


















LLM-based chatbots’ capabilities have been advancing each month. These enhancements are principally measured by benchmarks like MMLU, HumanEval, and MATH (e.g. sonnet 3.5, gpt-4o). Nevertheless, as these measures get an increasing number of saturated, is consumer expertise rising in proportion to those scores? If we envision a way forward for human-AI collaboration quite than AI changing people, the present methods of measuring dialogue programs could also be inadequate as a result of they measure in a non-interactive vogue.
Why does purposeful dialogue matter?
Purposeful dialogue refers to a multi-round user-chatbot dialog that facilities round a objective or intention. The objective may vary from a generic one like “innocent and useful” to extra particular roles like “journey planning agent”, “psycho-therapist” or “customer support bot.”
Journey planning is a straightforward, illustrative instance. Our preferences, fellow vacationers’ desire, and all of the complexities of real-world conditions make transmitting all info in a single cross method too expensive. Nevertheless, if a number of back-and-forth exchanges of data are allowed, solely essential info will get selectively exchanged. Negotiation principle affords an analogy of this—iterative bargaining yields higher outcomes than a take-it-or-leave-it supply.
Actually, sharing info is just one side of dialogue. In Terry Winograd’s phrases: “All language use could be regarded as a method of activating procedures inside the hearer.” We will consider every utterance as a deliberate motion that one celebration takes to change the world mannequin of the opposite. What if each events have extra sophisticated, even hidden objectives? On this method, purposeful dialogue gives us with a method of formulating human-AI interactions as a collaborative recreation, the place the objective of chatbot is to assist people obtain sure objectives.
This would possibly appear to be an pointless complexity that’s solely a priority for lecturers. Nevertheless, purposeful dialogue could possibly be useful even for probably the most hard-nosed, product-oriented analysis course like code era. Present coding benchmarks principally measure performances in a one-pass era setting; nevertheless, for AI to automate fixing abnormal Github points (like in SWE-bench), it’s unlikely to be achieved by a single motion—the AI wants to speak forwards and backwards with human software program engineers to verify it understands the right necessities, ask for lacking documentation and information, and even ask people to offer it a hand if wanted. In the same vein to pair programming, this might cut back the defects of code however with out the burden of accelerating man-hours.
Furthermore, with the introduction of turn-taking, many new potentialities could be unlocked. As interactions develop into long-term and reminiscence is constructed, the chatbot can regularly replace consumer profiles. It could actually additionally adapt to their preferences. Think about a private assistant (e.g., IVA, Siri) that, by way of every day interplay, learns your preferences and intentions. It could actually learn your sources of latest info routinely (e.g., twitter, arxiv, Slack, NYT) and offer you a morning information abstract based on your preferences. It could actually draft emails for you and hold bettering by studying out of your edits.
In a nutshell, significant interactions between individuals hardly ever start with full strangers and conclude in only one alternate. People naturally work together with one another by way of multi-round dialogues and adapt accordingly all through the dialog. Nevertheless, doesn’t that appear precisely the alternative of predicting the following token, which is the cornerstone of recent LLMs? Under, let’s check out the makings of dialogue programs.
How have been/are dialogue programs made?
Let’s bounce again to the Seventies, when Roger Schank launched his “restaurant script” as a type of dialogue system [1]. This script breaks down the everyday restaurant expertise into steps like getting into, ordering, consuming, and paying, every with particular scripted utterances. Again then, every bit of dialogue in these situations was rigorously deliberate out, enabling AI programs to imitate real looking conversations. ELIZA, a Rogerian psychotherapist simulator, and PARRY, a system mimicking a paranoid particular person, have been two different early dialogue programs till the daybreak of machine studying.
Evaluate this method to the LLM-based dialogue system at this time, it appears mysterious how fashions skilled to foretell the following token may do something in any respect with participating in dialogues. Subsequently, let’s take an in depth examination of how dialogue programs are made, with an emphasis on how the dialogue format comes into play:
(1) Pretraining: a sequence mannequin is skilled to foretell the following token on a big corpus of combined web texts. The compositions could fluctuate however they’re predominantly information, books, Github code, with a small mix of forum-crawled information corresponding to from Reddit, Stack Trade, which can comprise dialogue-like information.
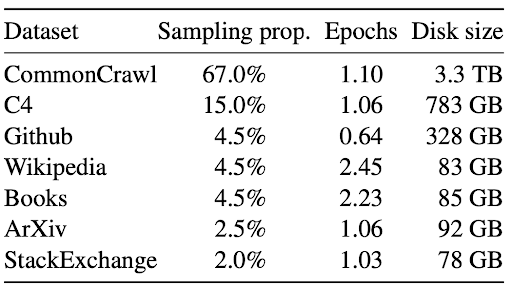
(2) Introduce dialogue formatting: as a result of the sequence mannequin solely processes strings, whereas probably the most pure illustration of dialogue historical past is a structured index of system prompts and previous exchanges, a sure type of formatting should be launched for the aim of conversion. Some Huggingface tokenizers present this methodology referred to as tokenizer.apply_chat_template for the comfort of customers. The precise formatting differs from mannequin to mannequin, however it often includes guarding the system prompts with

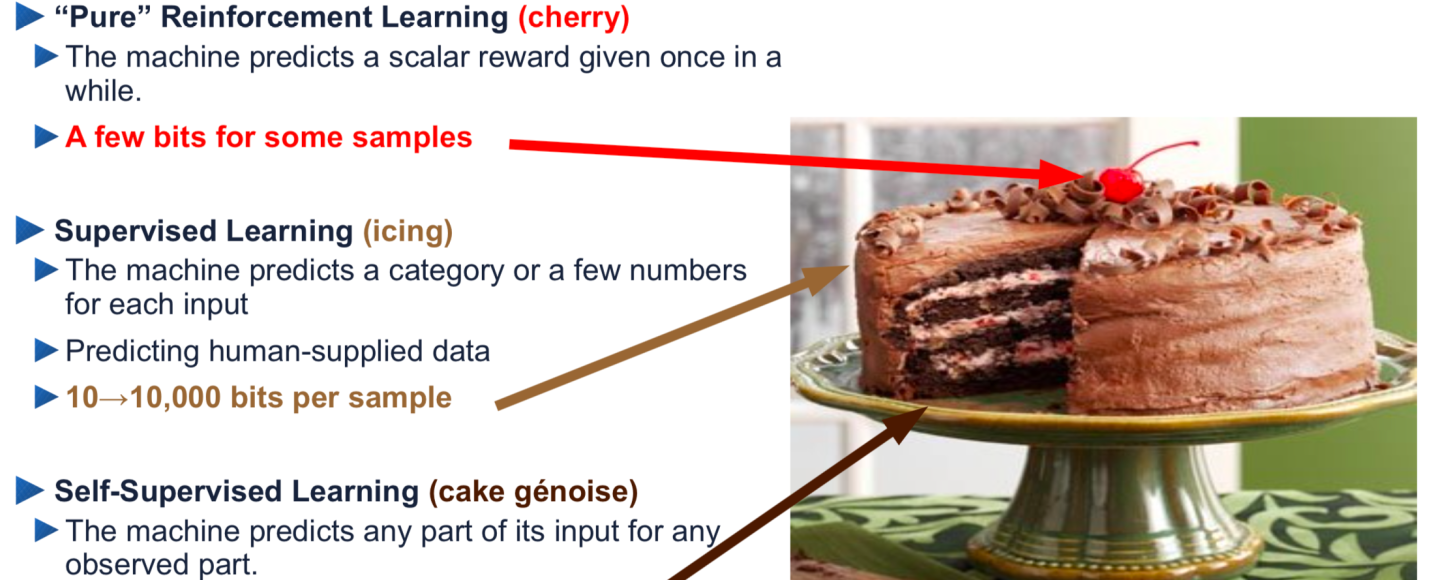
(3) RLHF: On this step, the chatbot is instantly rewarded or penalized for producing desired or undesired solutions. It’s value noting that that is the primary time the launched dialogue formatting seems within the coaching information. RLHF is a effective-tuning step not solely as a result of the information dimension is dwarfed compared to the pretraining corpus, but additionally because of the KL penalty and focused weight tuning (e.g. Lora). Utilizing Lecun’s analogy of cake baking, RLHF is just the small cherry on the highest.
How constant are current dialogue programs (in 2024)?
The minimal requirement we may have for a dialogue system is that it may keep on the duty we gave them. Actually, we people typically drift from matter to matter. How properly do present programs carry out?
At the moment, “system immediate” is the principle methodology that enables customers to manage LM habits. Nevertheless, researchers discovered proof that LLMs could be brittle in following these directions below adversarial circumstances [12,13]. Readers may also have skilled this by way of every day interactions with ChatGPT or Claude—when a brand new chat window is freshly opened, the mannequin can observe your instruction fairly properly [2], however after a number of rounds of dialogue, it’s not contemporary, even stops following its position altogether.
How may we quantitatively seize this anecdote? For one-round instruction following, we’ve already loved loads of benchmarks corresponding to MT-Bench and Alpaca-Eval. Nevertheless, after we take a look at fashions in an interactive vogue, it’s laborious to anticipate what the mannequin generates and put together a reply upfront. In a challenge by my collaborators and me [3], we constructed an atmosphere to synthesize dialogues with limitless size to stress-test the instruction-following capabilities of LLM chatbots.
To permit an unconstrained scaling on the time scale, we let two system-prompted LM brokers chat with one another for an prolonged variety of rounds. This varieties the principle trunk of dialogue [a1, b1, a2, b2, …, a8, b8] (say the dialogue is 8-round). At this level, we may most likely determine how the LLMs keep on with its system prompts simply by analyzing this dialogue, however most of the utterances could be irrelevant to the directions, relying on the place the dialog goes. Subsequently, we hypothetically department out at every spherical by asking a query instantly associated to the system prompts, and use a corresponding judging perform to quantify how properly it performs. All that is offered by the dataset is a financial institution of triplets of (system prompts, probe questions, and judging features).
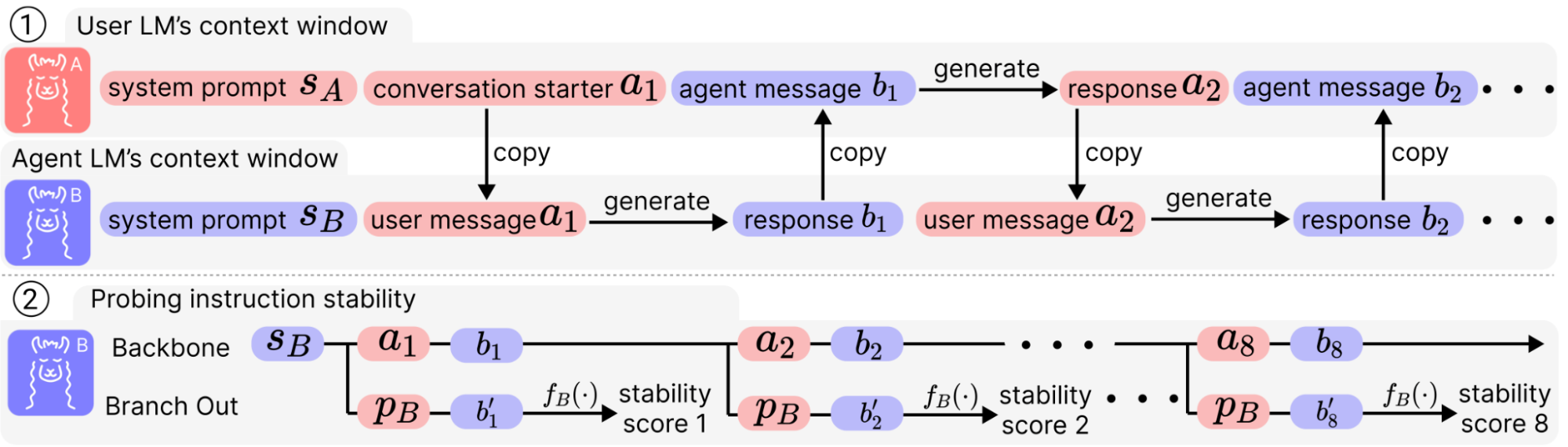
Averaging throughout situations and pairs of system prompts, we get a curve of instruction stability throughout rounds. To our shock, the aggregated outcomes on each LLaMA2-chat-70B and gpt-3.5-turbo-16k are alarming. In addition to the added issue to immediate engineering, the dearth of instruction stability additionally comes with security issues. When the chatbot drifts away from its system prompts that stipulate security features, it turns into extra prone to jailbreaking and vulnerable to extra hallucinations.
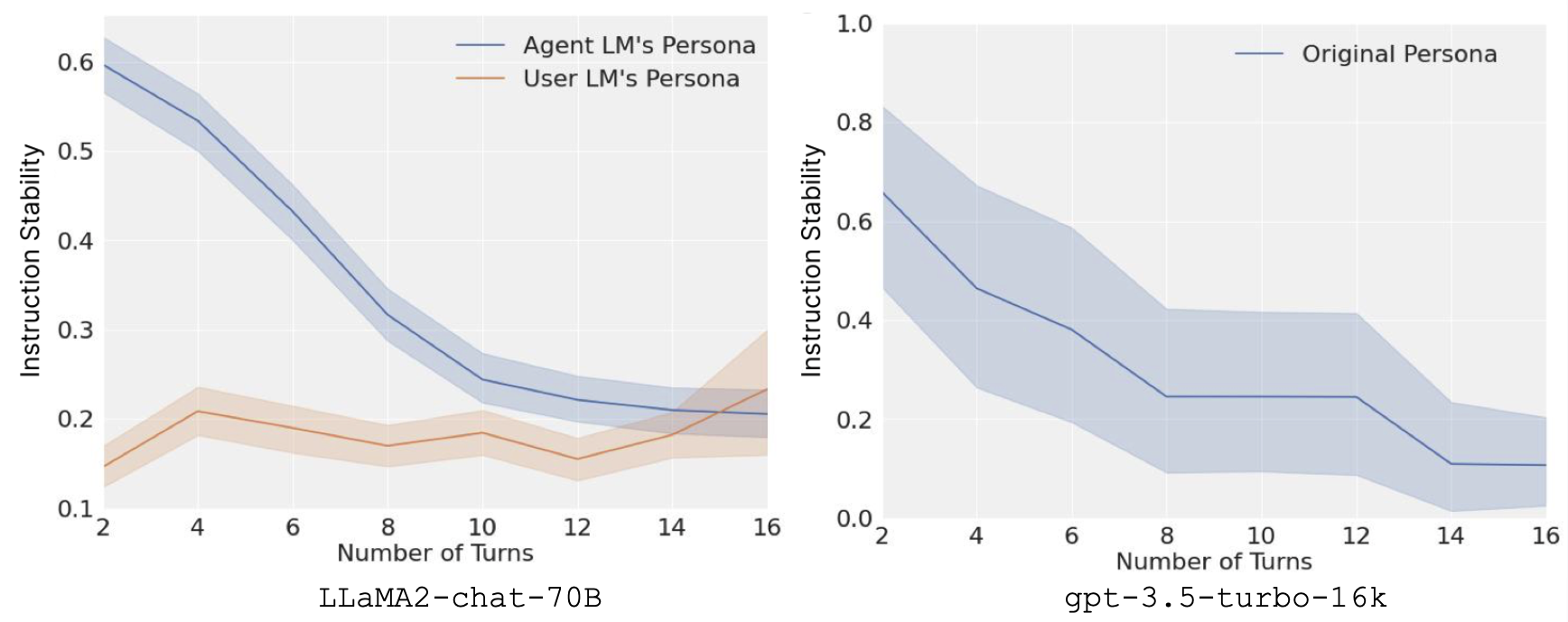
The empirical outcomes additionally distinction with the ever-increasing context size of LLMs. Theoretically, some long-context fashions can attend to a window of as much as 100k tokens. Nevertheless, within the dialogue setting, they develop into distracted after just one.6k tokens (assuming every utterance is 100 tokens). In [3], we additional theoretically confirmed how that is inevitable in a Transformer based mostly LM chatbot below the present prompting scheme, and proposed a easy approach referred to as split-softmax to mitigate such results.
One would possibly ask at this level, why is it so dangerous? Why do not people lose their persona simply by speaking to a different particular person for 8 rounds? It’s debatable that human interactions are based mostly on functions and intentions [5] and these functions precede the means quite than the alternative—LLM is essentially a fluent English generator, and the persona is merely a skinny added layer.
What’s lacking?
Pretraining?
Pretraining endows the language mannequin with the aptitude to mannequin a distribution over web personas in addition to the lower-level language distribution of every persona [4]. Nevertheless, even when one persona (or a combination of a restricted variety of them) is specified by the instruction of system prompts, present approaches fail to single it out.
RLHF?
RLHF gives a strong resolution to adapting this multi-persona mannequin to a “useful and innocent assistant.” Nevertheless, the unique RLHF strategies formulate reward maximization as a one-step bandit drawback, and it isn’t typically attainable to coach with human suggestions within the loop of dialog. (I’m conscious of many advances in alignment however I need to focus on the unique RLHF algorithm as a prototypical instance.) This lack of multi-turn planning could trigger fashions to undergo from process ambiguity [6] and studying superficial human-likeness quite than goal-directed social interplay [7].
Will including extra dialogue information in RLHF assist? My guess is that it’ll, to a sure extent, however it’s going to nonetheless fall quick on account of a scarcity of function. Sergey Levine identified in his blog that there’s a basic distinction between desire studying and intentions: “the important thing distinction is between viewing language era as choosing goal-directed actions in a sequential course of, versus an issue of manufacturing outputs satisfying consumer preferences.”
Purposeful dialogue system
Staying on process is a modest request for LLMs. Nevertheless, even when an LLM stays centered on the duty, it would not essentially imply it may excel in reaching the objective.
The issue of long-horizon planning has attracted some consideration within the LLM neighborhood. For instance, “decision-oriented dialogue” is proposed as a basic class of duties [8], the place the AI assistant collaborates with people to assist them make sophisticated choices, corresponding to planning itineraries in a metropolis and negotiating journey plans amongst associates. One other instance, Sotopia [10], is a complete social simulation platform that compiles numerous goal-driven dialogue situations together with collaboration, negotiation, and persuasion.
Organising such benchmarks gives not solely a approach to gauge the progress of the sphere, it additionally instantly gives reward alerts that new algorithms may pursue, which could possibly be costly to gather and tough to outline [9]. Nevertheless, there aren’t many strategies that may exert management over the LM in order that it may act constantly throughout an extended horizon in direction of such objectives.
To fill on this hole, my collaborators and I suggest a light-weight algorithm (Dialogue Motion Tokens, DAT [11]) that guides an LM chatbot by way of a multi-round goal-driven dialogue. As proven within the picture beneath, in every spherical of conversations, the dialogue historical past’s final token embedding is used because the enter (state) to a planner (actor) which predicts a number of prefix tokens (actions) to manage the era course of. By coaching the planner with a comparatively steady RL algorithm TD3+BC, we present vital enchancment over baselines on Sotopia, even surpassing the social functionality scores of GPT-4.

On this method, we offer a way pathway that upgrades LM from a prediction mannequin that merely guesses the following token to at least one that engages in dialogue with people purposefully. We may think about that this method could be misused for dangerous purposes as properly. For that reason, we additionally conduct a “multi-round red-teaming” experiment, and suggest that extra analysis could possibly be completed right here to raised perceive multi-round dialogue as potential assault floor.
Concluding marks
I’ve reviewed the making of present LLM dialogue programs, how and why it’s inadequate. I hypothesize {that a} function is what’s lacking and current one approach so as to add it again with reinforcement studying.
The next are two analysis questions that I’m principally enthusiastic about:
(1) Higher monitoring and management of dialogue programs with steering strategies. For instance, the just lately proposed TalkTurner (Chen et al.) provides a dashboard (Viéfuel et al) to open-sourced LLMs, enabling customers to see and management how LLM thinks of themselves. Many weaknesses of present steering strategies are revealed and name for higher options. For instance, utilizing activation steering to manage two attributes (e.g., age and schooling stage) concurrently has been discovered to be troublesome and may trigger extra language degradation. One other intriguing query is easy methods to differentiate between LLM’s inside mannequin of itself and that of the consumer. Anecdotally, chatting with Golden Gate Bridge Claude has proven that steering on the particular Golden Gate Bridge function discovered by SAE generally causes Claude to think about itself because the San Francisco landmark, generally the customers because the bridge, and different instances the subject as such.
(2) Higher utilization of off-line reward alerts. Within the case of set-up environments like Sotopia and “decision-oriented dialogues”, rewards alerts are engineered beforehand. In the true world, customers gained’t depart numerical suggestions of how they really feel glad. Nevertheless, there is perhaps different clues in language (e.g., “Thanks!”, “That’s very useful!”) or from exterior sources (e.g., customers shopping for the product for a salesman AI, customers transfer to a subsequent coding query for copilot inside a short while body). Inferring and using such hidden reward alerts may strengthen the network effect of on-line chatbots: good mannequin → extra customers → studying from interacting with customers → higher mannequin.
Acknowledgment
The creator is grateful to Martin Wattenberg and Hugh Zhang (alphabetical order) for offering recommendations and enhancing the textual content.
Quotation
For attribution of this in tutorial contexts or books, please cite this work as:
Kenneth Li, “What’s Lacking From LLM Chatbots: A Sense of Objective“, The Gradient, 2024.
BibTeX quotation (this weblog):
💡
@article{li2024from,
creator = {Li, Kenneth},
title = {What’s Lacking From LLM Chatbots: A Sense of Objective},
journal = {The Gradient},
yr = {2024},
howpublished = {url{https://thegradient.pub/dialogue}},
}
References
[1] Schank, Roger C., and Robert P. Abelson. Scripts, plans, objectives, and understanding: An inquiry into human data constructions. Psychology press, 2013.
[2] Zhou, Jeffrey, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. “Instruction-following analysis for giant language fashions.” arXiv preprint arXiv:2311.07911 (2023).
[3] Li, Kenneth, Tianle Liu, Naomi Bashkansky, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. “Measuring and controlling persona drift in language mannequin dialogs.” arXiv preprint arXiv:2402.10962 (2024).
[4] Andreas, Jacob. “Language fashions as agent fashions.” arXiv preprint arXiv:2212.01681 (2022).
[5] Austin, John Langshaw. do issues with phrases. Harvard college press, 1975.
[6] Tamkin, Alex, Kunal Handa, Avash Shrestha, and Noah Goodman. “Process ambiguity in people and language fashions.” arXiv preprint arXiv:2212.10711 (2022).
[7] Bianchi, Federico, Patrick John Chia, Mert Yuksekgonul, Jacopo Tagliabue, Dan Jurafsky, and James Zou. “How properly can llms negotiate? negotiationarena platform and evaluation.” arXiv preprint arXiv:2402.05863 (2024).
[8] Lin, Jessy, Nicholas Tomlin, Jacob Andreas, and Jason Eisner. “Determination-oriented dialogue for human-ai collaboration.” arXiv preprint arXiv:2305.20076 (2023).
[9] Kwon, Minae, Sang Michael Xie, Kalesha Bullard, and Dorsa Sadigh. “Reward design with language fashions.” arXiv preprint arXiv:2303.00001 (2023).
[10] Zhou, Xuhui, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency et al. “Sotopia: Interactive analysis for social intelligence in language brokers.” arXiv preprint arXiv:2310.11667 (2023).
[11] Li, Kenneth, Yiming Wang, Fernanda Viégas, and Martin Wattenberg. “Dialogue Motion Tokens: Steering Language Fashions in Aim-Directed Dialogue with a Multi-Flip Planner.” arXiv preprint arXiv:2406.11978 (2024).
[12] Li, Shiyang, Jun Yan, Hai Wang, Zheng Tang, Xiang Ren, Vijay Srinivasan, and Hongxia Jin. “Instruction-following analysis by way of verbalizer manipulation.” arXiv preprint arXiv:2307.10558 (2023).
[13] Wu, Zhaofeng, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. “Reasoning or reciting? exploring the capabilities and limitations of language fashions by way of counterfactual duties.” arXiv preprint arXiv:2307.02477 (2023).
Source link
#Whats #Lacking #LLM #Chatbots #Sense #Objective
Unlock the potential of cutting-edge AI options with our complete choices. As a number one supplier within the AI panorama, we harness the ability of synthetic intelligence to revolutionize industries. From machine studying and information analytics to pure language processing and pc imaginative and prescient, our AI options are designed to boost effectivity and drive innovation. Discover the limitless potentialities of AI-driven insights and automation that propel your corporation ahead. With a dedication to staying on the forefront of the quickly evolving AI market, we ship tailor-made options that meet your particular wants. Be a part of us on the forefront of technological development, and let AI redefine the best way you use and achieve a aggressive panorama. Embrace the long run with AI excellence, the place potentialities are limitless, and competitors is surpassed.





: Bose, Shokz, JLab")




{kind=link}