


















Have you ever ever skilled a mannequin you thought was good, however then it failed miserably when utilized to actual world knowledge? If that’s the case, you’re in good firm. Machine studying processes are complicated, and it’s very simple to do issues that may trigger overfitting with out it being apparent. Within the 20 years or in order that I’ve been working in machine studying, I’ve seen many examples of this, prompting me to put in writing “How to avoid machine learning pitfalls: a guide for academic researchers” in an try to forestall different folks from falling into these traps.
However you don’t should take my phrase for it. These points are being more and more reported in each the scientific and well-liked press. Examples embrace the remark that hundreds of models developed during the Covid pandemic simply don’t work, and {that a} water high quality system deployed in Toronto frequently told people it was safe to bathe in dangerous water. Many of those are documented within the AIAAIC repository. It’s even been urged that these machine studying missteps are causing a reproducibility crisis in science — and, on condition that many scientists use machine studying as a key device as of late, a scarcity of belief in printed scientific outcomes.
On this article, I’m going to speak about a number of the points that may trigger a mannequin to look good when it isn’t. I’ll additionally speak about a number of the methods wherein these sorts of errors may be prevented, together with using the recently-introduced REFORMS checklist for doing ML-based science.
Duped by Information
Deceptive knowledge is an effective place to start out, or moderately not a superb place to start out, for the reason that complete machine studying course of rests upon the info that’s used to coach and take a look at the mannequin.
Within the worst instances, deceptive knowledge may cause the phenomenon often known as rubbish in rubbish out; that’s, you’ll be able to practice a mannequin, and probably get superb efficiency on the take a look at set, however the mannequin has no actual world utility. Examples of this may be discovered within the aforementioned review of Covid prediction models by Roberts et al. Within the rush to develop instruments for Covid prediction, quite a lot of public datasets turned accessible, however these had been later discovered to comprise deceptive indicators — akin to overlapping information, mislabellings and hidden variables — all of which helped fashions to precisely predict the category labels with out studying something helpful within the course of.
Take hidden variables. These are options which are current in knowledge, and which occur to be predictive of sophistication labels throughout the knowledge, however which aren’t straight associated to them. In case your mannequin latches on to those throughout coaching, it is going to seem to work properly, however might not work on new knowledge. For instance, in lots of Covid chest imaging datasets, the orientation of the physique is a hidden variable: individuals who had been sick had been extra prone to have been scanned mendacity down, whereas those that had been standing tended to be wholesome. As a result of they learnt this hidden variable, moderately than the true options of the illness, many Covid machine studying fashions turned out to be good at predicting posture, however dangerous at predicting Covid. Regardless of their identify, these hidden variables are sometimes in plain sight, and there have been many examples of classifiers latching onto boundary markers, watermarks and timestamps embedded in pictures, which frequently serve to tell apart one class from one other with out having to take a look at the precise knowledge.
A associated challenge is the presence of spurious correlations. Not like hidden variables, these haven’t any true relationship to anything within the knowledge; they’re simply patterns that occur to correlate with the category labels. A traditional instance is the tank problem, the place the US army allegedly tried to coach a neural community to establish tanks, but it surely really recognised the climate, since all the images of tanks had been taken on the similar time of day. Think about the pictures under: a machine studying mannequin might recognise all the images of tanks on this dataset simply by wanting on the color of pixels in direction of the highest of a picture, with out having to contemplate the form of any of the objects. The efficiency of the mannequin would seem nice, however it might be utterly ineffective in observe.
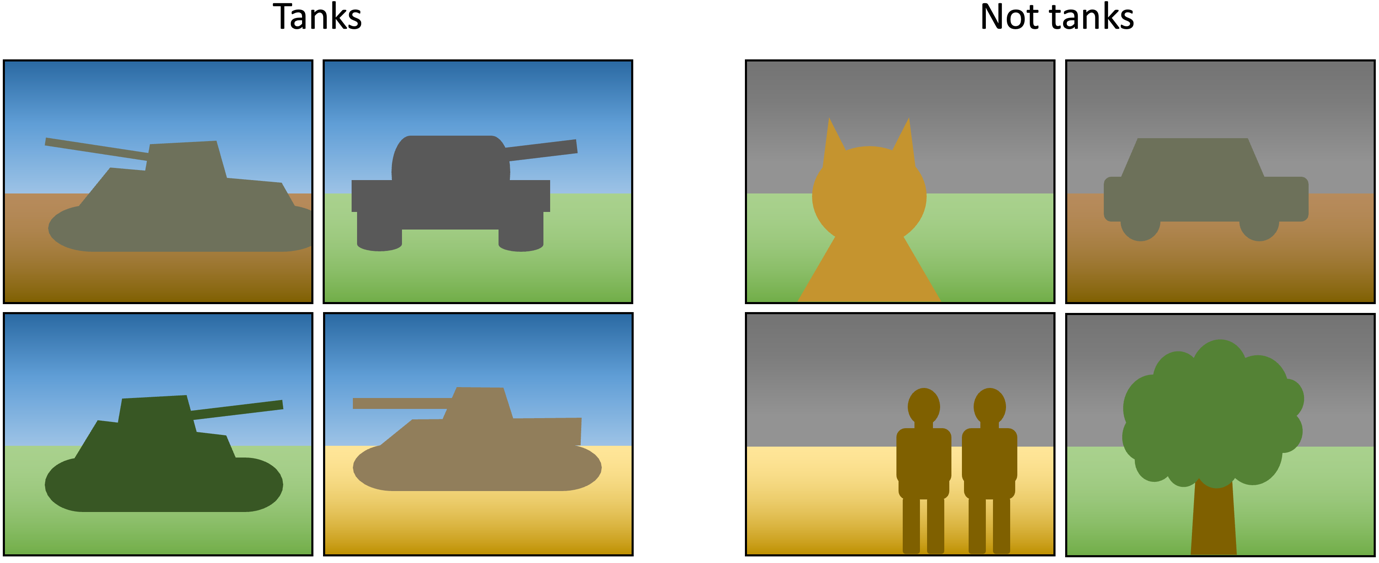
Many (maybe most) datasets comprise spurious correlations, however they’re not normally as apparent as this one. Frequent pc imaginative and prescient benchmarks, for instance, are known to have groups of background pixels that are spuriously correlated with class labels. This represents a specific problem to deep learners, which have the capability to mannequin many patterns throughout the knowledge; numerous research have proven that they do are inclined to seize spuriously correlated patterns, and this reduces their generality. Sensitivity to adversarial assaults is one consequence of this: if a deep studying mannequin bases its prediction on spurious correlations within the background pixels of a picture, then making small modifications to those pixels can flip the prediction of the mannequin. Adversarial coaching, the place a mannequin is uncovered to adversarial samples throughout coaching, can be utilized to handle this, but it surely’s costly. A neater method is simply to take a look at your mannequin, and see what info it’s utilizing to make its choices. For example, if a saliency map produced by an explainable AI approach means that your mannequin is specializing in one thing within the background, then it’s in all probability not going to generalise properly.
Typically it’s not the info itself that’s problematic, however moderately the labelling of the info. That is particularly the case when knowledge is labelled by people, and the labels find yourself capturing biases, misassumptions or simply plain previous errors made by the labellers. Examples of this may be seen in datasets used as picture classification benchmarks, akin to MNIST and CIFAR, which usually have a mislabelling fee of a few % — not an enormous quantity, however fairly important the place modellers are combating over accuracies within the tenths of a %. That’s, in case your mannequin does barely higher than the competitors, is it on account of an precise enchancment, or on account of modelling noise within the labelling course of? Issues may be much more troublesome when working with knowledge that has implicit subjectivity, akin to sentiment classification, the place there’s a hazard of overfitting explicit labellers.
Led by Leaks
Dangerous knowledge isn’t the one drawback. There’s loads of scope for errors additional down the machine studying pipeline. A standard one is knowledge leakage. This occurs when the mannequin coaching pipeline has entry to info it shouldn’t have entry to, notably info that confers a bonus to the mannequin. More often than not, this manifests as info leaks from the take a look at knowledge — and while most individuals know that take a look at knowledge must be saved impartial and never explicitly used throughout coaching, there are numerous refined ways in which info can leak out.
One instance is performing a data-dependent preprocessing operation on a whole dataset, earlier than splitting off the take a look at knowledge. That’s, making modifications to all the info utilizing info that was learnt by all the info. Such operations differ from the easy, akin to centering and scaling numerical options, to the complicated, akin to function choice, dimensionality discount and knowledge augmentation — however all of them have in widespread the truth that they use information of the entire dataset to information their final result. Which means information of the take a look at knowledge is implicitly getting into the mannequin coaching pipeline, even when it’s not explicitly used to coach the mannequin. As a consequence, any measure of efficiency derived from the take a look at set is prone to be an overestimate of the mannequin’s true efficiency.
Let’s take into account the only instance: centering and scaling. This entails wanting on the vary of every function, after which utilizing this info to rescale all of the values, usually in order that the imply is 0 and the usual deviation is 1. If that is finished on the entire dataset earlier than splitting off the take a look at knowledge, then the scaling of the coaching knowledge will embrace details about the vary and distribution of the function values within the take a look at set. That is notably problematic if the vary of the take a look at set is broader than the coaching set, for the reason that mannequin might probably infer this reality from the truncated vary of values current within the coaching knowledge, and do properly on the take a look at set simply by predicting values increased or decrease than these which had been seen throughout coaching. For example, should you’re engaged on inventory worth forecasting from time collection knowledge with a mannequin that takes inputs within the vary 0 to 1 but it surely solely sees values within the vary 0 to 0.5 throughout coaching, then it’s not too laborious for it to deduce that inventory costs will go up sooner or later.
In actual fact, forecasting is an space of machine studying that’s notably inclined to knowledge leaks, on account of one thing known as look forward bias. This happens when info the mannequin shouldn’t have entry to leaks from the longer term and artificially improves its efficiency on the take a look at set. This generally occurs when the coaching set comprises samples which are additional forward in time than the take a look at set. I’ll give an instance later of when this may occur, however should you work on this space, I’d additionally strongly advocate looking at this excellent review of pitfalls and best practices in evaluating time series forecasting models.
An instance of a extra complicated data-dependent preprocessing operation resulting in overly-optimistic efficiency metrics may be present in this review of pre-term birth prediction models. Mainly, a bunch of papers reported excessive accuracies at predicting whether or not a child can be born early, but it surely turned out that every one had utilized knowledge augmentation to the info set earlier than splitting off the take a look at knowledge. This resulted within the take a look at set containing augmented samples of coaching knowledge, and the coaching set containing augmented samples of take a look at knowledge — which amounted to a fairly important knowledge leak. When the authors of the assessment corrected this, the predictive efficiency of the fashions dropped from being close to excellent to not significantly better than random.
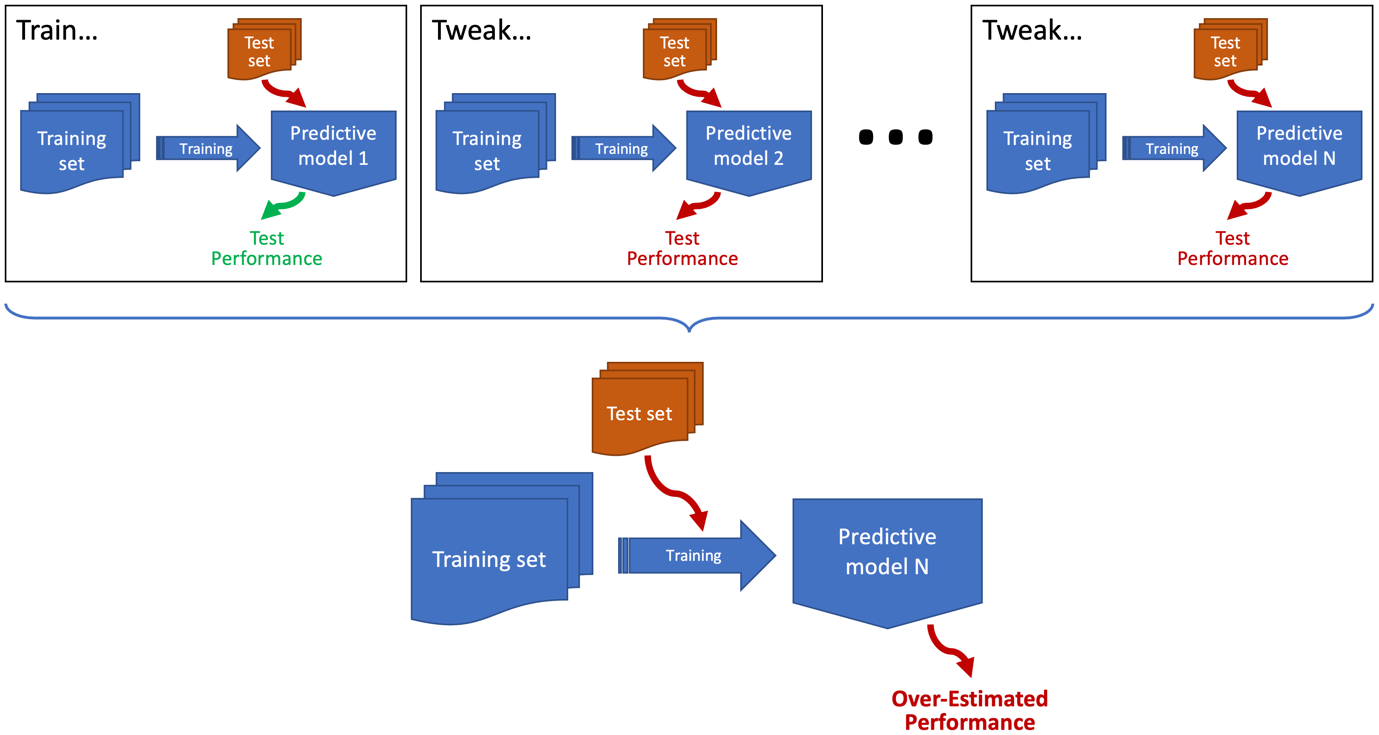
Oddly, one of the crucial widespread examples of knowledge leakage doesn’t have an agreed identify (the phrases overhyping and sequential overfitting have been urged) however is actually a type of coaching to the take a look at set. By the use of instance, think about the situation depicted above the place you’ve skilled a mannequin and evaluated it on the take a look at set. You then determined its efficiency was under the place you needed it to be. So, you tweaked the mannequin, and then you definately reevaluated it. You continue to weren’t pleased, so that you saved on doing this till its efficiency on the take a look at set was adequate. Sounds acquainted? Properly, it is a widespread factor to do, however should you’re creating a mannequin iteratively and utilizing the identical take a look at set to guage the mannequin after every iteration, then you definately’re mainly utilizing that take a look at set to information the event of the mannequin. The top result’s that you simply’ll overfit the take a look at set and possibly get an over-optimistic measure of how properly your mannequin generalises.
Apparently, the identical course of happens when folks use group benchmarks, akin to MNIST, CIFAR and ImageNet. Nearly everybody who works on picture classification makes use of these knowledge units to benchmark their approaches; so, over time, it’s inevitable that some overfitting of those benchmarks will happen. To mitigate towards this, it’s all the time advisable to make use of a various choice of benchmarks, and ideally attempt your approach on an information set which different folks haven’t used.
Misinformed by Metrics
When you’ve constructed your mannequin robustly, you then have to guage it robustly. There’s loads that may go unsuitable right here too. Let’s begin with an inappropriate selection of metrics. The traditional instance is utilizing accuracy with an imbalanced dataset. Think about that you simply’ve managed to coach a mannequin that all the time predicts the identical label, no matter its enter. If half of the take a look at samples have this label as their floor fact, then you definately’ll get an accuracy of fifty% — which is okay, a foul accuracy for a foul classifier. If 90% of the take a look at samples have this label, then you definately’ll get an accuracy of 90% — a superb accuracy for a foul classifier. This degree of imbalance isn’t unusual in actual world knowledge units, and when working with imbalanced coaching units, it’s not unusual to get classifiers that all the time predict the bulk label. On this case, it might be significantly better to make use of a metric like F rating or Matthews correlation coefficient, since these are much less delicate to class imbalances. Nevertheless, all metrics have their weaknesses, so it’s all the time finest to make use of a portfolio of metrics that give totally different views on a mannequin’s efficiency and failure modes.
Metrics for time collection forecasting are notably troublesome. There are quite a lot of them to select from, and essentially the most applicable selection can depend upon each the particular drawback area and the precise nature of the time collection knowledge. Not like metrics used for classification, most of the regression metrics utilized in time collection forecasting haven’t any pure scale, that means that uncooked numbers may be deceptive. For example, the interpretation of imply squared errors relies on the vary of values current within the time collection. For that reason, it’s vital to make use of applicable baselines along with applicable metrics. For example, this (already talked about) review of time series forecasting pitfalls demonstrates how most of the deep studying fashions printed at prime AI venues are literally much less good than naive baseline fashions. For example, they present that an autoformer, a form of complicated transformer mannequin designed for time collection forecasting, may be overwhelmed by a trivial mannequin that predicts no change on the subsequent time step — one thing that isn’t obvious from metrics alone.
On the whole, there’s a development in direction of creating more and more complicated fashions to resolve tough issues. Nevertheless, it’s vital to remember that some issues is probably not solvable, no matter how complicated the mannequin turns into. That is in all probability the case for a lot of monetary time collection forecasting issues. It’s additionally the case when predicting sure pure phenomena, notably these wherein a chaotic part precludes prediction past a sure time horizon. For example, many individuals assume that earthquakes cannot be predicted, but there are a bunch of papers reporting good efficiency on this job. This review paper discusses how these correct predictions may be due to a raft of modelling pitfalls, together with inappropriate selection of baselines and overfitting on account of knowledge sparsity, pointless complexity and knowledge leaks.
One other drawback is assuming {that a} single analysis is enough to measure the efficiency of a mannequin. Typically it’s, however quite a lot of the time you’ll be working with fashions which are stochastic or unstable; so, every time you practice them, you get totally different outcomes. Or it’s possible you’ll be working with a small knowledge set the place you would possibly simply get fortunate with a straightforward take a look at cut up. To handle each conditions, it’s commonplace to make use of resampling strategies like cross-validation, which practice and take a look at a mannequin on totally different subsets of the info after which work out the typical efficiency. Nevertheless, resampling introduces its personal dangers. One in all these is the elevated threat of knowledge leaks, notably when assuming that data-dependent preprocessing operations (like centering and scaling and have choice) solely have to be finished as soon as. They don’t; they have to be finished independently for every iteration of the resampling course of, and to do in any other case may cause an information leak. Beneath is an instance of this, exhibiting how function choice must be finished independently on the 2 coaching units (in blue) used within the first two iterations of cross-validation, and the way this leads to totally different options being chosen every time.
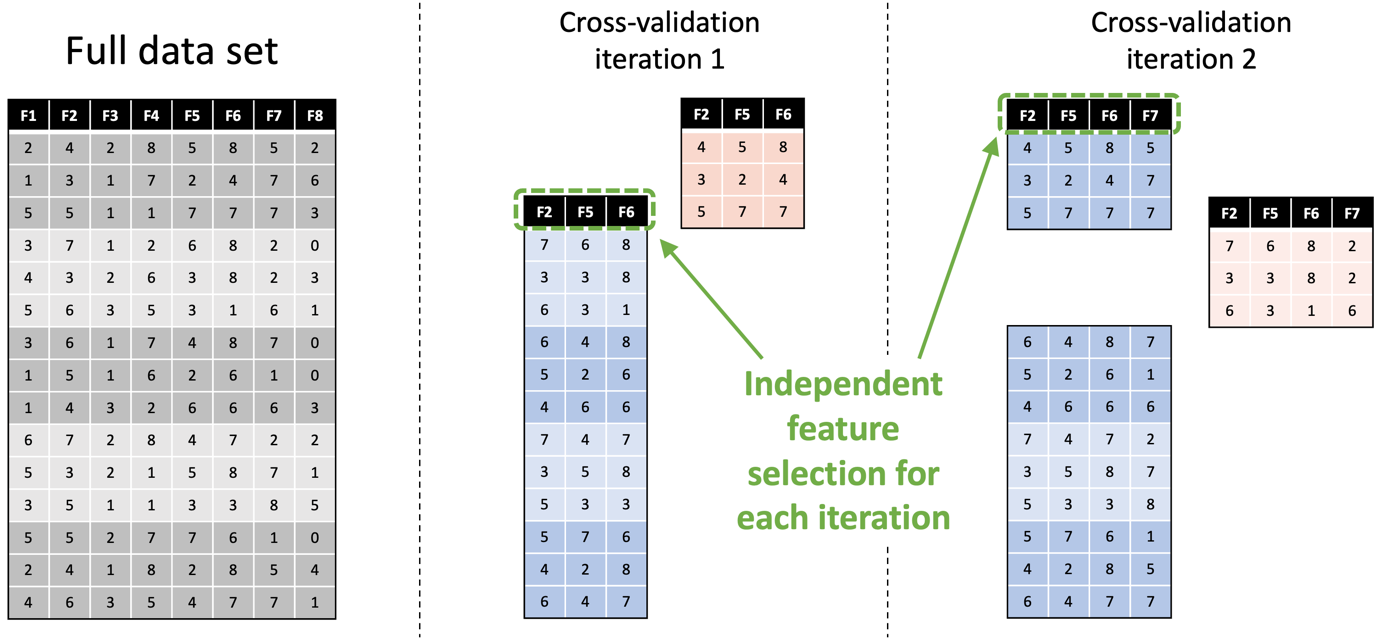
As I discussed earlier, the hazard of knowledge leaks is even better when working with time collection knowledge. Utilizing normal cross-validation, each iteration besides one will contain utilizing no less than one coaching fold that’s additional forward in time than the info within the take a look at fold. For instance, should you think about that the info rows within the determine above signify time-ordered multivariate samples, then the take a look at units (in pink) utilized in each iterations happen earlier within the time collection than all or a part of the coaching knowledge. That is an instance of a glance forward bias. Various approaches, akin to blocked cross-validation, can be utilized to forestall these.
A number of evaluations aren’t an choice for everybody. For instance, coaching a basis mannequin is each time-consuming and costly, so doing it repeatedly isn’t possible. Relying in your assets, this can be the case for even comparatively small deep studying fashions. If that’s the case, then additionally think about using different strategies for measuring the robustness of fashions. This consists of issues like utilizing explainability evaluation, performing ablation research, or augmenting take a look at knowledge. These can assist you to look past potentially-misleading metrics and achieve some appreciation of how a mannequin works and the way it would possibly fail, which in flip will help you determine whether or not to make use of it in observe.
Falling Deeper
To date, I’ve principally talked about basic machine studying processes, however the pitfalls may be even better when utilizing deep studying fashions. Think about using latent house fashions. These are sometimes skilled individually to the predictive fashions that use them. That’s, it’s commonplace to coach one thing like an autoencoder to do function extraction, after which use the output of this mannequin throughout the coaching of a downstream mannequin. When doing this, it’s important to make sure that the take a look at set used within the downstream mannequin doesn’t intersect with the coaching knowledge used within the autoencoder — one thing that may simply occur when utilizing cross-validation or different resampling strategies, e.g. when utilizing totally different random splits or not choosing fashions skilled on the identical coaching folds.
Nevertheless, as deep studying fashions get bigger and extra complicated, it may be more durable to make sure these sorts of knowledge leaks don’t happen. For example, should you use a pre-trained basis mannequin, it is probably not attainable to inform whether or not the info utilized in your take a look at set was used to coach the muse mannequin — notably should you’re utilizing benchmark knowledge from the web to check your mannequin. Issues get even worse should you’re utilizing composite fashions. For instance, should you’re utilizing a BERT-type basis mannequin to encode the inputs when fine-tuning a GPT-type basis mannequin, you need to keep in mind any intersection between the datasets used to coach the 2 basis fashions along with your individual fine-tuning knowledge. In observe, a few of these knowledge units could also be unknown, that means which you could’t be assured whether or not your mannequin is accurately generalising or merely reproducing knowledge memorised throughout pre-training.
Avoiding the Pits
These pitfalls are all too widespread. So, what’s one of the best ways to keep away from them? Properly, one factor you are able to do is use a guidelines, which is mainly a proper doc that takes you thru the important thing ache factors within the machine studying pipeline, and lets you establish potential points. In domains with high-stakes choices, akin to drugs, there are already quite a lot of well-established checklists, akin to CLAIM, and adherence to those is usually enforced by journals that publish in these areas.
Nevertheless, I’d prefer to briefly introduce a brand new child on the block: REFORMS, a consensus-based checklist for doing machine learning-based science. This was put collectively by 19 researchers throughout pc science, knowledge science, arithmetic, social sciences, and the biomedical sciences — together with myself — and got here out of a current workshop on the reproducibility crisis in ML‑based science. It’s supposed to handle the widespread errors that happen within the machine studying pipeline, together with a lot of these talked about on this article, in a extra domain-independent method. It consists of two elements: the guidelines itself, and in addition a paired steerage doc, which explains why every of the guidelines objects are vital. The guidelines works by means of the principle elements of a machine learning-based research, in every case encouraging the person to confirm that the machine studying course of is designed in such a means that it helps the general goals of the research, doesn’t stumble into any of the widespread pitfalls, and allows the outcomes to be verified by an impartial researcher. While it’s centered on the appliance of machine studying inside a scientific context, quite a lot of what it covers is extra typically relevant, so I’d encourage you to have a look even should you don’t take into account your work to be “science”.
One other means of avoiding pitfalls is to make higher use of instruments. Now, certainly one of my pet gripes relating to the present state of machine studying is that commonly-used instruments do little to forestall you from making errors. That’s, they’ll fortunately allow you to abuse the machine studying course of in all types of the way with out telling you what you’re doing is unsuitable. However, assist is offered within the type of experiment monitoring frameworks, which robotically preserve a document of the fashions you skilled and the way you skilled them, and this may be helpful for recognizing issues like knowledge leaks and coaching to the take a look at set. An open supply choice is MLFlow, however there are many business choices. MLOps instruments take this even additional, and assist to handle all of the shifting elements in a machine studying workflow, together with the folks.
Last Thought
It’s attainable to coach a superb mannequin that generalises properly to unseen knowledge, however I wouldn’t imagine this till you’re glad that nothing which might have gone unsuitable has gone unsuitable. A wholesome sense of suspicion is an effective factor: do take a look at your skilled mannequin to ensure it’s doing one thing smart, do analyse your metrics to know the place it’s making errors, do calibrate your outcomes towards applicable baselines, and do think about using checklists to be sure you haven’t ignored one thing vital.
Writer Bio
Michael is an Affiliate Professor at Heriot-Watt College, Edinburgh. He’s spent the final 20 years or so doing analysis on machine studying and bio-inspired computing. For more information see his academic website. He additionally writes about pc science extra typically in his Fetch Decode Execute substack.
Quotation
For attribution in educational contexts or books, please cite this work as
Michael Lones, "Why Doesn’t My Mannequin Work?", The Gradient, 2024.
BibTeX quotation:
@article{lones2024why,
writer = {Michael Lones},
title = {Why Doesn’t My Mannequin Work?},
journal = {The Gradient},
12 months = {2024},
howpublished = {url{https://thegradient.pub/why-doesnt-my-model-work},
}Source link
#Doesnt #Mannequin #Work
Unlock the potential of cutting-edge AI options with our complete choices. As a number one supplier within the AI panorama, we harness the ability of synthetic intelligence to revolutionize industries. From machine studying and knowledge analytics to pure language processing and pc imaginative and prescient, our AI options are designed to reinforce effectivity and drive innovation. Discover the limitless potentialities of AI-driven insights and automation that propel your corporation ahead. With a dedication to staying on the forefront of the quickly evolving AI market, we ship tailor-made options that meet your particular wants. Be a part of us on the forefront of technological development, and let AI redefine the best way you use and achieve a aggressive panorama. Embrace the longer term with AI excellence, the place potentialities are limitless, and competitors is surpassed.




: Bose, Shokz, JLab")




{kind=link}