
This post includes a “flattened version” of an interactive diagram that cannot be displayed on this site. I recommend reading the original version of the post with the interactive diagram, which can be found here.
Over the last few months, ARC has released a number of pieces of research. While some of these can be independently motivated, there is also a more unified research vision behind them. The purpose of this post is to try to convey some of that vision and how our individual pieces of research fit into it.
Thanks to Ryan Greenblatt, Victor Lecomte, Eric Neyman, Jeff Wu and Mark Xu for helpful comments.
A bird’s eye view
To begin, we will take a “bird’s eye” view of ARC’s research.[1] As we “zoom in”, more nodes will become visible and we will explain the new nodes.
An interactive version of the diagrams below can be found here.
Zoom level 1

At the most zoomed-out level, ARC is working on the problem of “intent alignment“: how to design AI systems that are trying to do what their operators want. While many practitioners are taking an iterative approach to this problem, there are foreseeable ways in which today’s leading approaches could fail to scale to more intelligent AI systems, which could have undesirable consequences. ARC is attempting to develop algorithms that have a better chance of scaling gracefully to future AI systems, hence the term “scalable alignment“.
ARC’s particular approach to scalable alignment is a “builder-breaker” methodology (described in more detail here, and exemplified in the ELK report). Roughly speaking, if the scalability of an algorithm depends on unknown empirical contingencies (such as how advanced AI systems generalize), then we try to make worst-case assumptions instead of attempting to extrapolate from today’s systems. This is intended to create a feasible iteration loop for theoretical research. We are also conducting empirical research, but mostly to help generate and probe theoretical ideas rather than to test different empirical assumptions.
Zoom level 2
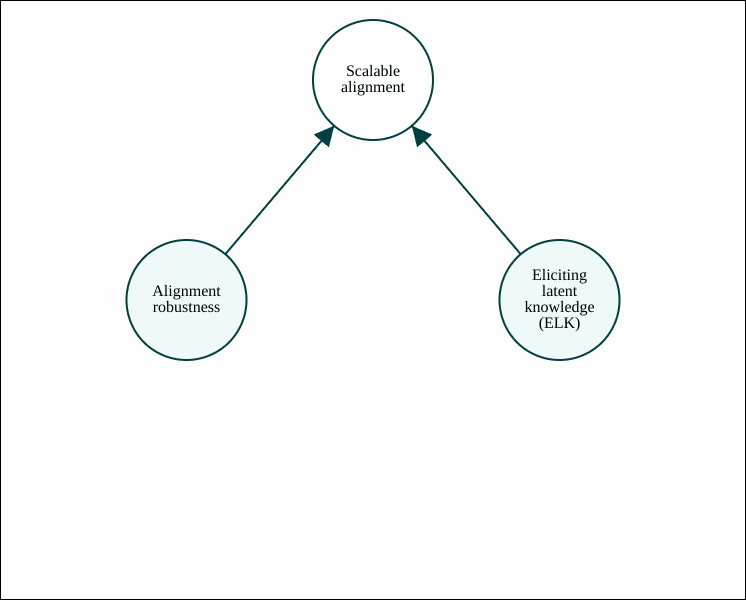
Most of ARC’s research attempts to solve one of two central subproblems in alignment: alignment robustness and eliciting latent knowledge (ELK).
Alignment robustness refers to AI systems remaining intent aligned even when faced with out-of-distribution inputs.[2] There are a few reasons to focus on failures of alignment robustness, as discussed here (where they are called “malign” failures). A quintessential example of an alignment robustness failure is deceptive alignment, also known as “scheming“: the possibility that an AI system will internally reason about the objective that it is being trained on, and stop being intent aligned when it detects clues that it has been taken out of its training environment.
Eliciting latent knowledge (ELK) is defined in this report, and asks: how can we train an AI system to honestly report its internal beliefs, rather than what it predicts a human would think? If we could do this, then we could potentially avoid misalignment by checking whether the model’s beliefs are consistent with its actions being helpful. ELK could help with scalable alignment via alignment robustness, but it could also help via outer alignment, by giving the reward function access to relevant information known by the model.
Zoom level 3
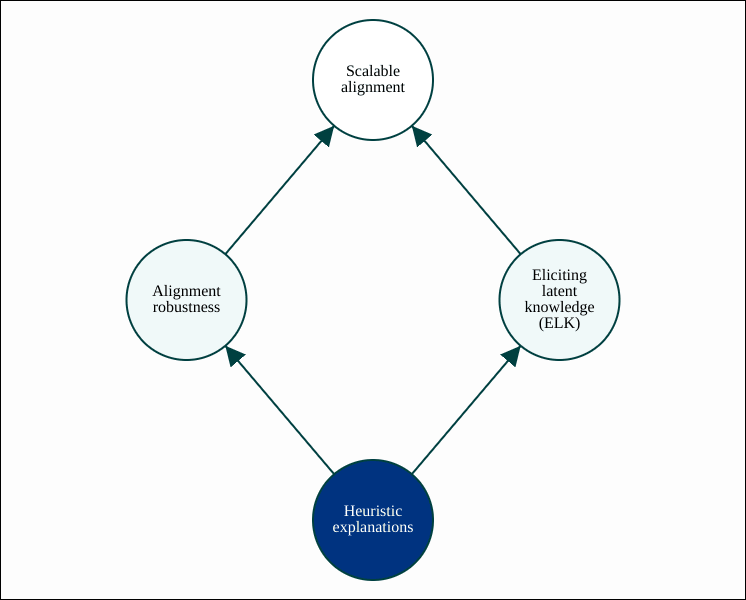
ARC hopes to make progress on both alignment robustness and ELK using heuristic explanations for neural network behaviors. A heuristic explanation is similar to the kind of explanation found in mechanistic interpretability, except that ARC is attempting to find a mathematical notion of an “explanation”, so that they can be found and used automatically. This is similar to how formal verification for ordinary programs can be performed automatically, except that we believe proof is too strict of a standard to be feasible. These similarities are discussed in more detail in the post Formal verification, heuristic explanations and surprise accounting (especially the first couple of sections, up until “Surprise accounting”).
A heuristic explanation for a rare but high-stakes kind of failure could help with alignment robustness, while a heuristic explanation for a specific behavior of interest could help with ELK. These two applications of heuristic explanations are fleshed out in more detail at the next zoom level.
Zoom level 4
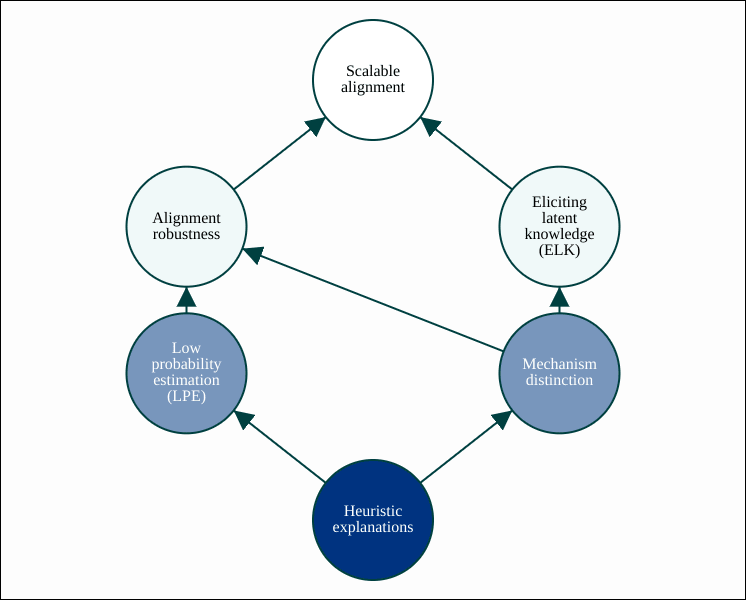
ARC has identified two broad ways in heuristic explanations could help with alignment robustness and/or ELK.
Low probability estimation (LPE) is the task of estimating the probability of a rare kind of model output. The most obvious approach to LPE is to try to find model inputs that give rise to such an output, but this can be infeasible (e.g. if the model were to implement something like a cryptographic hash function). Instead, we can “relax” this goal and search for a heuristic explanation of why the model could hypothetically produce such an output (e.g. by treating the output of the cryptographic hash function as random). LPE would help with alignment robustness by allowing us to select models for which we cannot explain why they would ever behave catastrophically, even hypothetically. This motivation for LPE is discussed in much greater depth in the post Estimating Tail Risk in Neural Networks.
Mechanism distinction describes our broad hope for how heuristic explanations could help with ELK. A central challenge for ELK is “sensor tampering”: detecting when the model reports what it predicts a human would think, but the human has been fooled in some way. Our hope is to detect this by noticing that the model’s report has been produced by an “abnormal mechanism”. There are a few potential ways in which heuristic explanations could be used to perform mechanism distinction, but the one we currently consider the most promising is mechanistic anomaly detection (MAD), as explained in the post Mechanistic anomaly detection and ELK (for a gentler introduction to MAD, see this post). A variant of MAD is safe distillation, which is an alternative way to perform mechanism distinction if we also have access to a formal specification of what we are trying to elicit latent knowledge of.
A semi-formal account of how heuristic explanations could enable all of LPE, MAD and safe distillation is given in Towards a Law of Iterated Expectations for Heuristic Estimators. An explanation of how MAD could also be used to help with alignment robustness is given in Mechanistic anomaly detection and ELK (in the section “Deceptive alignment”).
How ARC’s research fits into this picture
We will now explain how some of ARC’s research fits into the above diagram at the most zoomed in level. For completeness, we will cover all of ARC’s most significant pieces of published research to date, in chronological order. Each piece of work has been labeled with the most closely related node from the diagram, but often also covers nearby nodes and the relationships between them.
| Eliciting latent knowledge: How to tell if your eyes deceive you defines ELK, explains its importance for scalable alignment, and covers a large number of possible approaches to ELK. Some of these approaches are somewhat related to heuristic explanations, but most are alternatives that we are no longer pursuing. |  |
| Formalizing the presumption of independence lays out the problem of devising a formal notion of heuristic explanations, and makes some early inroads into this problem. It also includes a brief discussion of the motivation for heuristic explanations and the application to alignment robustness and ELK. |  |
| Mechanistic anomaly detection and ELK and our other late 2022 blog posts (1, 2, 3) explain the approach to mechanism distinction that we currently find the most promising, mechanistic anomaly detection (MAD). They also cover how mechanism distinction could be used to address alignment robustness and ELK, how heuristic explanations could be used for mechanism distinction, and the feasibility of finding heuristic explanations. |  |
| Formal verification, heuristic explanations and surprise accounting discusses the high-level motivation for heuristic explanations by comparing and contrasting them to formal verification for neural networks (as explored in this paper) and mechanistic interpretability. It also introduces surprise accounting, a framework for quantifying the quality of a heuristic explanation, and presents a draft of empirical work on heuristic explanations. | |
| Backdoors as an analogy for deceptive alignment and the associated paper Backdoor defense, learnability and obfuscation discuss a formal notion of backdoors in ML models and some theoretical results about it. This serves as an analogy for the subdiagram Heuristic explanations → Mechanism distinction → Alignment robustness. In this analogy, alignment robustness corresponds to a model being backdoor-free, mechanism distinction corresponds to the backdoor defense, and heuristic explanations correspond to so-called “mechanistic” defenses. The blog post covers this analogy in more depth. |  |
| Estimating Tail Risk in Neural Networks lays out the problem of low probability estimation, how it would help with alignment robustness, and possible approaches to LPE based on heuristic explanations. It also presents a draft describing an approach to heuristic explanations based on analytically learning variational autoencoders. |  |
| Towards a Law of Iterated Expectations for Heuristic Estimators and the associated paper discuss a possible coherence property for heuristic explanations as part of the search for a formal notion of heuristic explanations. It also provides a semi-formal account of how heuristic explanations could be applied to low probability estimation and mechanism distinction. | |
| Low Probability Estimation in Language Models and the associated paper Estimating the Probabilities of Rare Outputs in Language Models describe an empirical study of LPE in the context of small transformer language models. The method inspired by heuristic explanations outperforms naive sampling in this setting, but does not outperform methods based on red-teaming (searching for inputs giving rise to the rare behavior), although there remain theoretical cases where red-teaming fails. | |
Further subproblems
ARC’s research can be subdivided further, and we have been putting significant effort into a number of subproblems not explicitly mentioned above. For instance, our work on heuristic explanations includes both work on formalizing heuristic explanations (devising a formal framework for heuristic explanations) and work on finding heuristic explanations (designing efficient search algorithms for them). Some subproblems of these include:
- Measuring quality: “surprise accounting” offers a potential way to measure the quality of a heuristic explanation, which is important for being able to search for high-quality explanations. However, it is currently an informal framework with many missing details.
- Capacity allocation: it will probably be too challenging to find high-quality explanations for every aspect of a model’s behavior. Instead, we can try to tailor explanations towards behaviors with potentially catastrophic consequences. A good loss function for heuristic explanations should push for quality only where it is relevant to the behavior at hand.
- Cherry-picking: if we use a heuristic explanation to estimate something (as in low probability estimation), we need to make sure that the way in which we find the explanation doesn’t systematically bias the estimate.
- Form of representation: one form that a heuristic explanation could take is of an “activation model“, i.e. a probability distribution over a model’s internal activations. However, we may also need to represent explanations that do not correspond to any particular probability distribution.
- Formal desiderata: we can attempt to formalize heuristic explanations by considering properties that we think they should satisfy, and seeing if those properties can be satisfied.
- No-coincidence principle: in order for heuristic explanations to work in the worst case, we need every possible behavior to be amenable to explanation. We sometimes refer to this desideratum as the “no-coincidence principle” (a term taken from this paper). Counterexamples to this principle could present obstacles to our approach.
- Empirical regularities: some model weights may have no explanation beyond being tuned to match some empirical average, either because the input distribution is defined empirically, or because of an emergent regularity in a formally-defined system (such as the relative value of a queen and a pawn in chess). A good notion of heuristic explanations should be able to deal with these.
Conclusion
We have painted a high-level picture of ARC’s research, explained how our published research fits into it, and briefly discussed some additional subproblems that we are working on. We hope this provides people with a clearer sense of what we are up to.
-
An arrow in the diagram expresses that solving one problem should help solve another, but it varies from case to case whether subproblems combine “conjunctively” (all subproblems need to be solved to solve the main problem) or “disjunctively” (a solution to any subproblem can be used to solve the main problem). ↩︎
-
The term “alignment robustness” comes from this summary of this post, and is synonymous with “objective robustness” in the terminology of this post. A slightly more formal variant is “high-stakes alignment”, as defined in this post. ↩︎
Source link
#birds #eye #view #ARCs #research #Alignment #Forum
Unlock the potential of cutting-edge AI solutions with our comprehensive offerings. As a leading provider in the AI landscape, we harness the power of artificial intelligence to revolutionize industries. From machine learning and data analytics to natural language processing and computer vision, our AI solutions are designed to enhance efficiency and drive innovation. Explore the limitless possibilities of AI-driven insights and automation that propel your business forward. With a commitment to staying at the forefront of the rapidly evolving AI market, we deliver tailored solutions that meet your specific needs. Join us on the forefront of technological advancement, and let AI redefine the way you operate and succeed in a competitive landscape. Embrace the future with AI excellence, where possibilities are limitless, and competition is surpassed.








/cdn.vox-cdn.com/uploads/chorus_asset/file/23982579/acastro_STK466_01.jpg?w=150&resize=150,150&ssl=1 "Snap says New Mexico intentionally friended alleged child predators, then blamed the company")
