
Executive Summary
- Refusing harmful requests is not a novel behavior learned in chat fine-tuning, as pre-trained base models will also refuse requests (48% of all harmful requests, 3% of harmless) just at a lower rate than chat models (90% harmful, 3% harmless)
- Further, for both Qwen 1.5 0.5B and Gemma 2 9B, chat fine-tuning reinforces the existing mechanisms. In both the chat and base models it is mediated by the refusal direction described in Arditi et al.
- We can both induce and bypass refusal in a pre-trained model, using a steering vector transferred from the chat model’s activations
- On the contrary, in LLaMA 1 7B (which was trained on data from before November 2022 and so can’t have had ChatGPT outputs in the pre-training data), we find evidence that chat fine-tuning learns additional / different refusal representations and mechanisms.
- We open source our code at https://github.com/ckkissane/base-models-refuse

Introduction
Chat models typically undergo safety fine-tuning to exhibit refusal behavior: they will refuse harmful requests, rather than complying with a helpful response.
It’s commonly assumed that “refusal is a behavior developed exclusively during fine-tuning, rather than pre-training” (Arditi et al.), as pre-trained models are trained to predict the next token on text scraped from the internet. We instead find that base models develop the capability to refuse during pre-training. This suggests that fine-tuning is not learning the capability from scratch.
We also build on work from Arditi et al. which finds a single direction in chat models to both bypass and induce refusals. In Gemma 2 9B and Qwen 1.5 0.5B, we find that this representation transfers to the base model. We apply this refusal direction to both induce and bypass refusals in the base model, suggesting that this refusal representation is already learned and used before fine-tuning. This suggests that chat fine-tuning is upweighting and enhancing the existing refusal circuitry for these models.
On the other hand, LLaMA 1 7B is messier. Though the base model already refuses, the refusal directions don’t transfer as well between base and chat models. This suggests that for this model, fine-tuning may be causing a more dramatic change to the internal mechanisms that cause refusals.
Looking forward, we think that understanding what fine-tuning does, or “model diffing”, is a very important question. Our work shows a case study where we were mistaken about what it did – we thought it had learned a whole new capability, but it often just upweighted existing circuits. Though this particular case was mostly debuggable with existing tools, it shows the importance of examining what fine-tuning does more systematically, and we believe this motivates investing more in research and tooling going forward.
Background and methodology
As most of our methodology directly builds on work from Arditi et al., much of this section is a recap of their methodology. The most important differences are that we often transfer steering vectors between chat and base models, and we need to consider how we prompt base models, as they aren’t constrained to the standard chat prompt templates.
Steering between models
As in Arditi et al. we find a “refusal direction” by taking the difference of mean activations from the model on harmful and harmless instructions. We use 32 instruction pairs in this work. However, we extract “refusal directions” from both the base and chat model, and apply them both separately.
With this “refusal direction”, we perform two different interventions as in Arditi et al. First, we “ablate” this direction from the model, essentially preventing the model from ever representing this direction. To do this, we compute the projection of each activation vector onto the refusal direction, and then subtract this projection away. As in Arditi et al., we ablate this direction in every token position and every layer. However, we ablate the refusal direction from the base model’s activations.
Where is an activation vector (from the base model) and is the “refusal direction” (extracted from either the base or chat model). Note that this is mathematically equivalent to editing the model’s weights to never write the refusal direction in the first place, as shown by Arditi et al.
We also induce refusals, by adding the “refusal direction” to base model’s activations during a forward pass. We simply add the refusal direction times some tunable coefficient to the residual stream. As in Arditi et al., we apply this vector at each token position, but only at the layer from which the refusal direction was extracted.
How we prompt the base models
Note that unlike base models, chat models are often prompted with a special template to clearly separate the user’s instructions from the model’s responses. For example, Qwen’s chat template looks like:
""<|im_start|>user
{instruction}<|im_end|>
<|im_start|>assistant
"""Surprisingly, we found that Qwen base has no issues with this template, so we just used the same template for our Qwen 1.5 0.5B evals.
However, we found that Gemma 2 9B would mostly just repeat the instruction or spout nonsense when given the Gemma chat prompt template. For this reason, we modify it slightly and use the following prompt for the base model:
"""user:
{instruction}
assistant:
""" This is slightly different from the chat template, which replaces “assistant” with “model”, and does not contain the “:” characters.
Finally, note that Vicuna 7B v1.1 (LLaMA 1 7B’s chat model) uses a system prompt:
"""A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: {instruction}
ASSISTANT:"""Since we don’t want to don’t want the base model to “cheat” with too much in context learning, we remove the system prompt when evaluating refusals for LLaMA 1 7B:
"""USER: {instruction}
ASSISTANT:"""Results
Base models refuse harmful requests
We first evaluate each base model’s ability to refuse 100 harmful instructions from JailbreakBench. We score completions with a similar “refusal score” metric used in Arditi et al., where we check if completions start with common refusal phrases like “I cannot”, “As an AI”, “I’m sorry”, etc. Note that we expect that this may miss some refusals, especially in the less constrained base models, but the interesting part is that so many trigger despite this.[1] We investigate models from three different model families: Qwen 1.5 0.5B, Gemma 2 9B, and LLaMA 1 7B. For comparison, we also display refusal scores for their corresponding chat models: Qwen 1.5 0.5B Chat, Gemma 2 9B IT, and Vicuna 7B v1.1:
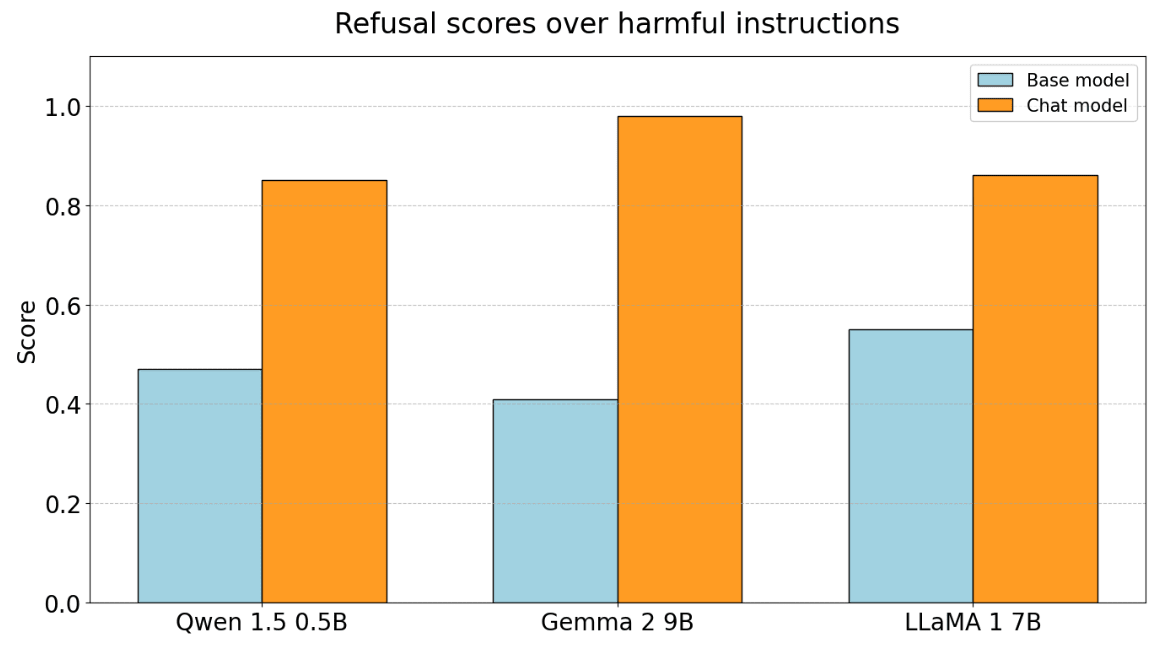
We find that on average, base models already refuse 48% of harmful requests by default, just at a lower rate than their chat models (90%). For Qwen 1.5 0.5B and Gemma 2 9B, many of the refusals are surprisingly similar to what we would expect from a chat model.

This implies that chat fine-tuning is not learning the refusal capability from scratch. Instead, models already learn some refusal circuitry during pre-training.
Eliciting more base model refusals with steering vectors
We now investigate the extent to which the base and chat models use the same representations and mechanisms for refusals. We find that, for Qwen 1.5 and Gemma 2, refusal in both the base and chat model is mediated by the “refusal direction” described in Arditi et al. This suggests that the fine-tuning is reinforcing this existing refusal mechanism. LLaMA 1 7B is messier, and we investigate this separately in Investigating (pre-ChatGPT model) LLaMA 1 7B.
We first show that we can induce more refusals in the base model by steering with the “refusal direction” from both the base and chat model’s activations. We generate both “baseline” (no intervention), and “intervention” completions, where we add the refusal direction across all token positions at just the layer at which the direction was extracted from. We first perform this experiment on 100 harmful instructions:
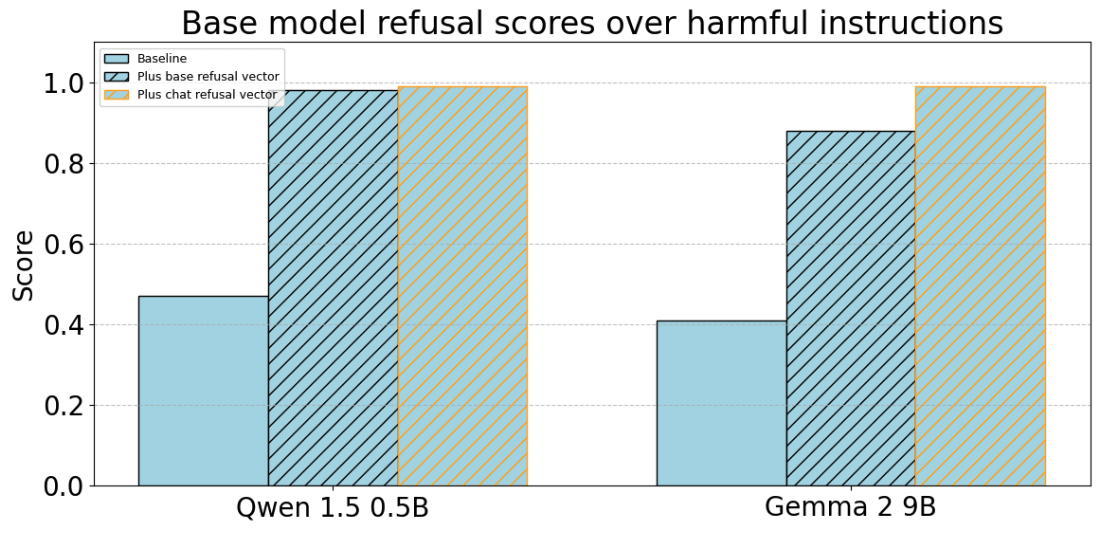
We find that steering with the refusal direction further causes the base models to refuse over 88% of harmful requests. Qualitatively, the outputs when steering with the base vs chat steering vector are almost always slightly different, though not dramatically. You can view 100 generations for each model in the appendix.

Similarly, we find that we can steer the base models to refuse harmless requests from Alpaca:
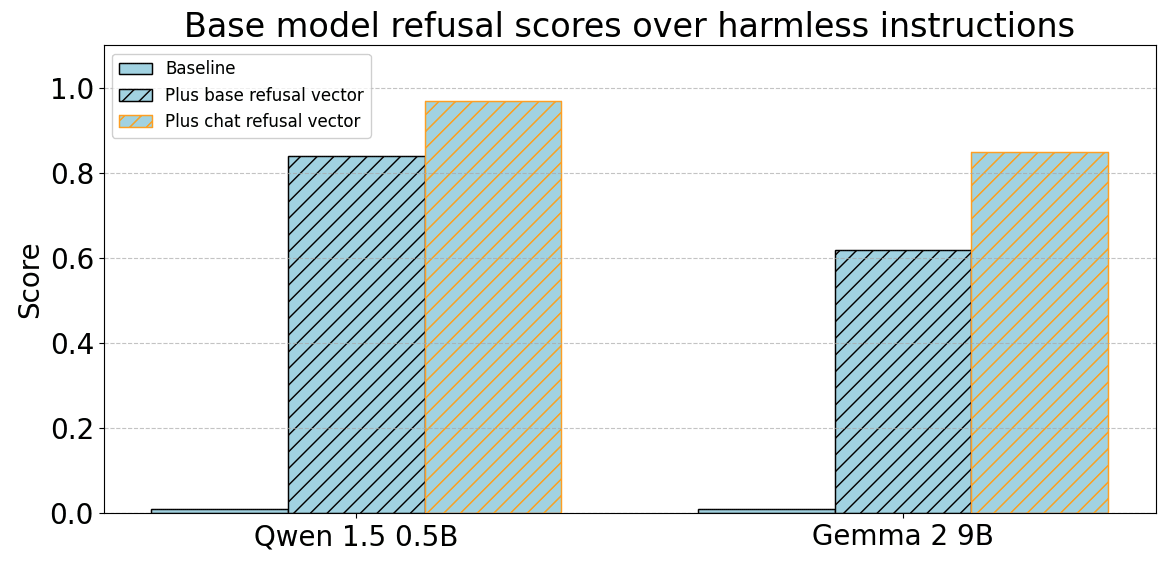

Bypassing refusal in base models
To further check that the Qwen 1.5 0.5B and Gemma 2 9B base model’s refusals are mediated by the same refusal representation as their chat models, we ablate the “refusal direction” from the base model’s activations. As in Arditi et al., we generate completions both without this ablation and with the ablation for 100 harmful instructions.
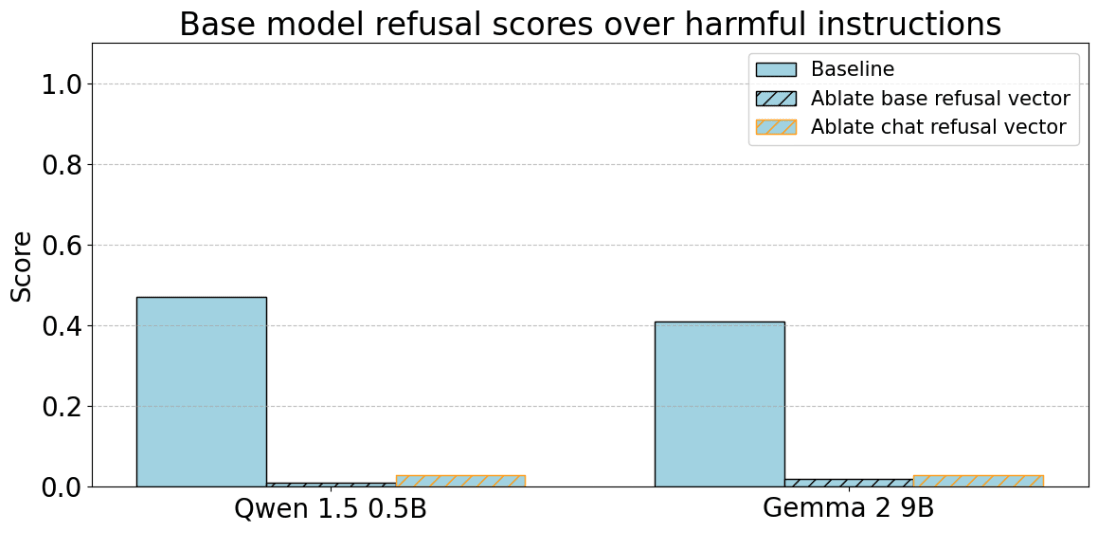
Mirroring results of Arditi et al., we find that ablating the refusal direction effectively nullifies the base model’s ability to refuse.

We believe that this is evidence that these base models already use the same refusal representations and mechanisms as the chat model, and thus chat fine-tuning is reinforcing the existing circuits.
Investigating (pre-ChatGPT model) LLaMA 1 7B
Both Gemma 2 9B and Qwen 1.5 0.5B were trained after the release of ChatGPT, which means that their refusals might be caused by the leakage of ChatGPT outputs into the pre-training dataset. For this reason, we also investigate LLaMA 1 7B, which is pre-trained on data before ChatGPT.[2] While we find that LLaMA 1 7B still refuses about half of harmful requests by default, the base and chat model’s refusals seem qualitatively different. This could suggest that chat fine-tuning may cause more dramatic differences to the refusal mechanisms in models trained before the release of ChatGPT.
The first line of evidence is qualitative: while the post-ChatGPT models often had chat-like refusal completions, LLaMA 1 7B refusals feel notably different than its chat model (Vicuna 7B v1.1). The base model often gives short and blunt statements, while the chat model refusals provide long, moralistic explanations.

One caveat is that the LLaMA 1 completions often seem a bit dumb in general (e.g. it sometimes just repeats the instruction).[3] It’s possible that this lack of general capability may cause the different results between LLaMA and the post-ChatGPT models we studied, rather than just the absence of ChatGPT outputs in LLaMA’s training data.
Regardless, we continue to find transfer of refusal directions for inducing refusal, suggesting that the base model already does have mechanisms to convert harmful representations to refusals.
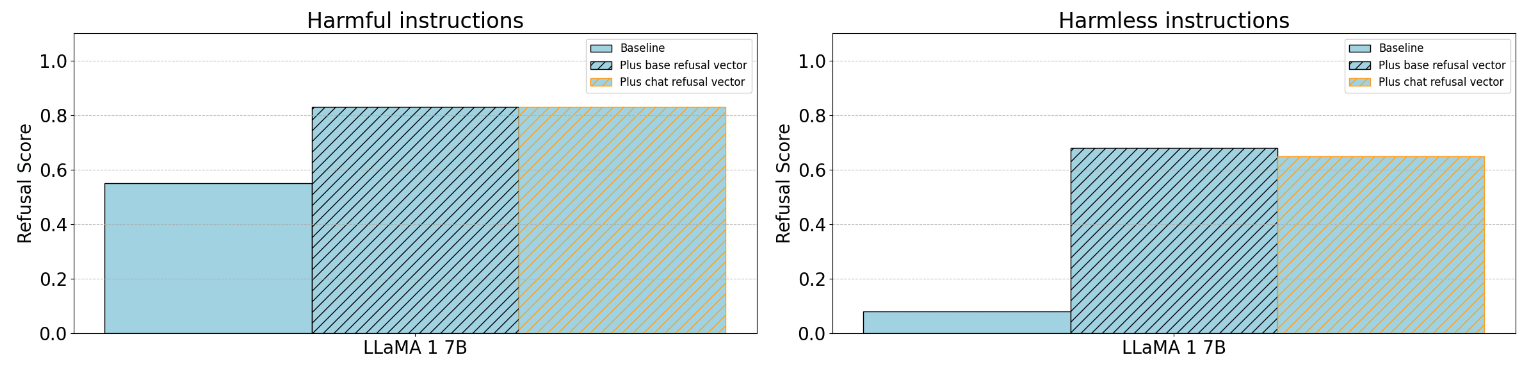
However, the steering vector derived from the base model’s activations often elicits a different flavor of refusal. We call this an “incompetent refusal”, where the model refuses a request by claiming it doesn’t understand or is incapable.

We also notice that the ablation technique does not seem to work for the LLaMA 1 7B base model on harmful requests. This is in contrast to the chat model, Vicuna 7B v1.1, where the ablation technique works with the refusal direction extracted from the chat activations, but not the base refusal vector.
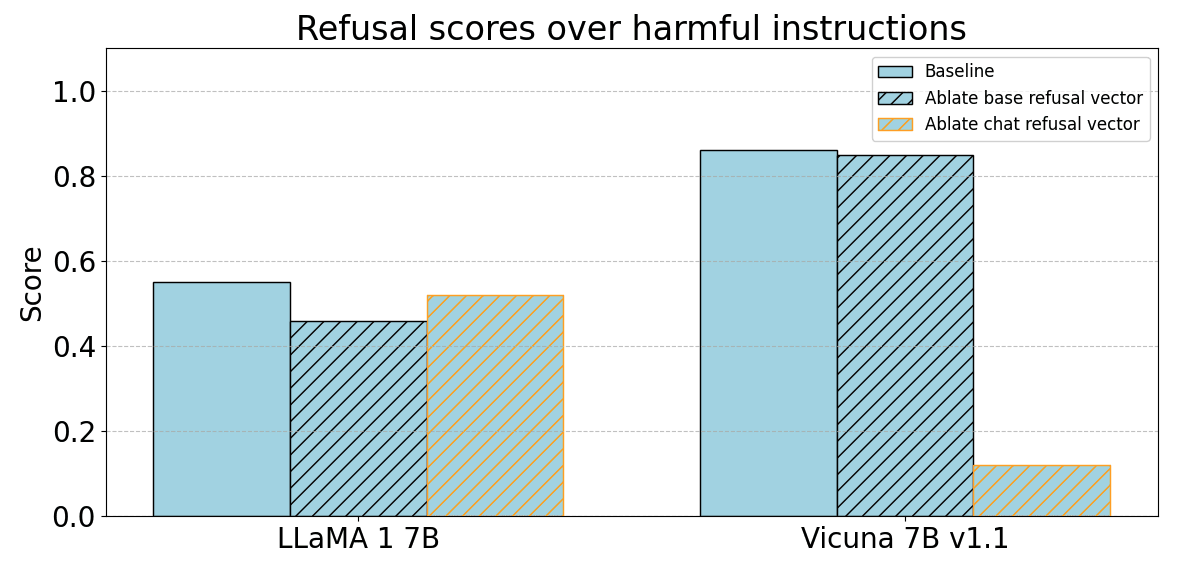
This might suggest that refusal in the LLaMA 1 7B base model is not mediated by a single direction.
Overall, it seems true that despite being trained pre-ChatGPT, LLaMA 1 7B models learn mechanisms to refuse harmful requests. However, unlike with Qwen 1.5 0.5B and Gemma 2 9B, it does not seem like chat fine-tuning is simply reinforcing these existing mechanisms. This could be a result of the leakage of ChatGPT transcripts into the pre-training distribution, though we don’t show that conclusively (e.g. this could just be because LLaMA 1 7B is less capable than newer models, or a result of newer and more sophisticated pre-training techniques). We are excited about further investment in techniques and tooling to better understand how fine-tuning changes internal mechanisms in future work.
This is a short research output, and we will fully review related work when this research work is turned into a paper.
For now, we recommend Turner et al. 2023, which introduced the activation steering technique. This technique has been built on by many follow-up works (Zou et al. 2023, Panickssery et al. 2023, etc).
For prior work on refusals, see the related work of Arditi et al. 2024. Tomani et al. study whether models refuse to answer factual questions, as well as measure the safety rate of base models, but don’t explicitly show the base models refuse safety-relevant prompts (rather than e.g. incompetently responding to them). Additionally, Jain et al. study what changes between pre-trained and fine-tuned models with some mech interp tools, and Prakash et al. show that activation patching can be used to transfer activations between pre-trained and fine-tuned models.
Panickssery et al. 2023 also investigates the transfer of refusal steering vectors from a base model to a chat model. We build on this as we additionally show that steering vectors can be transferred from the chat model to the base model.
[29th Sep 16:19 PST EDIT] We made these findings independently of Qi et al., 2024 who show in Table 1, Column 1 that Llama-2 7B base (knowledge cutoff Sep 2022) and Gemma-1 7B (knowledge cutoff 2023) also refuse according to correspondence with the author. Therefore our work was not the first to establish the narrow claim that
Conclusion
We showed that pre-trained models already have refusal circuitry, contrary to the popular belief that refusal is a behavior exclusively learned during fine-tuning. Further we found evidence that some base models (Qwen 1.5 0.5B and Gemma 2 9B) use the same refusal mechanisms as the chat model, while others (LLaMA 1 7B) almost seem to be lobotomized by fine-tuning.
While refusal is an interesting case study, we’re also excited about the general idea that pre-training LLMs can learn surprisingly rich capabilities that can be amplified during fine-tuning. We think this motivates the need for better tools to examine what fine-tuning does more systematically.
Limitations
We only investigated 3 models, and only one of which was purely trained with data before the release of ChatGPT. It’s not clear how much our results depend on details of the pre-training / fine-tuning set up, capability of the base model, etc.
Base model generations can vary significantly based on small edits to the prompt. For this reason, we don’t think we should over index on the exact base model refusal rates. The important part is that they refuse a significant amount by default.
Future Work
We are most excited about more systematic analysis of how fine-tuning changes model internals, ideally at the low level of being able to identify how features and circuits have changed.
Another exciting direction is to better understand refusal circuits. While prior work has found this challenging (Arditi et al.), exciting recent advancements in tooling like SAEs might make this more tractable (Lieberum et al.).
In this work, steering worked less well on LLaMA 1 and we would appreciate more insight. It seemed pretty different than Qwen and Gemma, and we don’t know why the refusal ablation technique worked so poorly on the base model. Perhaps it has an “incompetent refusal” direction that needs to be ablated using different data for the steering vector, or a different method.
Citing this work
This is ongoing research. If you would like to reference any of our current findings, we would appreciate reference to:
@misc{BaseLLMsRefuseToo,
author= {Connor Kissane and Robert Krzyzanowski and Arthur Conmy and Neel Nanda},
url = {https://www.alignmentforum.org/posts/YWo2cKJgL7Lg8xWjj/base-llms-refuse-too},
year = {2024},
howpublished = {Alignment Forum},
title = {Base LLMs Refuse Too},
}Author contributions statement
Connor was the core contributor on this project, and ran all of the experiments + wrote the post. Arthur and Neel gave guidance and feedback throughout the project.
Acknowledgements
We’d like to thank Wes Gurnee for helpful discussion and advice regarding studying fine-tuning at the start of this project. We’re also grateful to Andy Arditi for helpful discussions about refusals.
- ^
We also manually look at completions as a sanity check, as jailbreaks can be “empty” (Souly et al.).
- ^
See Section 2.1 of the LLaMA 1 paper: all the web-scrapes are before November 2022, and the other subsets such as GitHub and books make up less than 10% of the mixture, and would likely not include ChatGPT-style refusals anyway.
- ^
You can see more examples of LLaMA 1 completions, on both harmful and harmless requests, in the appendix.
Source link
#Base #LLMs #refuse #Alignment #Forum
ai improve text
ai text generator tools
best ai text generators
blues metronome
brain bravida
comfyui ndi
data governance failures
fivetran blind
h&r block taxes generative ai
insurance denials builds aipowered for fighting
Unlock the potential of cutting-edge AI solutions with our comprehensive offerings. As a leading provider in the AI landscape, we harness the power of artificial intelligence to revolutionize industries. From machine learning and data analytics to natural language processing and computer vision, our AI solutions are designed to enhance efficiency and drive innovation. Explore the limitless possibilities of AI-driven insights and automation that propel your business forward. With a commitment to staying at the forefront of the rapidly evolving AI market, we deliver tailored solutions that meet your specific needs. Join us on the forefront of technological advancement, and let AI redefine the way you operate and succeed in a competitive landscape. Embrace the future with AI excellence, where possibilities are limitless, and competition is surpassed.


