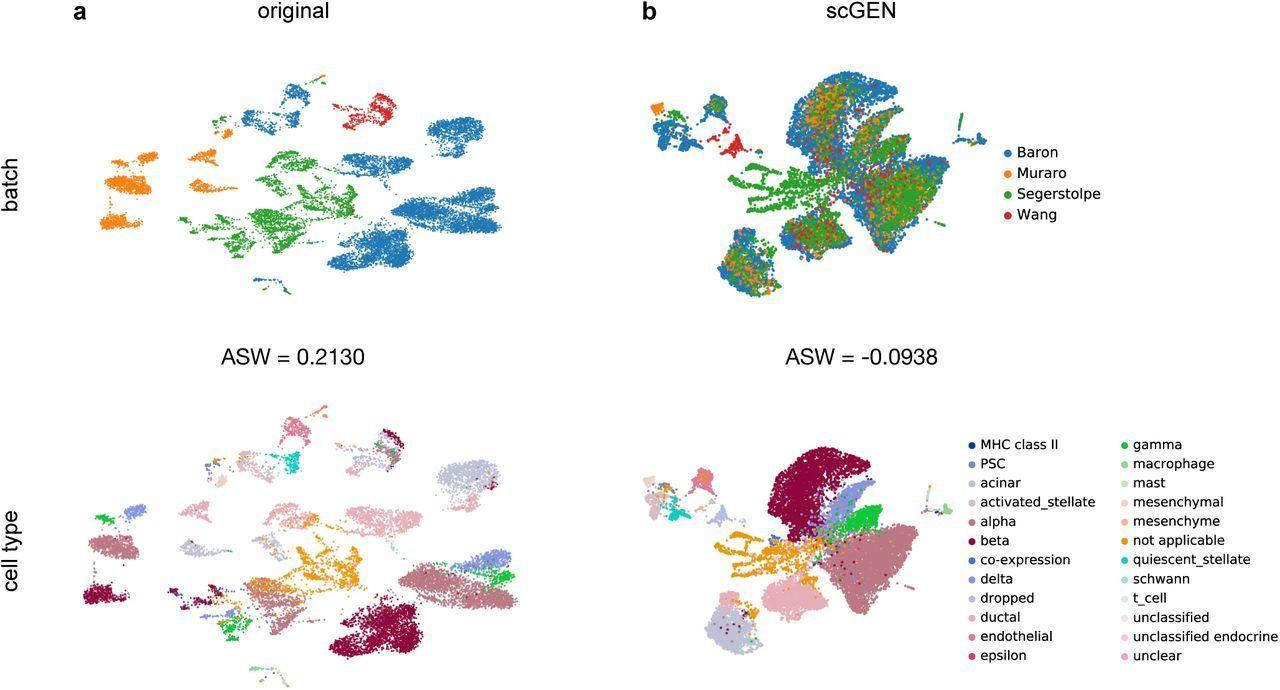
However, Zou et al. launched DeepMNN [20], which employs a residual neural community and the mutual nearest neighbor (MNN) algorithm for scRNA-seq knowledge batch correction. Initially, MNN pairs are recognized throughout batches in a principal part evaluation (PCA) subspace. Subsequently, a batch correction community is constructed utilizing two stacked residual blocks to take away batch results. The loss operate of DeepMNN contains a batch loss, computed based mostly on the space between cells in MNN pairs within the PCA subspace, and a weighted regularization loss, guaranteeing the community’s output similarity to the enter.
Nearly all of current scRNA-seq strategies are designed to take away batch results first after which cluster cells, which probably overlooks sure uncommon cell varieties. Not too long ago, Xiaokang et al. developed scDML [21], a deep metric studying mannequin to take away batch impact in scRNA-seq knowledge, guided by the preliminary clusters and the closest neighbor info intra and inter-batches. First, the graph-based clustering algorithm is used to group cells based mostly on gene expression similarities, then the KNN algorithm is utilized to determine k-nearest neighbors for every cell within the dataset, and the MNN algorithm to determine mutual nearest neighbors, specializing in reciprocal relationships between cells. To take away batch results, deep triplet studying is employed, contemplating laborious triplets. This helps in studying a low-dimensional embedding that accounts for the unique high-dimensional gene expression and removes batch results concurrently.
Cell kind annotation
Cell kind annotation in single-cell sequencing entails the method of figuring out and labeling particular person cells based mostly on their gene expression profiles, which permits researchers to seize the variety inside a heterogeneous inhabitants of cells, and perceive the mobile composition of tissues, and the practical roles of various cell varieties in organic processes or illnesses. Historically, researchers have used guide strategies [22] to annotate cell sub-populations. This entails figuring out gene markers or gene signatures which might be differentially expressed in a particular cell cluster. As soon as gene markers are recognized, researchers manually interpret the organic relevance of those markers to assign cell-type labels to the clusters. This conventional guide annotation method is time-consuming and requires appreciable human effort, particularly when coping with large-scale single-cell datasets. As a result of challenges related to guide annotation, researchers are turning to automate and streamline the cell annotation course of.
Two main methods are employed for cell kind annotation: unsupervised-based and supervised-based. Within the unsupervised realm, clustering strategies akin to Scanpy [23] and Seurat [10] are utilized, demanding prior information of established mobile markers. The identification of clusters hinges on the unsupervised grouping of cells with out exterior reference info. Nonetheless, a downside to this method is a possible lower in replicability with an elevated variety of clusters and a number of alternatives of cluster marker genes.
Conversely, supervised-based methods depend on deep-learning fashions educated on labeled knowledge. These fashions discern intricate patterns and relationships inside gene expression knowledge throughout coaching, enabling them to foretell cell varieties for unlabeled knowledge based mostly on acquired patterns. For instance, Joint Integration and Discrimination (JIND) [24] deploys a GAN-style deep structure, the place an encoder is pre-trained on classification duties, circumventing the necessity for an autoencoder framework. This mannequin additionally accounts for batch results. AutoClass [25] integrates an autoencoder and a classifier, combining output reconstruction loss with a classification loss for cell annotation alongside knowledge imputation. Moreover, TransCluster, [26] rooted within the Transformer framework and convolutional neural community (CNN), employs function extraction from the gene expression matrix for single-cell annotation.
Regardless of the ability of deep neural networks, acquiring a lot of precisely and unbiasedly annotated cells for coaching is difficult, given the labor-intensive guide inspection of marker genes in scRNAseq knowledge. In response, semi-supervised studying has been leveraged in computational cell annotation. For example, the SemiRNet [27] mannequin makes use of each unlabeled and a restricted quantity of labeled scRNAseq cells to implement cell identification. SemiRNet, based mostly on recurrent convolutional neural networks (RCNN), incorporates a shared community, a supervised community, and an unsupervised community. Moreover, single‐cell ANnotation utilizing Variational Inference (scANVI) [28], a semi‐supervised variant of scVI [14], maximizes the utility of current cell state annotations. Cell BLAST, an autoencoder-based generative mannequin, harnesses large-scale reference databases to study nonlinear low-dimensional representations of cells, using a classy cell similarity metric—normalized projection distance—to map question cells to particular cell varieties and determine novel cell varieties.
Multi-omics Information Integration
Current research have demonstrated the potential of deep studying fashions in addressing advanced and multimodal organic challenges [29]. Among the many algorithms proposed to this point, it’s primarily deep learning-based fashions that present the important computational adaptability crucial for successfully modeling and incorporating practically any type of omic knowledge together with genomics (finding out DNA sequences and genetic variations), epigenomics (inspecting modifications in gene exercise unrelated to DNA sequence, akin to DNA modifications and chromatin construction), transcriptomics (investigating RNA molecules and gene expression by RNA sequencing), and proteomics (analyzing all proteins produced by an organism, together with constructions, abundances, and modifications). Deep Studying architectures, together with autoencoders (AE) and generative adversarial networks (GAN), have been usually utilized in multi-omics integration issues in single cells. The important thing query in multi-omics integration revolves round how you can successfully signify the varied multi-omics knowledge inside a unified latent house.
One of many early strategies developed utilizing Variational Autoencoders (VAE) for the combination of multi-omics single-cell knowledge is named totalVI [30]. The totalVI mannequin, which is VAE-based, affords an answer for successfully merging scRNA-seq and protein knowledge. On this mannequin, totalVI takes enter matrices containing scRNA-seq and protein depend knowledge. Particularly, it treats gene expression knowledge as sampled from a destructive binomial distribution, whereas protein knowledge are handled as sampled from a combination mannequin consisting of two destructive binomial distributions. The mannequin first learns shared latent house representations by its encoder, that are then utilized to reconstruct the unique knowledge, taking into consideration the variations between the 2 unique knowledge modalities. Lastly, the decoder part estimates the parameters of the underlying distributions for each knowledge modalities utilizing the shared latent illustration.
However, Zuo et al. [31] launched scMVAE as a multimodal variational autoencoder designed to combine transcriptomic and chromatin accessibility knowledge in the identical particular person cells. scMVAE employs two separate single-modal encoders and two single-modal decoders to successfully mannequin each transcriptomic and chromatin knowledge. It achieves this by combining three distinct joint-learning methods with a probabilistic Gaussian Combination Mannequin.
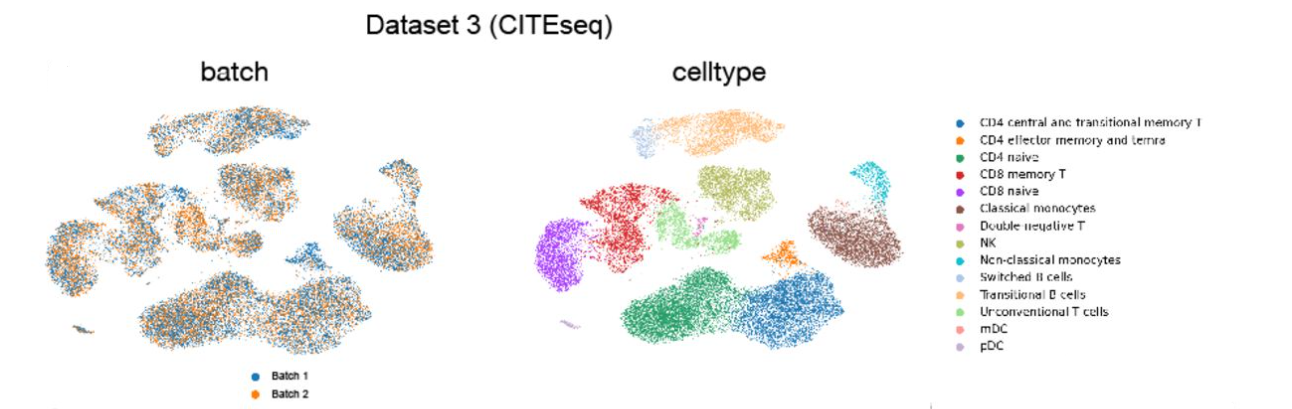
Not too long ago, Lotfollahi et al. [32] launched an unsupervised deep generative mannequin often called MULTIGRATE for the combination of multi-omic datasets. MULTIGRATE employs a multi-modal variational autoencoder construction that shares some similarities with the scMVAE mannequin. Nonetheless, it affords added generality and the aptitude to combine each paired and unpaired single-cell knowledge. To reinforce cell alignment, the loss operate incorporates Most Imply Discrepancy (MMD), penalizing any misalignment between the purpose clouds related to completely different assays. Incorporating switch studying, MULTIGRATE can map new multi-omic question datasets right into a reference atlas and in addition carry out imputations for lacking modalities.
Conclusion
The applying of deep studying in single-cell sequencing features as a complicated microscope, revealing intricate insights inside particular person cells and offering a profound understanding of mobile heterogeneity and complexity in organic techniques. This cutting-edge know-how empowers scientists to discover beforehand undiscovered facets of mobile habits. Nonetheless, the problem lies in selecting between conventional instruments and the plethora of obtainable deep-learning choices. The panorama of instruments is huge, and researchers should rigorously contemplate components akin to knowledge kind, complexity, and the particular organic questions at hand. Navigating this decision-making course of requires a considerate analysis of the strengths and limitations of every device in relation to analysis targets.
However, a essential want within the growth of deep studying approaches for single-cell RNA sequencing (scRNA-seq) evaluation is powerful benchmarking. Whereas many research evaluate deep studying efficiency to straightforward strategies, there’s a lack of complete comparisons throughout numerous deep studying fashions. Furthermore, strategies usually declare superiority based mostly on particular datasets and tissues (e.g., pancreas cells, immune cells), making it difficult to guage the need of particular phrases or preprocessing steps. Addressing these challenges requires an understanding of when deep studying fashions fail and their limitations. Recognizing which varieties of deep studying approaches and mannequin constructions are helpful in particular instances is essential for growing new approaches and guiding the sphere.
Within the realm of multi-omics single-cell integration, most deep studying strategies goal to discover a shared latent illustration for all modalities. Nonetheless, shared illustration studying faces challenges akin to heightened noise, sparsity, and the intricate job of balancing modalities. Inherent biases throughout establishments complicate generalization. Regardless of being much less prevalent than single-modality approaches, integrating numerous modalities with distinctive cell populations is essential. Aims embody predicting expression throughout modalities and figuring out cells in related states. Regardless of developments, additional efforts are important for enhanced efficiency, notably regarding distinctive or uncommon cell populations current in a single know-how however not the opposite.
Writer Bio
Fatima Zahra El Hajji holds a grasp’s diploma in bioinformatics from the Nationwide Faculty of Laptop Science and Methods Evaluation (ENSIAS), she subsequently labored as an AI intern at Piercing Star Applied sciences. Presently, she is a Ph.D. scholar on the College Mohammed VI Polytechnic (UM6P), working underneath the supervision of Dr. Rachid El Fatimy and Dr. Tariq Daouda. Her analysis focuses on the applying of deep studying strategies in single-cell sequencing knowledge.
Quotation
For attribution in tutorial contexts or books, please cite this work as
Fatima Zahra El Hajji, "Deep studying for single-cell sequencing: a microscope to see the variety of cells", The Gradient, 2024.
BibTeX quotation:
@article{elhajji2023nar,
writer = {El Hajji, Fatima Zahra},
title = {Deep studying for single-cell sequencing: a microscope to see the variety of cells},
journal = {The Gradient},
yr = {2024},
howpublished = {url{https://thegradient.pub/deep-learning-for-single-cell-sequencing-a-microscope-to-uncover-the-rich-diversity-of-individual-cells},
}References
- Nationwide Human Genome Analysis Institute (NHGRI) : A Transient Information to Genomics , https://www.genome.gov/about-genomics/fact-sheets/A-Brief-Guide-to-Genomics
- Technique of the Yr 2013. Nat Strategies 11, 1 (2014). https://doi.org/10.1038/nmeth.2801
- Zappia, L., Theis, F.J. Over 1000 instruments reveal traits within the single-cell RNA-seq evaluation panorama. Genome Biol 22, 301 (2021). https://doi.org/10.1186/s13059-021-02519-4
- Collins FS, Fink L. The Human Genome Venture. Alcohol Well being Res World. 1995;19(3):190-195. PMID: 31798046; PMCID: PMC6875757.
- Tang F, Barbacioru C, Wang Y, et al. mRNA-Seq whole-transcriptome evaluation of a single cell. Nat Strategies. 2009; 6: 377-382.
- Eisenstein, M. The key lifetime of cells. Nat Strategies 17, 7–10 (2020). https://doi.org/10.1038/s41592-019-0698-y
- Technique of the Yr 2019: Single-cell multimodal omics. Nat Strategies 17, 1 (2020). https://doi.org/10.1038/s41592-019-0703-5
- Zhao, Jing et al. “Multi-view studying overview: Current progress and new challenges.” Inf. Fusion 38 (2017): 43-54.
- Zhu, J., Shang, L. & Zhou, X. SRTsim: spatial sample preserving simulations for spatially resolved transcriptomics. Genome Biol 24, 39 (2023).
- Butler, A., Hoffman, P., Smibert, P., Papalexi, E., & Satija, R. (2018). Integrating single-cell transcriptomic knowledge throughout completely different circumstances, applied sciences, and species. Nature biotechnology, 36(5), 411-420
- Wagner, F., Yan, Y., & Yanai, I. (2018). Ok-nearest neighbor smoothing for high-throughput single-cell RNA-Seq knowledge. bioRxiv, 217737. Chilly Spring Harbor Laboratory. https://doi.org/10.1101/217737
- Huang, M., Wang, J., Torre, E. et al. SAVER: gene expression restoration for single-cell RNA sequencing. Nat Strategies 15, 539–542 (2018). https://doi.org/10.1038/s41592-018-0033-z
- Eraslan G, Simon LM, Mircea M, Mueller NS, Theis FJ. Single-cell RNA-seq denoising utilizing a deep depend autoencoder. Nat Commun. 2019 Jan 23;10(1):390. doi: 10.1038/s41467-018-07931-2. PMID: 30674886; PMCID: PMC6344535.
- Lopez, R., Regier, J., Cole, M. B., Jordan, M. I.,& Yosef, N. (2018). Deep generative modeling for single-cell transcriptomics. Nature strategies, 15(12), 1053-1058.
- Y. Deng, F. Bao, Q. Dai, L.F. Wu, S.J. Altschuler Scalable evaluation of cell-type composition from single-cell transcriptomics utilizing deep recurrent studying
- Ritchie ME, Phipson B, Wu D, Hu Y, Regulation CW, Shi W, Smyth GK. limma powers differential expression analyses for RNA-sequencing and microarray research. Nucleic Acids Res. 2015 Apr 20;43(7):e47. doi: 10.1093/nar/gkv007. Epub 2015 Jan 20. PMID: 25605792; PMCID: PMC4402510.
- Johnson W.E. , Li C., Rabinovic A. Adjusting batch results in microarray expression knowledge utilizing empirical bayes strategies. Biostatistics. 2007; 8:118–127.
- Haghverdi, L., Lun, A., Morgan, M. et al. Batch results in single-cell RNA-sequencing knowledge are corrected by matching mutual nearest neighbors. Nat Biotechnol 36, 421–427 (2018). https://doi.org/10.1038/nbt.4091
- Lotfollahi, M., Wolf, F. A., & Theis, F. J. (2019). scGen predicts single-cell perturbation responses. Nature strategies, 16(8), 715-721.
- Zou, B., Zhang, T., Zhou, R., Jiang, X., Yang, H., Jin, X., & Bai, Y. (2021). deepMNN: deep learning-based single-cell RNA sequencing knowledge batch correction utilizing mutual nearest neighbors. Frontiers in Genetics, 1441.
- Yu, X., Xu, X., Zhang, J. et al. Batch alignment of single-cell transcriptomics knowledge utilizing deep metric studying. Nat Commun 14, 960 (2023). https://doi.org/10.1038/s41467-023-36635-5
- Z.A. Clarke, T.S. Andrews, J. Atif, D. Pouyabahar, B.T. Innes, S.A. MacParland, et al. Tutorial: pointers for annotating single-cell transcriptomic maps utilizing automated and guide strategies Nat Protoc, 16 (2021), pp. 2749-2764
- Wolf, F., Angerer, P. & Theis, F. SCANPY: large-scale single-cell gene expression knowledge evaluation. Genome Biol 19, 15 (2018). https://doi.org/10.1186/s13059-017-1382-0
- Mohit Goyal, Guillermo Serrano, Josepmaria Argemi, Ilan Shomorony, Mikel Hernaez, Idoia Ochoa, JIND: joint integration and discrimination for automated single-cell annotation, Bioinformatics, Quantity 38, Challenge 9, March 2022, Pages 2488–2495, https://doi.org/10.1093/bioinformatics/btac140
- H. Li, C.R. Brouwer, W. Luo A common deep neural community for in-depth cleansing of single-cell RNA-seq knowledge Nat Commun, 13 (2022), p. 1901
- Track T, Dai H, Wang S, Wang G, Zhang X, Zhang Y and Jiao L (2022) TransCluster: A Cell-Sort Identification Technique for single-cell RNA-Seq knowledge utilizing deep studying based mostly on transformer. Entrance. Genet. 13:1038919. doi: 10.3389/fgene.2022.1038919
- Dong X, Chowdhury S, Victor U, Li X, Qian L. Semi-Supervised Deep Studying for Cell Sort Identification From Single-Cell Transcriptomic Information. IEEE/ACM Trans Comput Biol Bioinform. 2023 Mar-Apr;20(2):1492-1505. doi: 10.1109/TCBB.2022.3173587. Epub 2023 Apr 3. PMID: 35536811.
- Xu, C., Lopez, R., Mehlman, E., Regier, J., Jordan, M. I., & Yosef, N. (2021). Probabilistic harmonization and annotation of single‐cell transcriptomics knowledge with deep generative fashions. Molecular Methods Biology, 17(1), e9620. https://doi.org/10.15252/msb.20209620
- Tasbiraha Athaya, Rony Chowdhury Ripan, Xiaoman Li, Haiyan Hu, Multimodal deep studying approaches for single-cell multi-omics knowledge integration, Briefings in Bioinformatics, Quantity 24, Challenge 5, September 2023, bbad313, https://doi.org/10.1093/bib/bbad313
- Gayoso, A., Lopez, R., Steier, Z., Regier, J., Streets, A., & Yosef, N. (2019). A Joint Mannequin of RNA Expression and Floor Protein Abundance in Single Cells. bioRxiv, 791947. https://www.biorxiv.org/content/early/2019/10/07/791947.abstract
- Chunman Zuo, Luonan Chen. Deep-joint-learning evaluation mannequin of single cell transcriptome and open chromatin accessibility knowledge. Briefings in Bioinformatics. 2020.
- Lotfollahi, M., Litinetskaya, A., & Theis, F. J. (2022). Multigrate: single-cell multi-omic knowledge integration.bioRxiv.https://www.biorxiv.org/content/early/2022/03/17/2022.03.16.484643
Source link
#microscope #range #cells
Unlock the potential of cutting-edge AI options with our complete choices. As a number one supplier within the AI panorama, we harness the ability of synthetic intelligence to revolutionize industries. From machine studying and knowledge analytics to pure language processing and laptop imaginative and prescient, our AI options are designed to reinforce effectivity and drive innovation. Discover the limitless potentialities of AI-driven insights and automation that propel what you are promoting ahead. With a dedication to staying on the forefront of the quickly evolving AI market, we ship tailor-made options that meet your particular wants. Be part of us on the forefront of technological development, and let AI redefine the best way you use and achieve a aggressive panorama. Embrace the longer term with AI excellence, the place potentialities are limitless, and competitors is surpassed.





: Bose, Shokz, JLab")




{kind=link}